Hello,
I need a system that can retrieve, learn and predict data from a table in Excel. I’ve been dealing for 1 year but I couldn’t. I bought a lot of books but it was insufficient. I have to deliver 2 weeks later, otherwise I will not be able to graduate. Can you help me please?
Hi @yesiloglua,
I doubt anyone here will be willing to do your project for you, but feel free to ask specific questions. What exactly is your plan? What is your progress to date?
Kind regards,
Alexander
5 Likes
16052021 (1).knwf (551.4 KB)
My work is trying to guess these entered values but I couldn’t. I tried to show the value he had predicted and I couldn’t do it. @AlexanderFillbrunn
Hi,
I don’t understand your problem. You are training to predict the column “Uretim_Toplam” and then apply the predictor on the test set. Your R^2 is 0.86, which seems quite ok. What is your question?
Kind regards,
Alexander
1 Like
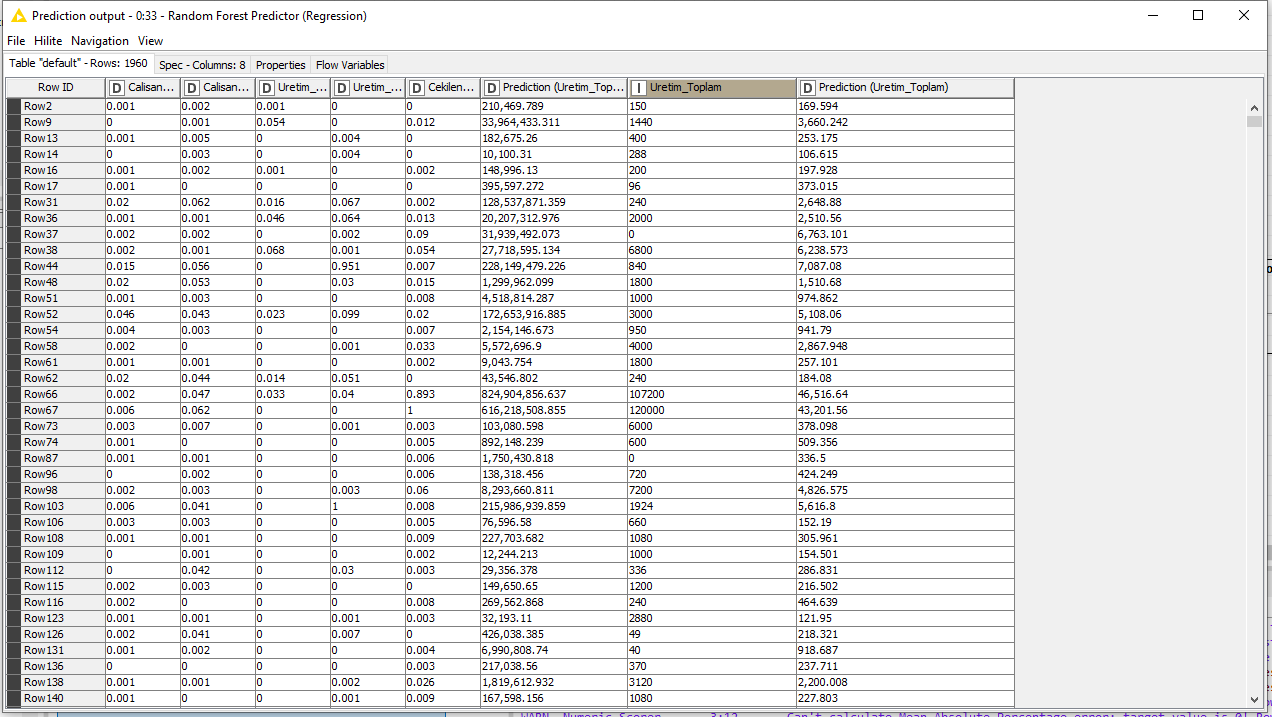
I want to see the values that my problem predicts. For example, if the Uretim_Toplam is 48, is the estimated value 52?
I want to see the original, not 0.001.
@AlexanderFillbrunn
I hope you understand my problem. it’s actually very simple but I can’t. I want to see the real values that the program predicts based on the percentage given. I want to see an estimate of the data in the Uretim_toplam table.
Hi,
let’s keep this in the forum and I would not share my phone number publicly if I were you, this is why I removed it from your post. The MLP node is a classification node, but you try to predict a double value. For this you need a regression node. I have replaced it with a Random Forest (Regression) setup and removed the normalization, because you do not need it here. This solves your problem here.
Kind regards,
Alexander
16052021.knwf (18.6 KB)
3 Likes
04.01.2020.xlsx (363.8 KB) 16052021.knwf (18.6 KB) I think the problem is solved but the values are not close to each other. How can I increase the success percentage? I want to bring the values closer together. How can I make progress? I have a lot of debt on you, which I do know, please, thank you very much.
@AlexanderFillbrunn
thank you for your endless support.
Hi,
This is unfortunately a complex process to find out. You can try out different regression algorithms, engineer more features, tweak the hyperparameters like the number of trees in the random forest, etc. But that requires quite some time.
Kind regards,
Alexander
1 Like
You could try and use H2O.ai’s automated-machine-learning for regression problems (or a H2O node from KNIME’s repository) and see if this comes up with better results or does give you an idea where to look further. Since this seems to be an assignment you would have to check what is your contribution to your work (that would depend on your original task).
Another typically powerful tool would be the regression nodes from:
5 Likes
I have been able to do this until now, but can you support me to correct these forecasting results incorrectly?
Test1.knwf 1.knwf (651.3 KB)
Hello friends,
I did a nice workflow, but I have a very high error rate. I want to see the Uretim_Toplam and Total and Prediction values close together. Is there anyone who can show or correct mistakes? This knime project is my finishing project.
@HansS @AlexanderFillbrunn @AJABLR @lug @ipazin @datascience100 @stelfrich @rabenschlag @elsamuel
Test1.knwf 1.knwf (651.3 KB)
Hello friends,
I did a nice workflow, but I have a very high error rate. I want to see the Uretim_Toplam and Total and Prediction values close together. Is there anyone who can show or correct mistakes? This knime project is my finishing project.
@sgilmour @izaychik63 @mlauber71 @Rich_ard @armingrudd @ScottF
@umutcankurt hocammmm türk buldum nolur yardımcı oluver
Dear @yesiloglua,
As @AlexanderFillbrunn has already pointed out, we are happy to help you with specific questions that you might have with respect to KNIME Analytics Platform. I would assume that improving the accuracy (or any other metric) of your predictor is at the center of your task/assignment and has nothing to do with a specific implementation in any software.
Please refrain from mentioning specific people who have not been involved in this or any other discussion around this topic. Thank you!
Best regards,
Stefan
4 Likes
Hi; @stelfrich For me, the problem is no problem, just because we were in the same country, she only asked for help.
Hi; @yesiloglua
friends in the forum are very knowledgeable people. And be sure they are people who are happy to help everyone. I think you have very little time to graduate, but I never worked on the subject you mentioned, and I worked on data mining. For this reason, if you write the problem you are experiencing in a detailed and exemplary way, they will definitely help you. I’m sorry I couldn’t help you with this.
1 Like
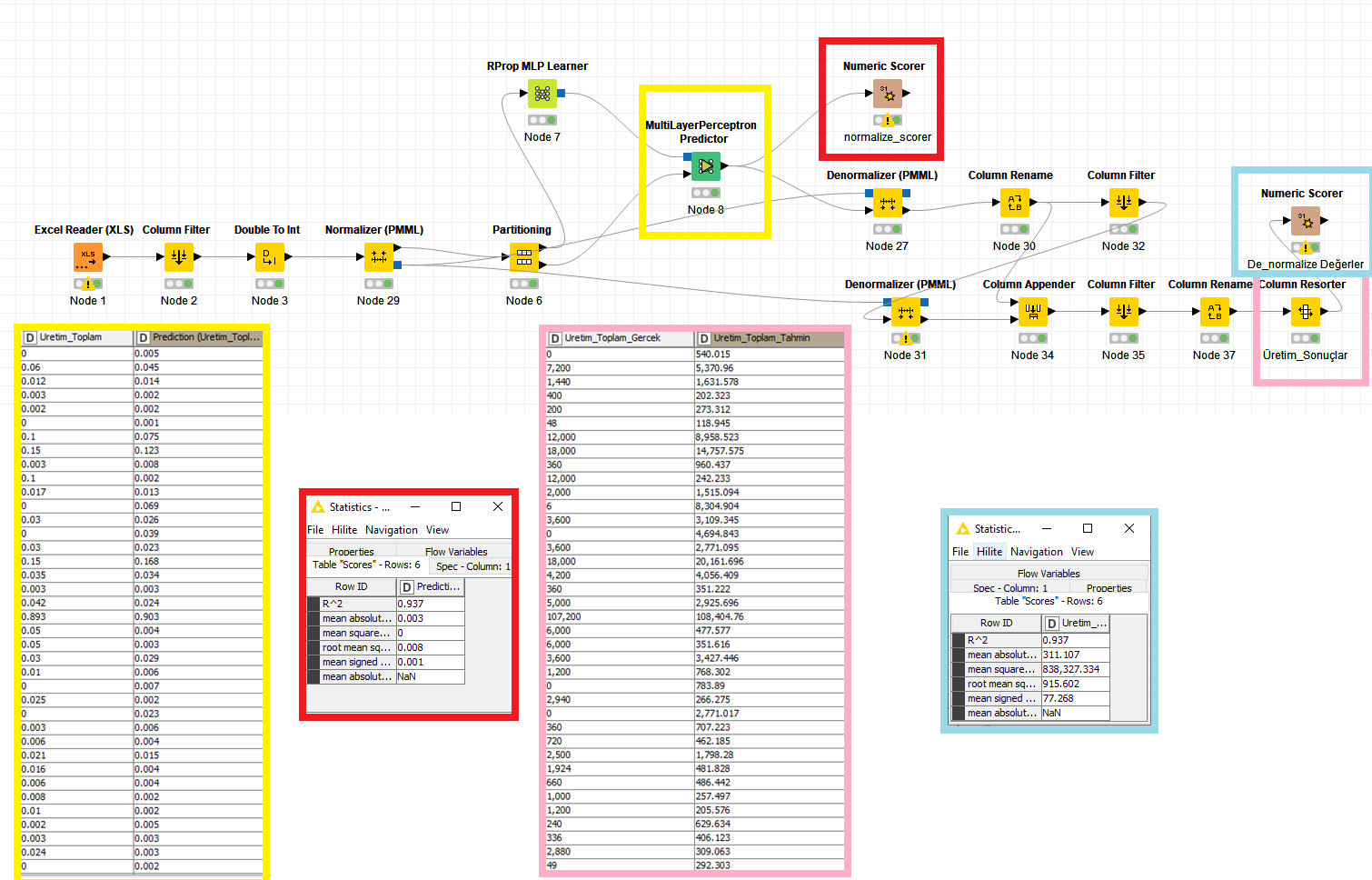
My forecast values in the yellow area are very close and the success and error rate in the red area is good.
The error rate in the blue area is incredibly high. The predictive values are good and the score is very bad. I want to use or close to the error rate in the red area.
Frankly, I want to reduce the error rate in my program. 2 weeks left to deliver and I still couldn’t. So I tagged everyone to ask for urgent help. I’m sorry.
Maybe you could try and take 15 minutes to describe your task and what your specific question is.
BTW: the values Uretim_Toplam and Cekilen_Toplam seem to be very closely related. Question is if this is OK if you try to predict one following the other. Cekilen_Toplam takes abot 1/3 of the ‘explaining’ power if you use H2O models.
What is the metric you are trying to maximise, In regression questions often RMSE is used. Can you tell us which is your metric. And is this the only metric you have.
And you have very few values that are very high and a lot of others that are lower. You use normalization. If you have such large discrepancies you might have to use Z-Score transformation or log() (be careful how to handel 0 values).
4 Likes
Do you have a chance to help me? Seriously, I don’t master the program and I can’t do more, that is, what you say. I searched but did not.