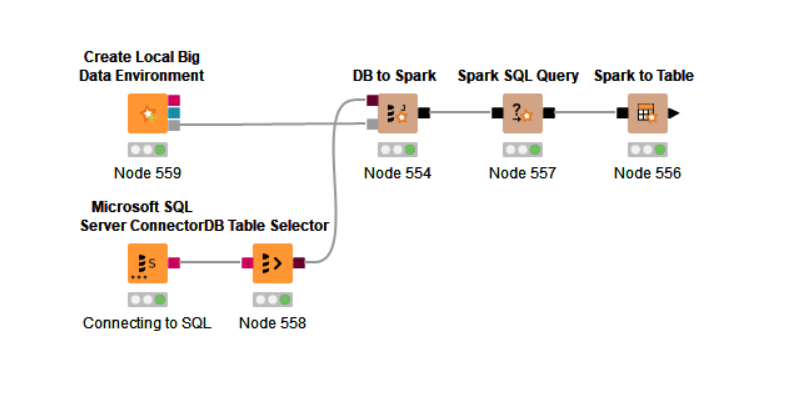
Hello KNIME Community,
I am relatively new to using Spark and need some guidance on optimizing my data loading process. I have an on-premise SQL Server database, and I am trying to use Spark to load data faster. Here is what I have done so far:
- I created the data environment using Spark.
- Connected Spark to my SQL Server database.
However, I have noticed that the running time for loading data remains the same, whether I use Spark or not. Additionally, when dealing with large datasets, I sometimes encounter deadlock errors.
I would appreciate any advice on how to use Spark more effectively to load data faster from my SQL Server. Specifically, I am looking for:
- Best practices for optimizing Spark for data loading.
- Any specific configurations or settings in Spark that could help reduce the running time.
- Strategies to avoid deadlock errors when handling large datasets.
I have attached a screenshot of my workflow for your reference.
Thank you in advance for your assistance!