I built a workflow to analyze and visualize my personal expenses. The workflow does the following in order of execution:
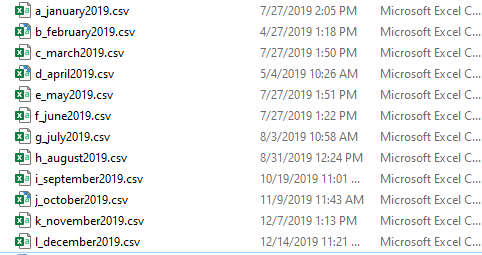
Reads monthly bank statements as csv’s ordered alphabetically so that time order is preserved:
[Figure 1]
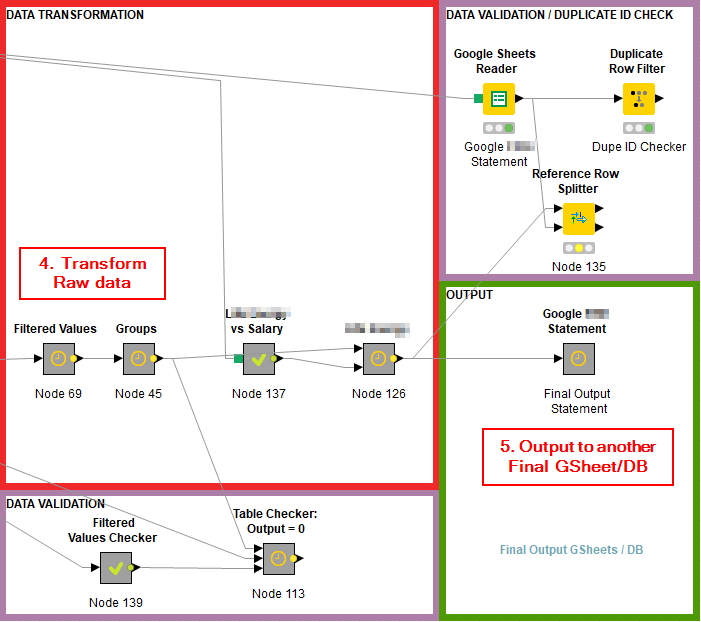
Loop combines the monthly statements (2) and compares it to an existing Google Sheet (1) that serves as a makeshift database to store all of the raw bank data. If the current month’s csv (i.e., ‘l_december2019.csv’) contains any new entries, a Reference Row Splitter node is used to compare and update the same raw GSheet with the new data (3).
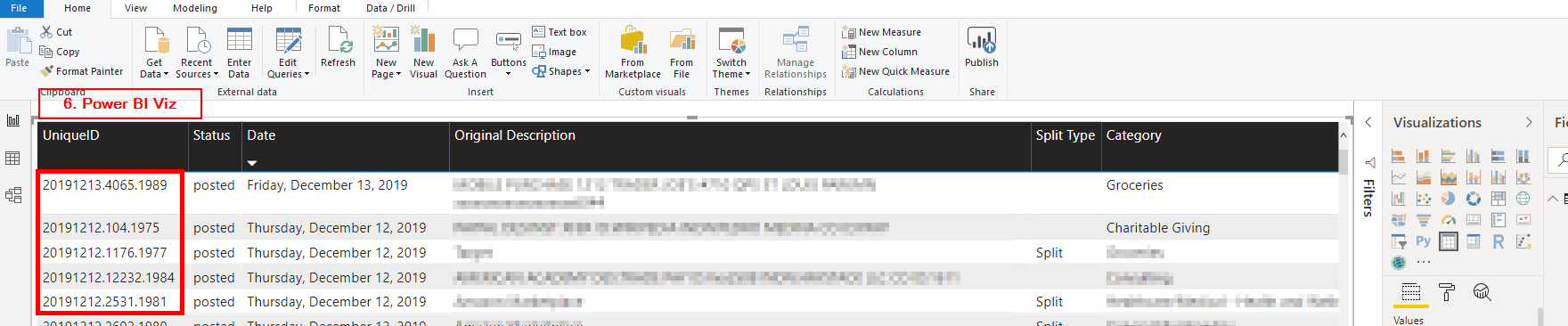
Finally, the workflow transforms the raw data (4), and updates a separate GSheet that serves as the final database (5). I then connect this GSheet to Power BI for visualization (6).
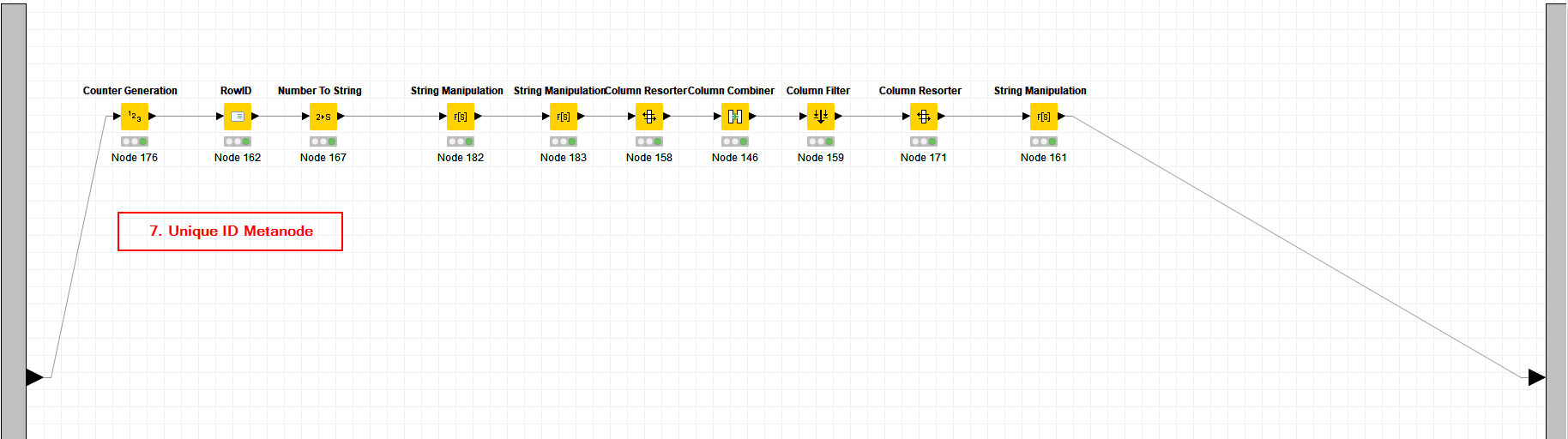
For the Unique ID, I use a Counter Generation Node to sequentially add ‘1’ to each row from the loop, then I concatenate with the date and “stripped” value of the expense. For example, I spent $40.65 on Groceries on 12/13/2019, and it appears on row #1989 (see Figure 4). This gave a unique ID = “20191213.4065.1989.” This is the best combination of available data to create a unique id I could come up with.
Everything works great, but I have two questions: 1) I don’t know if there is a better way to create a persistent Unique ID that remains persistent (e.g. stays unique and is not overwritten) when the GSheets get updated, 2) I would like to know if there is a better way of doing this? (e.g., use SQLite instead of GSheets, better loop, cleaner logic, etc.).
I am still fairly new to KNIME and am not sure if I am using best database practices when creating unique id’s, db’s, and building a workflow that I can use for personal finance for many years to come. I appreciate any feedback or suggestions you can share.
First: I think it is great to use KNIME in such a way. The software is very flexible and versatile and has been around for some time. Also, the KNIME team makes sure older workflows can still be run on newer versions of the software.
About your questions.
IDs and unique IDS are always a challenge. You could store a unique ID somewhere and always draw from the stored file to take the latest number. I like the idea of combining it with the date and amount (although there might be a chance that that could change I think about the way KNIME does organize its forum-ids. Eg. this thread has the number 20055 which appears in the URL along with the name. That will enable KNIME to reference this post even if the name were about to change.
I know of two simple standalone databases that do not require any fancy drivers (just what KNIME has to offer). SQLite and H2. I have some experience with SQLite and have used it several times and think it is a robust DB although a little bit restrained in its SQL capabilities but more than enough for such use. You could also store some basic table for reports in the same file. From my experience, SQLite is quite robust and can be accessed and manipulated with the DB nodes of KNIME.
And there are drivers for major programming packages like R and Python so you will be able to access your databases later (but as always backup and versioning are strongly recommended). And you may always keep your CSV file so you might be able to reproduce your reports.
I have demonstrated a way to import many CSV files that have the same structure in one step without the need to loop thru them by using KNIME’s local Big Data environment and an external Hive table. That does work but has some downsides which are discussed in the workflow.
If you track in a separate table which CSV files you have already loaded you might just use the increment.
If you ever need to deal with duplicates you could use SQL’s DISTINCT command. Or you could check out the solution in KNIME discussed extensively in this thread *1)
Thank you for your reply and suggested solutions! I like your idea of creating a separate db of unique ids and/or creating a unique index in SQLite.
My main concern with my current method is that a purchase for an identical amount can occur on any given day so date+amount is not unique. Furthermore, the rowid that results from the loop can change if the underlying data is changed in any way. Therefore, I think creating a multi-column unique index in SQLite and then pushing this data directly to Power BI using the new Publish to Power BI node might be the best way to go.
Dumb question: I tried ordering the CSVs numerically, but the order gets broken after the 10th entry. For example: 1_january is immediately followed by 11_november and not 2_february. Why does this happen?