I have tried the few lines but they do not make that much sense and for the Weka nodes I had in mind they do not have the right format. So I used an older example I had from a Kaggle DS. It is just for illustration the values do not make much sense with regards to a sequence.
These basic differences
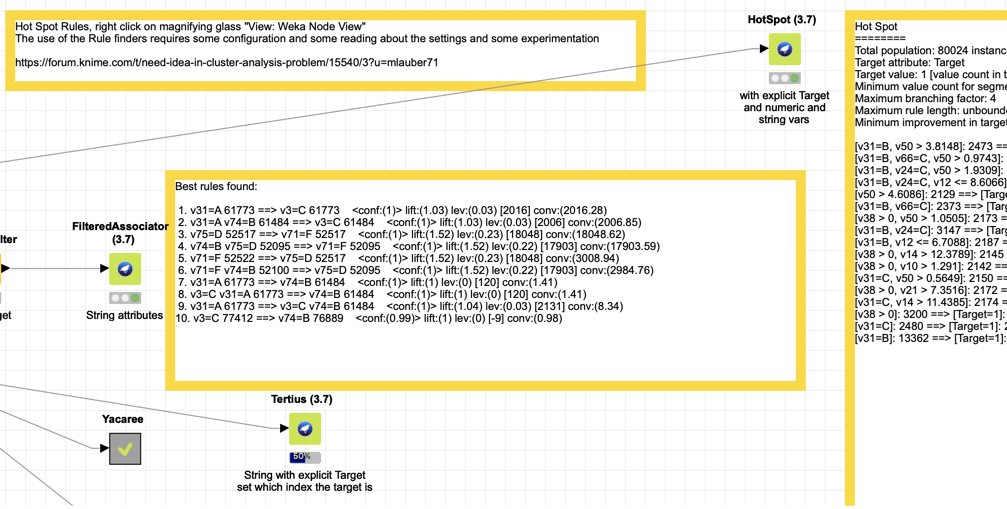
Weka HotSpot can deal with strings and numbers and would accept a Target (in your case if you want to differentiate between Errors and Non-Errors). This might potentially handle your duration values.
Tertius would work with strings and you could or could not set a class (Target).
GeneralizedSequentialPatterns allows to specify a sequencing ID, you might be able to use your data structure with the event_id
PredictiveApriori and FilteredAssociator are additional methods; please read about their capabilities I am not an expert in that regard.
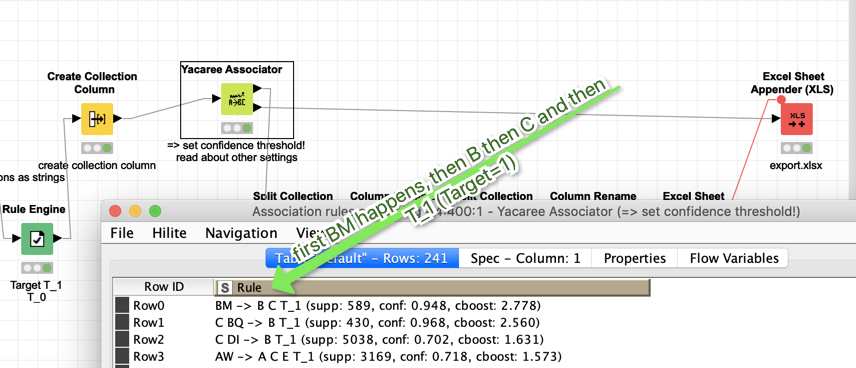
Yacaree is special in two regards: it does not use the variables with the Var-Name and then the value but just the sequence of values that have to stand for themselves, and it considerers sequences before and after - from a few experiments it might be that it is influenced by the different number of events that might lead to an Error; could be it works best with a fixed set of sequences
All this nodes have quite some possibilities to configure them; typically some threshold for confidence (reliability of the rule), some minimum coverage (a rule only applying to a small set might be skipped). Please read about the implications and bring them together with your data. Toy around with them and gain experience.
From my perspective these nodes could help you to gain more insights; they are not a magical tool to answer all your questions ![]() but more a starting point.
but more a starting point.
Yacaree might look something like this:
Maybe someone with more experience in Rulesets can weight in. And you might provide us with a larger sample to have something that is actually interpretable. Also maybe someone can provide a useful example data set to toy around with.
Please also note. These nodes might need quite some calculation power especially if you have large data sets.
m_120_weka_hotspot_and_yacaree_rules.knwf (780.8 KB)
–
Edit: “Rule Induction” KNIME — Machine Learning and Artificial Intelligence — A Collection | by Markus Lauber | Low Code for Data Science | Medium