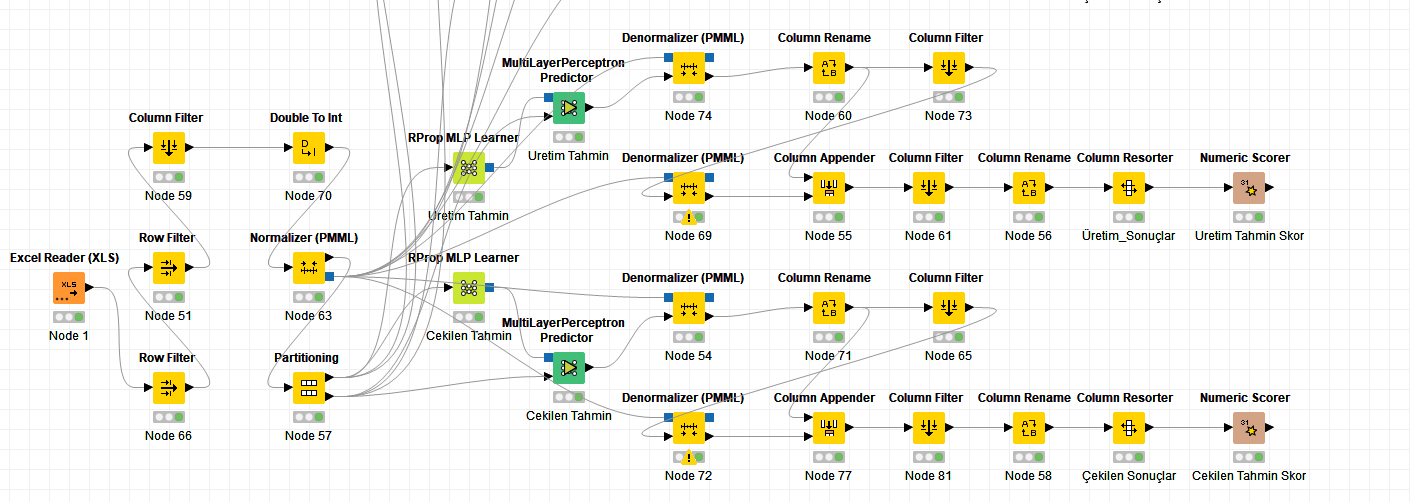
Is there anyone who can help? my only hope is this forum
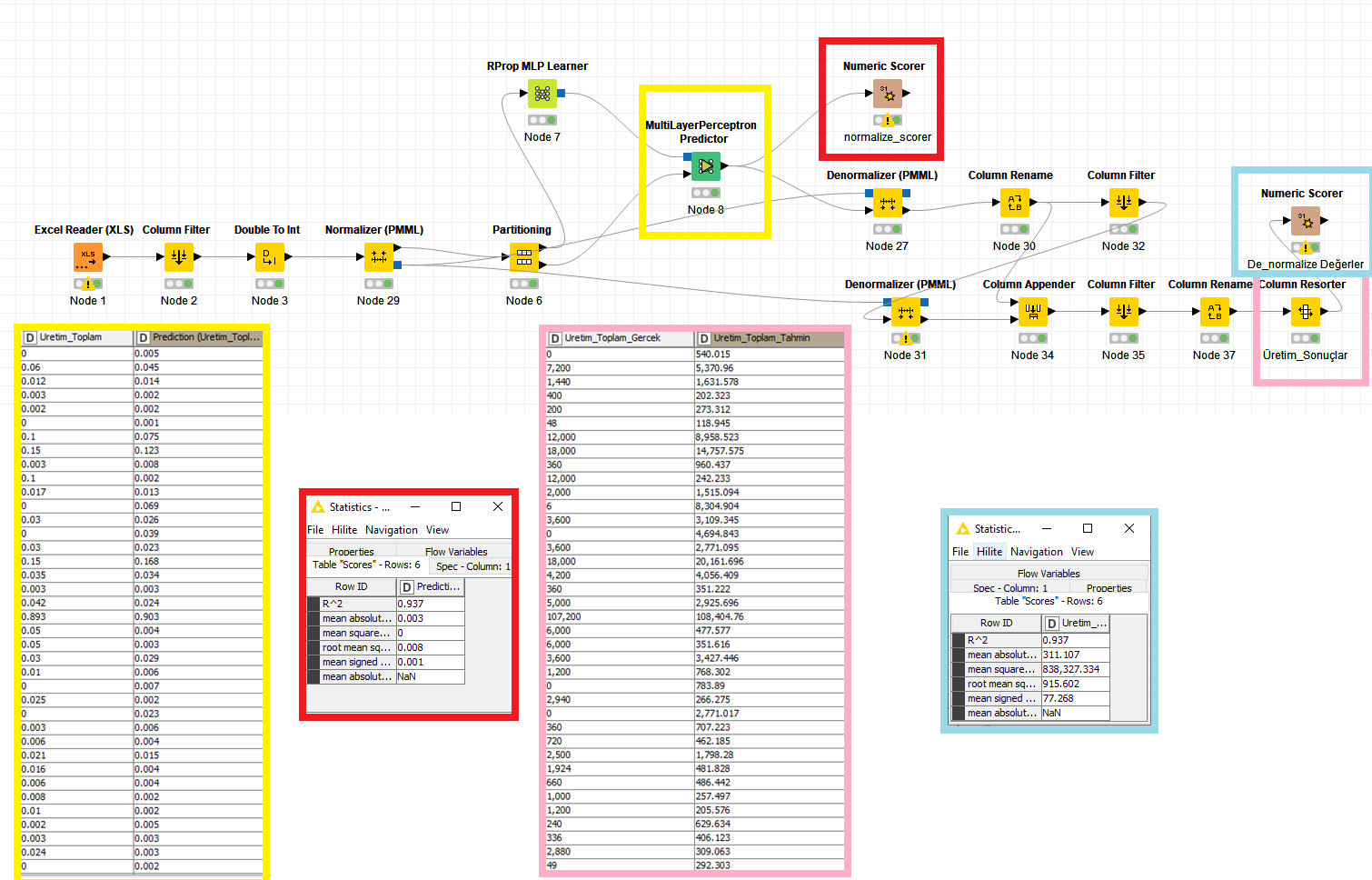
My forecast values in the yellow area are very close and the success and error rate in the red area is good.
The error rate in the blue area is incredibly high. The predictive values are good and the score is very bad. I want to use or close to the error rate in the red area.
Frankly, I want to reduce the error rate in my program. 2 weeks left to deliver and I still couldn’t.
Hi,
your error rates in the red square are only good because the data has been normalized before learning and predicting. The R^2 metric, which shows the explained variance in your data, is exactly the same. If you want lower errors, you need to find a good model type and good features. Other people spend 80% of their project on that alone, so I am not sure anyone here can help you with that, because they do not know anything about your project. Maybe it is just not possible to infer a better model from the data you have. There is noise and other factors that may play a role.
Kind regards,
Alexander
Like @AlexanderFillbrunn said it is because of the normalisation and especially the structure of the two values
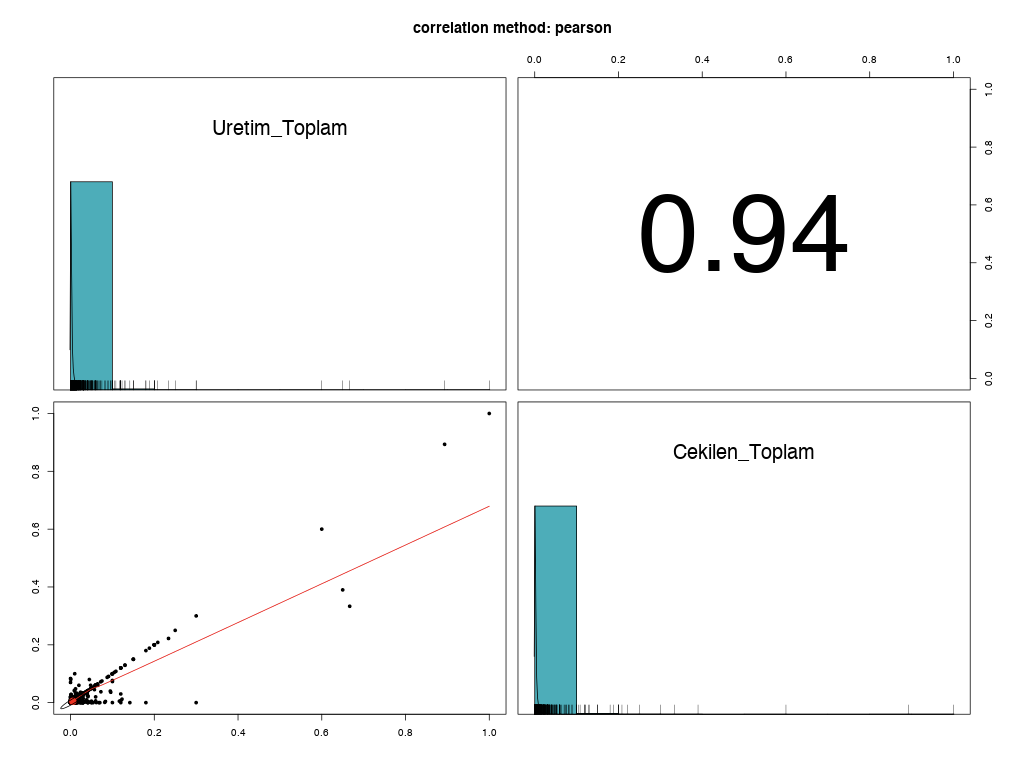
Uretim_Toplam
Cekilen_Toplam
They have a lot of very low numbers and some are very high. And they are highly correlated (Pearson 0.94) but their connection is not immediately clear so it might be challenging to actually derive one from the other (one would have to know more about what they say).
As mentioned before if you use H2O automl and take a look at the variable importance Cekilen_Toplam takes a lot of the ‘explaining’ power of the whole model and the RMSE is along the numbers you are seeing in your MLP model. Some tweaking might improve it further.
You would have to think about what you want to do with these numbers and think about how they come about and what their relationship is. There are several things you could explore but that might depend on your task:
try to use logarithm on the data in order to smooth the curve, but that is not easy to handle if you want to get precise data back
exclude the high numbers and think about doing two models for high and low values (if you would deploy such a model you would then have to decide which to use when)
further tweaking of the numbers and employing feature engineering methods (vtreat, featuretools) - but as long as it is not clear what is going on with the Target and Cekilen_Toplam this might also be misleading
why have you excluded some other variables from the model? Might they hold some information that might be helpful?
in Partitioning you choose linear sampling. Was this a deliberate decision?
I do not think that there is a purely ‘automatic’ model voodoo solution to your problem. If you would tell us more about your project and your assignment we might come up with new ideas.
Also you might want to consider if just copying something from the internet will be sufficient for your task or you would then have to explain what you were doing and answering specific questions.
Building a model in two weeks is challenging but it is also doable. I think you will have to come up with an idea what a ‘minimum viable product’ might be. From my experience it might sometimes be better to ask for an extension then to try to just patch something together.
For example, I want to set limits for success rate and error rate. It will repeat until it reaches the limit. Can there be a function that will generate random value within the Learner section?
For example, I want to set limits for success rate and error rate. It will repeat until it reaches the limit. Can there be a function that will generate random value within the Learner section?
Maybe the parameter optimization loop is what you are looking for?
You can use it to test many different combinatons of your ML parameters and later take the one with the best results