after training a dataset with random forest predictor, I want to deploy with a new dataset. (not from the 30% partitioning). I used the normalisation node for my trained data before partitioning. When I deploy my new dataset and connect it to the random forest predictor, do I need to normalise the new dataset as well?
Note; I used smote to train my data after partitioning it.
Hi,
if you train you model on normalized data you need to normalize the test data as well. It’s a bit tricky as you need to apply the same normallization model to the test data.
Therefore use the blue output of the “normalizer node” with “normalizer (apply)”
1 Like
I created a simple workflow as an example, could you explain whether option 1 or option 2 is the correct way to do it? And I am connecting a new dataset to the random forest predictor instead of using the test data to make prediction.
Option 1:
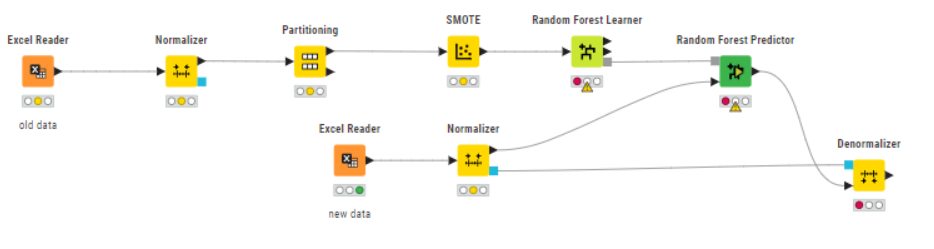
Option 2:
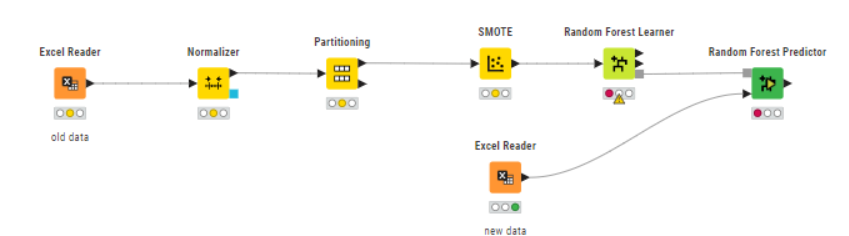
Why do you normalize RF training data at all? Did it give any benefit during evaluation? (I’d doubt that, but you never know).
1 Like
i normalised the dataset to use Smote to balance it out. Originally, the target variable was imbalance.
1 Like
If you read new data which is not normalized you need to apply the “normalizer model” from the normalizer node:

The random forest model is trained on normalized data and can therefore be only applied to normalized data.
3 Likes
Hi @lixingxing ,
in any case it is important to partition the data BEFORE you normalize. Otherwise you leak information from you test set into your training data. See this basic example:
3 Likes
But after doing so, do i have to normalise my new dataset as well? (its not the test data from partitioning, it a new one I use to make prediction)
1 Like
Got it - if it’s just the sampler which requires normalized data, how about denormalizing the data before training the Random Forest? This avoids the normalization step on the classification data altogether (incl. all other potential footguns, additional processing steps, dependence of normalized data of the learned model).
1 Like
Hi, I might be misunderstanding because i am very new. If i denormalise the data before training, does it mean feeding denormalised data to smote? Which i suppose should be wrong to do so
Hi, it seems like my data range is different, would it work the same way if I use option 1 and set the normalization as min-mix for both normalizers?
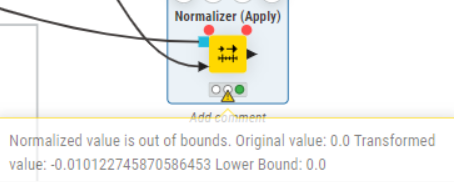
Hi, I might be misunderstanding because i am very new. If i denormalise the data before training, does it mean feeding denormalised data to smote? Which i suppose should be wrong to do so
I would try the following sequence:
- Normalizer
- Sampling (i.e. SMOTE)
- Denormalizer (which is the reverse of the normalization you performed before)
- Random Forest Learner
The classification data will not need to be normalized this way as the model was trained on the “original domain” data.
3 Likes
Hi! Thank you, this solve my issue.
Just want to ask if it is a must to normalize my data before Smote? I got a higher accuracy without normalizing it
1 Like
Hi @nan ,
are you sure? I think if the dataset is splitted before the normalization/standardization you can run into the problem, that the model must extrapolate or has to deal with features which are not in range of the training dataset.
And with maybe not a large dataset the split can lead to a change of the mean or standard deviation of a feature.
But I’m not an expert, maybe I’m wrong ![]()
1 Like
Hi, you basically exactly describe the problem. If you normalize before partitioning, in your example the mean is influenced by the data in the test set. Therefore the training knows something about the test set, which means that the test is not independent of the training anymore, which again means that it is not a good test.
In practice, if you sample randomly (and do not have bad luck) the mean should be similar in both, training and test set. However, as you also described each outlier/extreme value can only be in one of the two sets, which means the model needs to extrapolate. But that is also likely to happen later on when the model is deployed.
If you know that certain features can only appear in a certain range – say 1 through 10 – you can also use that information to normalize instead of “learning” the normalization from the training data.
That’s how I understand it, though I do not have a good source at hand right now.
Cheers,
nan
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.