Hi,
After the much needed Multicolumn Maths node, I would greatly appreciate a Multicolumn String Replacer node so that I don’t have string many String Replacer noses together or set up a loop.
It was also asked for back in 2011 with other users commenting on wanting this feature.
instead of multiple String Manipulation Nodes you could also use the new Column Expressions Node that provides all functions of the String Manipulation Node.
Edit: Sorry I misread the post. The thing you could do is to write your expression and copy it for all columns, which is somehow tedious but maybe a bit better than using several String Manipulation nodes.
What you can do to make it easier is to use your functions of a variable (say ‘col’) and in the first row assing ‘col’ the specified column. For example:
col = column(0)
capitalize(col)
Then you would have to change only the first line for each column, which pays of if you have a complex function reusing the same column over and over again.
You may have solved this already, but this sounds like a job for Column List Loop Start and its sidekick Loop End (Column Append). You could run the loop over the columns you want to check and use the currentColumnName flow variable to tell the string replacer which column to modify.
I have several thousand fixed width text files that I’ve been trying to combine. I have them all combined in knime, and I want to add them to a MySQL database. The trouble I run into is that the files retain the extra spaces at the end of each field and it creates lines that are too long to import as varchar. I could try other text field options, but I’d rather remove the extra space here.
So, I setup a loop with Column List Loop Start, then String Manipulation with stripEnd($${ScurrentColumnName}$$), and ended with the Loop End (Column Append) node.
The results are not stripping any white space, it takes a long time to run through the multi million row table, so testing has been slow. I’m looking at setting up a subset of data to test with, but thought I’d check here to see what I might be missing in the process.
A single string manipulation node on a single column gets me the results expected, but the loop doesn’t seem to actually do the work.
However, I’m wondering if this is really expected behavior? So it appears that the String Manipulation node, when inside a loop cannot use the column name variable for the “replace column” option, so in this case, I have to rename the column in the loop so that the string manipulation node is tied to the specifically named column?
I did a test with one of the files and it seems to be working, so I’m running it against the mass of files with fingers crossed. See you in several hours
you are right, one needs to rename the column in some way inside the loop iteration, if one uses String Manipulation. This can be done in the way as illustrated in the example that you shared. Or by stripping of the header and then adding it back.
Alternatively, you can use Column Expressions. Then you do not need to rename the column in the loop as you can access the column by index as suggested by Marten above.
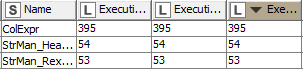
Note, however, that Column Expressions are very slow, so I would advice to stick to the remaning scenario, unless you need advanced logic in string manipulations. As an example of performance comparison, here is a basic benchmark (the values in the table are execution time in ms):
The corresponding workflow is available here:
A loopfree alternative is to Unpivot the table so that all strings are in a single column, perform the operation of that and then Pivot again. (yes I love the Unpivot/Pivot nodes )


 )
)