We have just released a major update to the @Vernalis community contribution.
This update adds 13 new nodes for working with Binary Objects (“BLOB”) cells:
Binary Objects Properties - determines simple binary object
properties (size, and whether is in memory)
Base64-Encoded String to Binary Objects - Converts Base64-encoded
strings to binary objects
Binary Objects to Base64-Encoded String - Converts binary objects to
Base64-encoded strings
Binary Objects Message Digest (Checksum) - Calculates digests (hash,
checksum - e.g. MD5, SHA-1 etc) of binary objects
Archive Binary Objects - Combines binary objects into an archive
(e.g. Tar, Zip etc; some with compression) binary object within the
KNIME table
Compress Binary Objects - Compresses binary objects within the table
(e.g. gzip, bzip2 etc)
Decompress Binary Objects - Decompresses binary objects with the
table (e.g. gzip, bzip2 etc)
Detect Binary Objects Archive Formats - Detects the archive
format(s) of binary objects within the table
Detect Binary Objects Compression Formats - Detects the compression
format(s) of binary objects within the table
Expand Binary Objects Archives - Expands (and decompresses if
applicable) binary objects archive cells within the table, with each
entry becoming a new row
List Binary Objects Archive Contents - Lists the entries in binary
objects within the table
List Binary Objects Archive Formats - Lists the available archiving
formats and capabilities on the current system
List Binary Objects Compression Formats - Lists the available
compression formats and capabilities on the current system
In addition, our original GZip and Zip compress/decompress nodes are moved into the new plugin with these nodes. All existing workflows should continue to work, but the (de)compress / archive nodes offer more functionality and should be used going forwards.
I resumed my work on the workflow where I process a stash of emaills with DMARC Report attachments. I noticed that the “Detect Binary Objects Compression Formats” node seems to be unable to identify zip attachments.
Mime Type
Compression Format (Body (Binary)) (Unique concatenate)
application/gzip
gzip
application/octet-stream
gzip
application/tlsrpt+gzip
gzip
application/zip
?
On the other hand, the “Detect Binary Objects Archive Formats” node detected it but not gzip.
Mime Type
Archive Format (Body (Binary)) (Unique concatenate)
application/gzip
?
application/octet-stream
?
application/tlsrpt+gzip
?
application/zip
zip
Guess I do not understand the difference between both nodes … or am I? In case you like to got access to the email stash, let me know.
That’s both to be expected! Zip is an archive format that usually also includes compression. Gzip is a compression-only format (although for further confusion, multiple files can be gzipped and simply appended one onto the end of another - the nodes should handled that too!). There’s a bit of detail about it at List of archive formats - Wikipedia
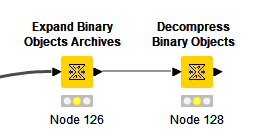
Probably your best way to handle is to try an expand archive followed by a decompress node, with both set to ‘guess’ for the format and then select the ‘Pass through’ option, which will pass through anything not detected as a recognised archive (or compression) format unchanged:
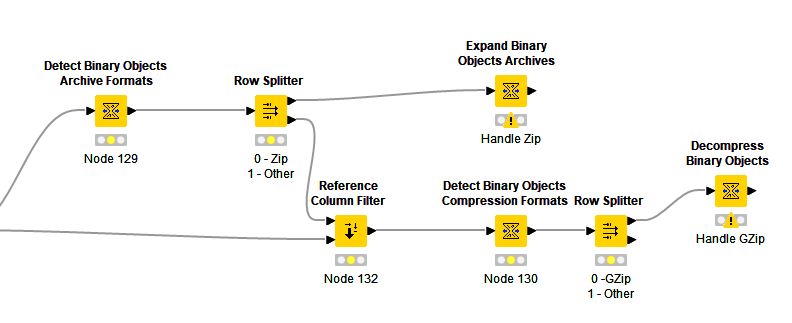
Either that, or check for archive formats, split the result and handle any that are found specifically (e.g. zip), and then check anything not found for compression and handle that specifically, e.g.
The first approach will be pretty generic - if you suddenly get e.g. a bzip2 compressed file instead it should “just work”, but the latter approach gives you more specific control for any format-specific expansion / decompression - as long as you handle manually each format you know that you will encounter
I’m sure in an ideal world the nodes wouldn’t care whether it was an archive or a compression format it was dealing with - definitely easier for the end user, but unfortunately, the underlying Apache commons compress library handles the two completely differently (Commons Compress – Overview)
No worries - it took me a while to figure too! (And as for that ‘Pass through’ option… that was a complete pain to implement, but really needed for an internal use case!)