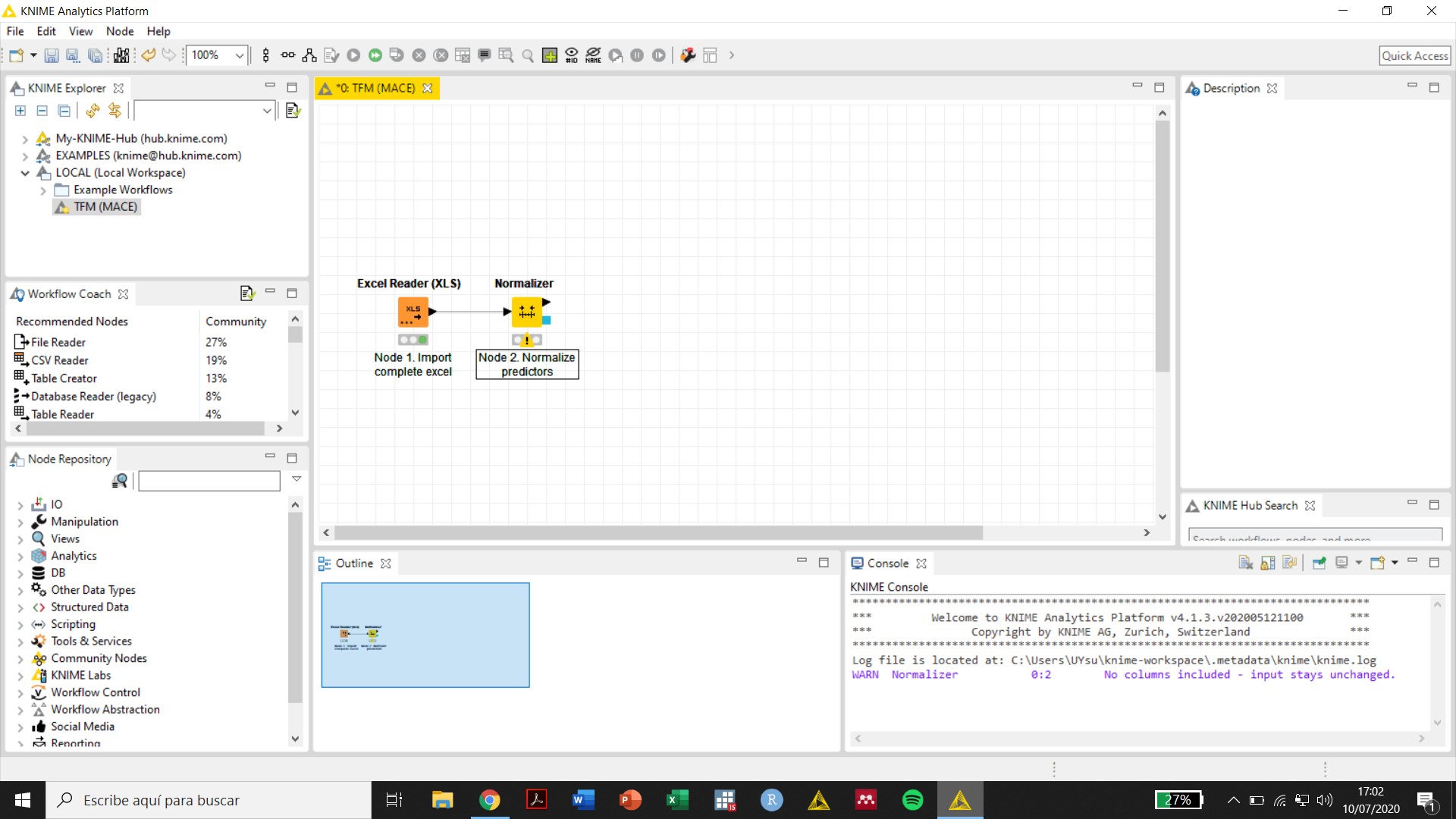
I am new to KNIME. I have imported an excel file with no problems and I want to normalize the predictors (n = 367) using the Normalizer node, but a warning signs appears in the node and no variables can be selected. Can you please provide some help?
My best guess is that the Normalizer node doesn’t see any numbers to work with because your columns are currently defined as strings. Can you check the configuration of your Excel Reader node, and make sure that you’re reading in the headers properly, and especially that your output fields in the preview pane are classified as numbers?
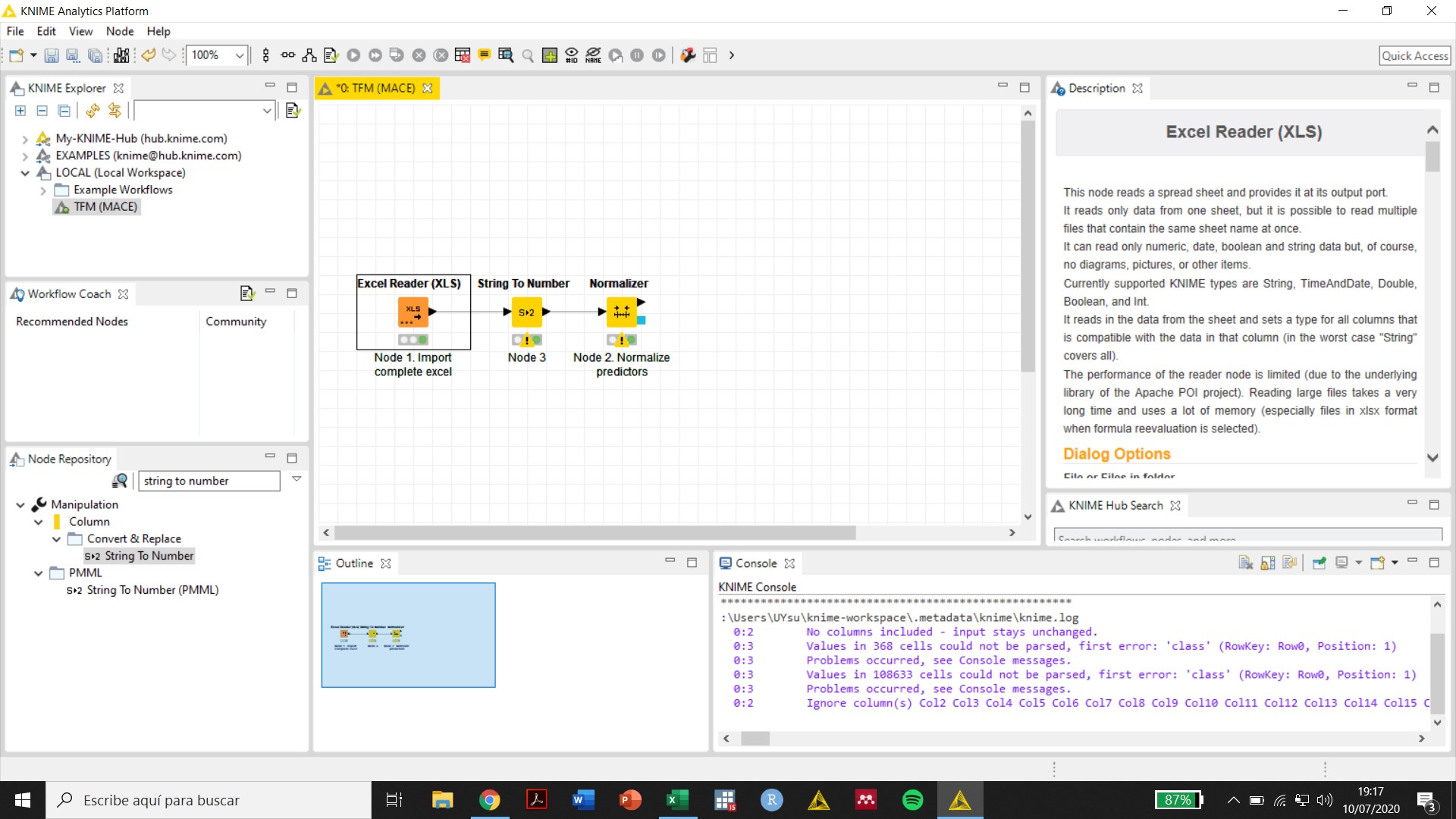
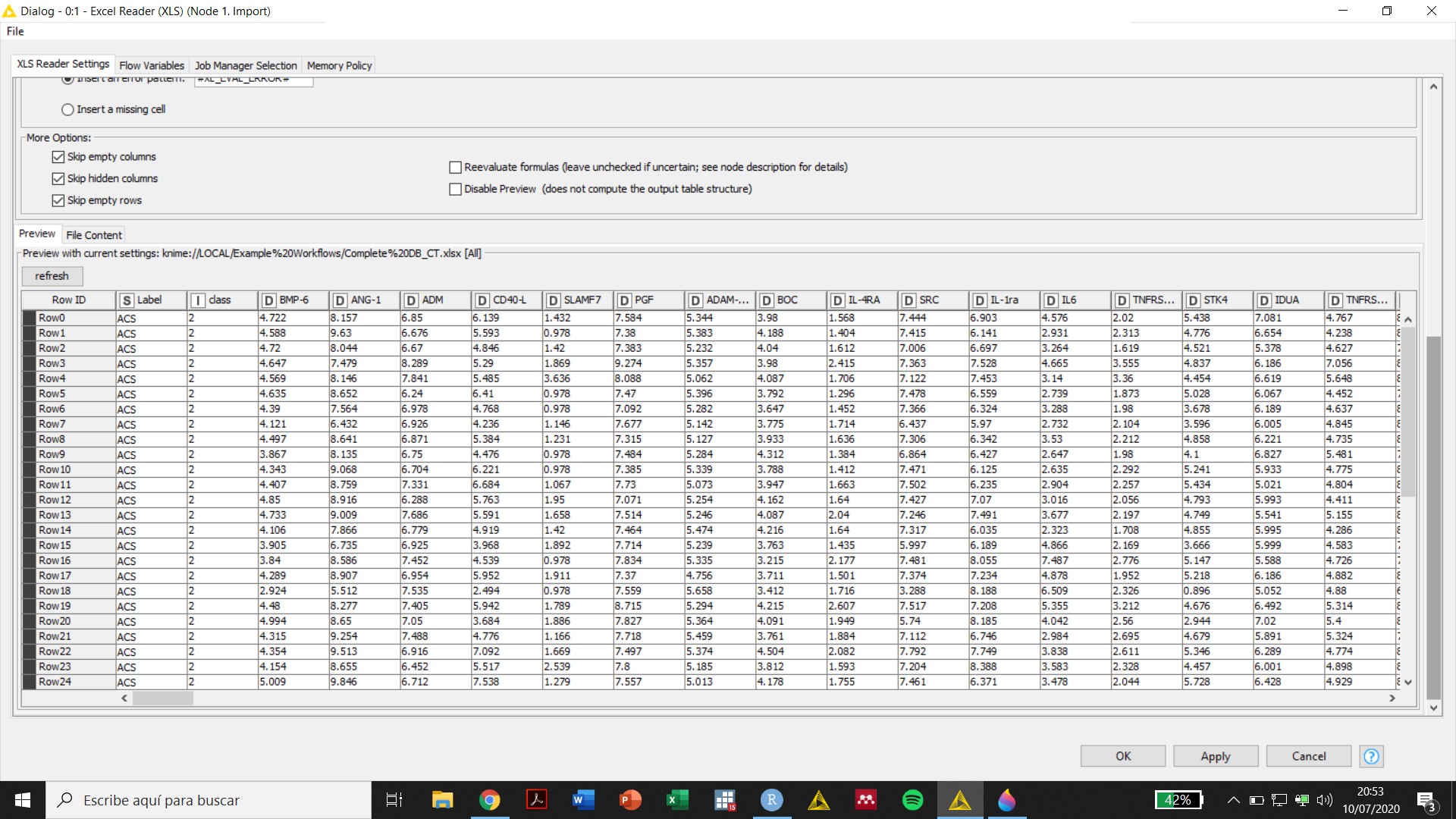
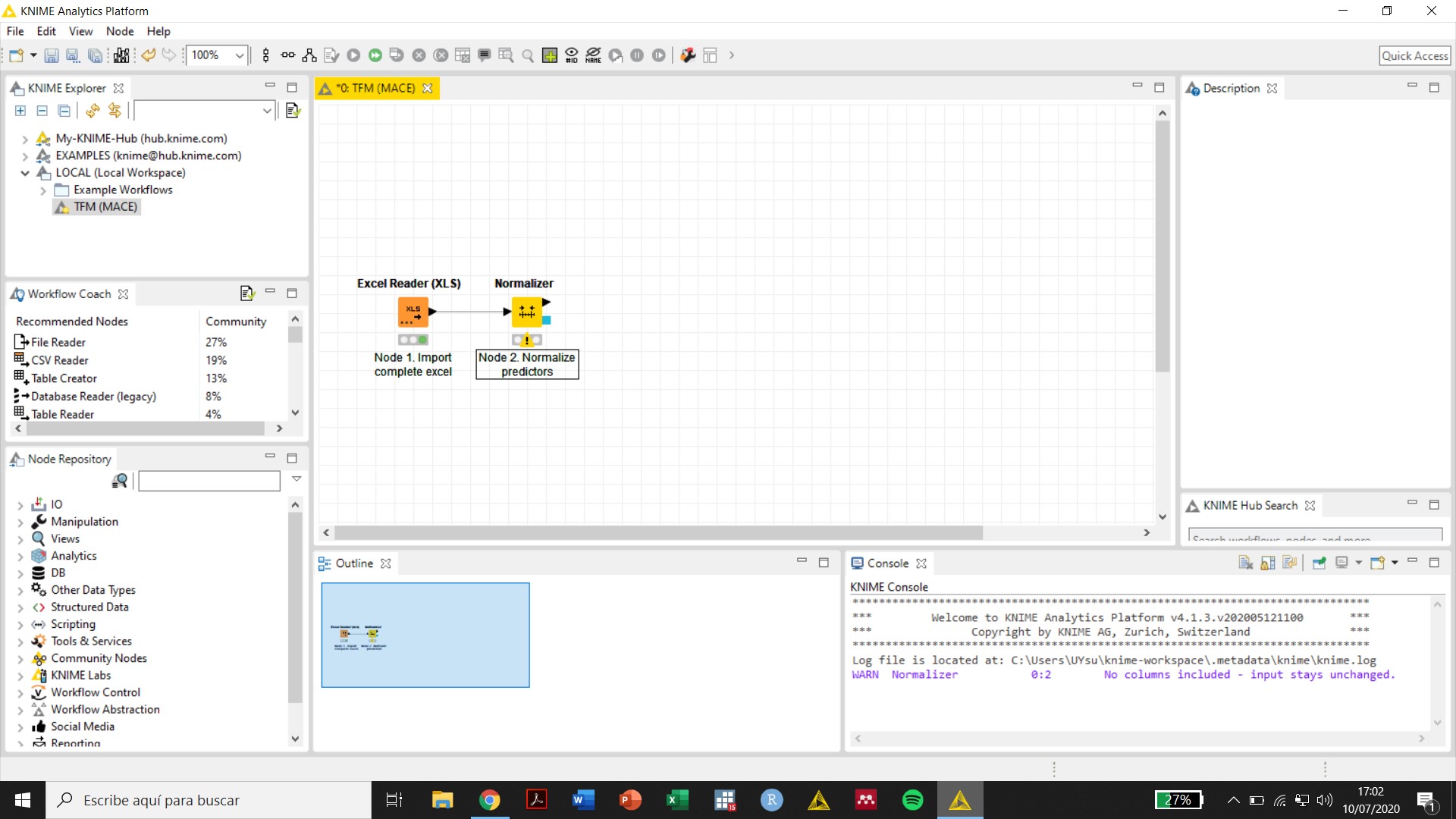
Thank you, Scott. My columns after file import with the the Excel Reader node are all defined as “S” (strings). I used the “String to Number” node to convert them to double (all but one column -that defines the class- are numbers with two decimal places, i.e. 1,68, 2,95, etc.). However, an error is produced (se attached image) and the Console seems to say that there are missing values in all columns, which is not true. Any suggestions?
Thank you,
Marc
Thanks, screenshots can work, but they tend to only show what the poster thinks is important, and key troubleshooting information is usually not included. Having the knwf/knar file and data would be ideal.
For example, what does the table coming out of the Excel Reader node look like? None of the screenshots actually provide this information.
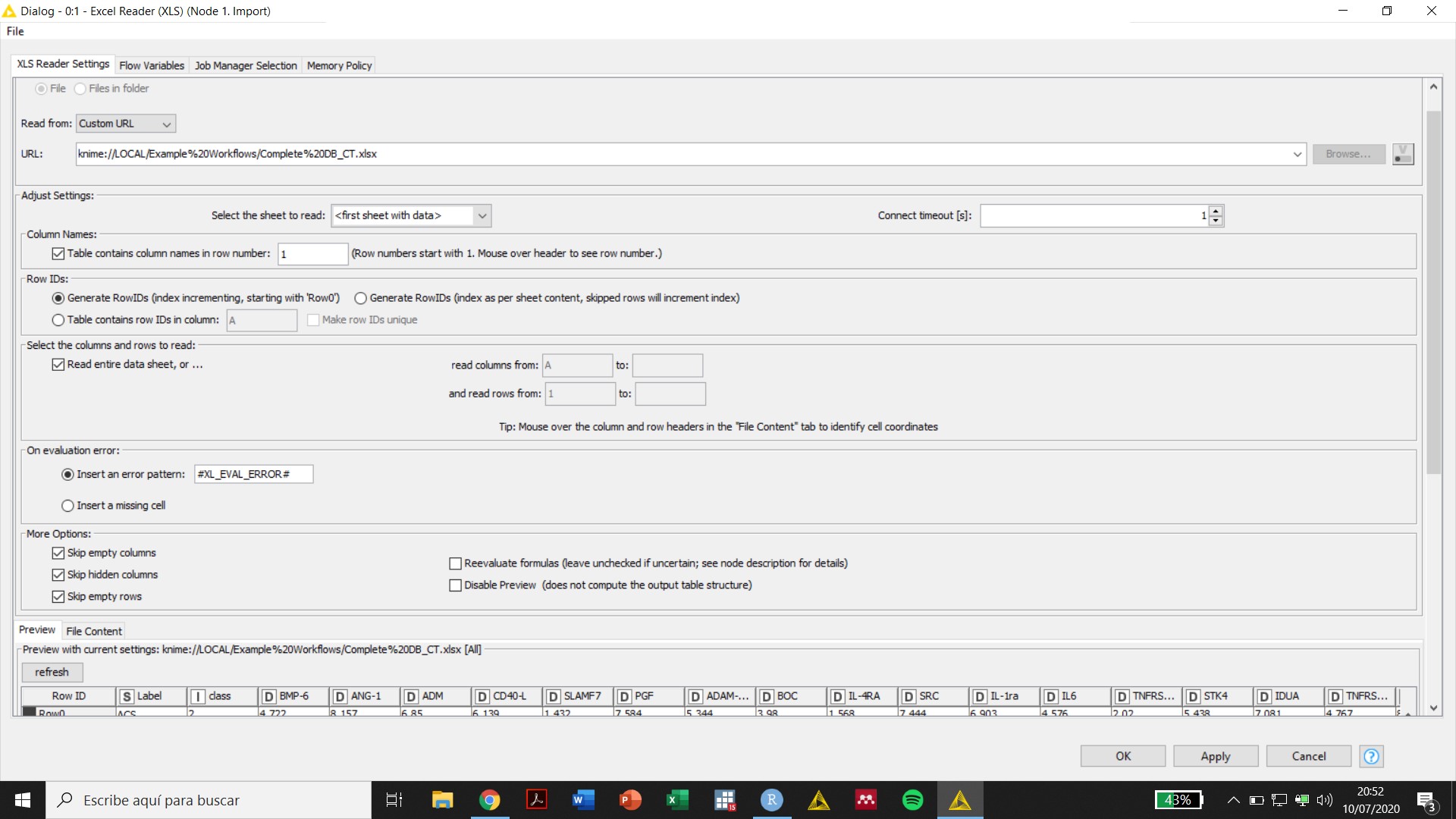
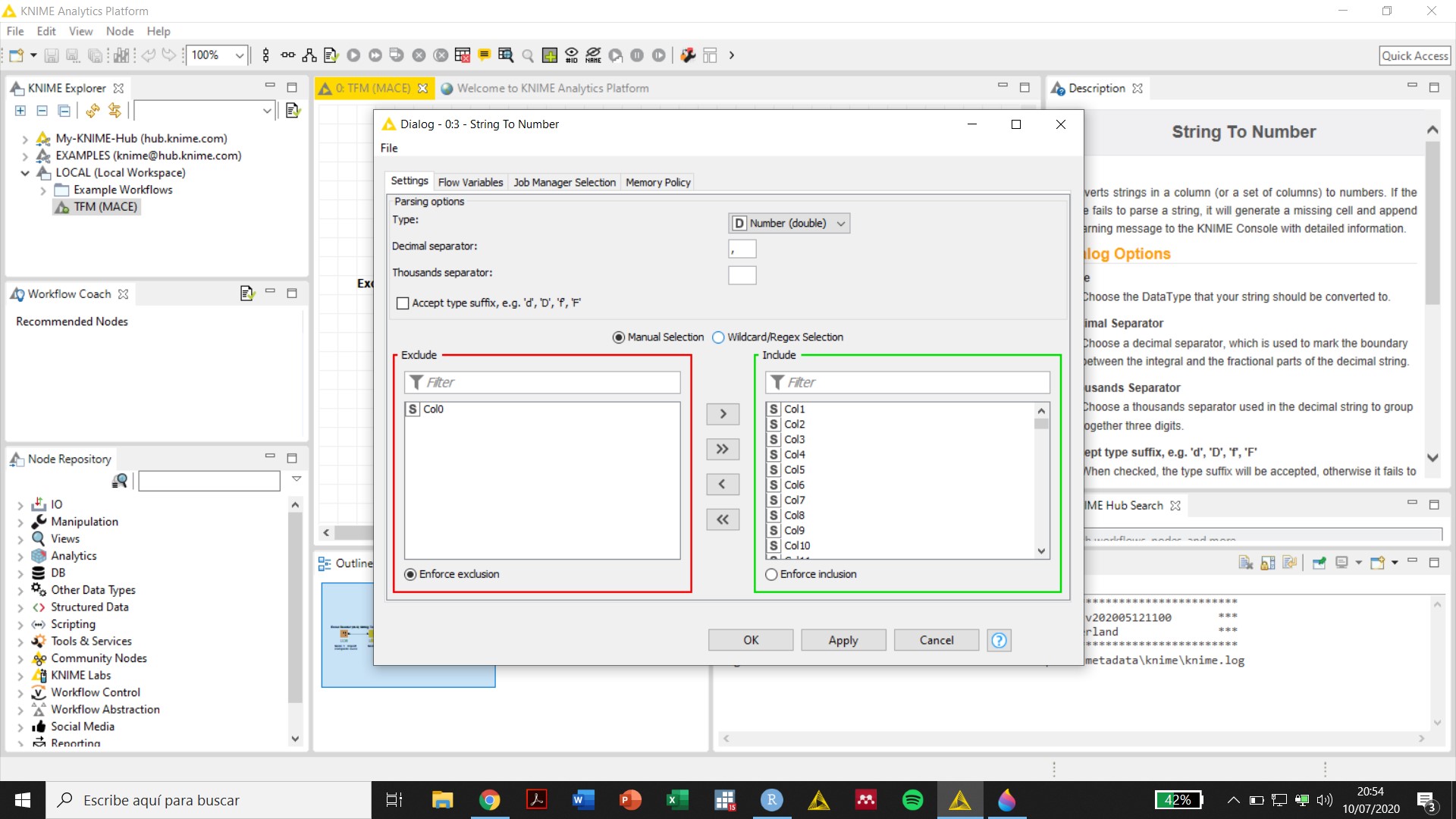
The screenshot of the configuration of your Excel Reader node is helpful, but it raises some questions. All the columns in view are either Integer or Double, but in a previous reply you said:
My columns after file import with the the Excel Reader node are all defined as “S” (strings).
Where are these string columns?
What are their names?
If there are no string columns, why do you still need a String to Number node?
All the columns in view have custom headers that do not match what the String to Number node is looking for (Col0, Col1, Col2, etc.). Why?
None of this is really adding up. Did you make any changes after your previous reply?
Hi Elsamuel, and thanks for your interest. It seems to be solved now.
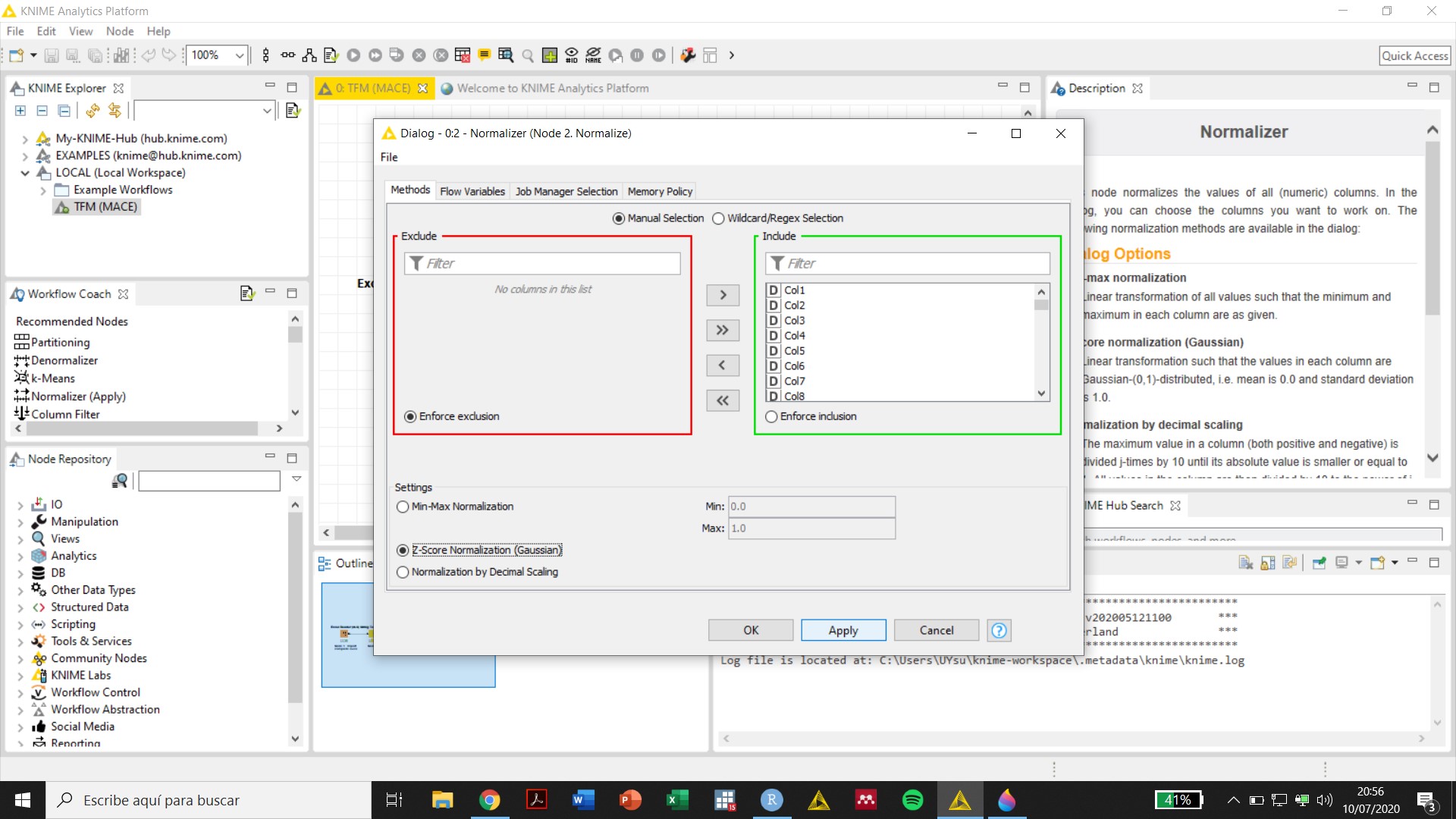
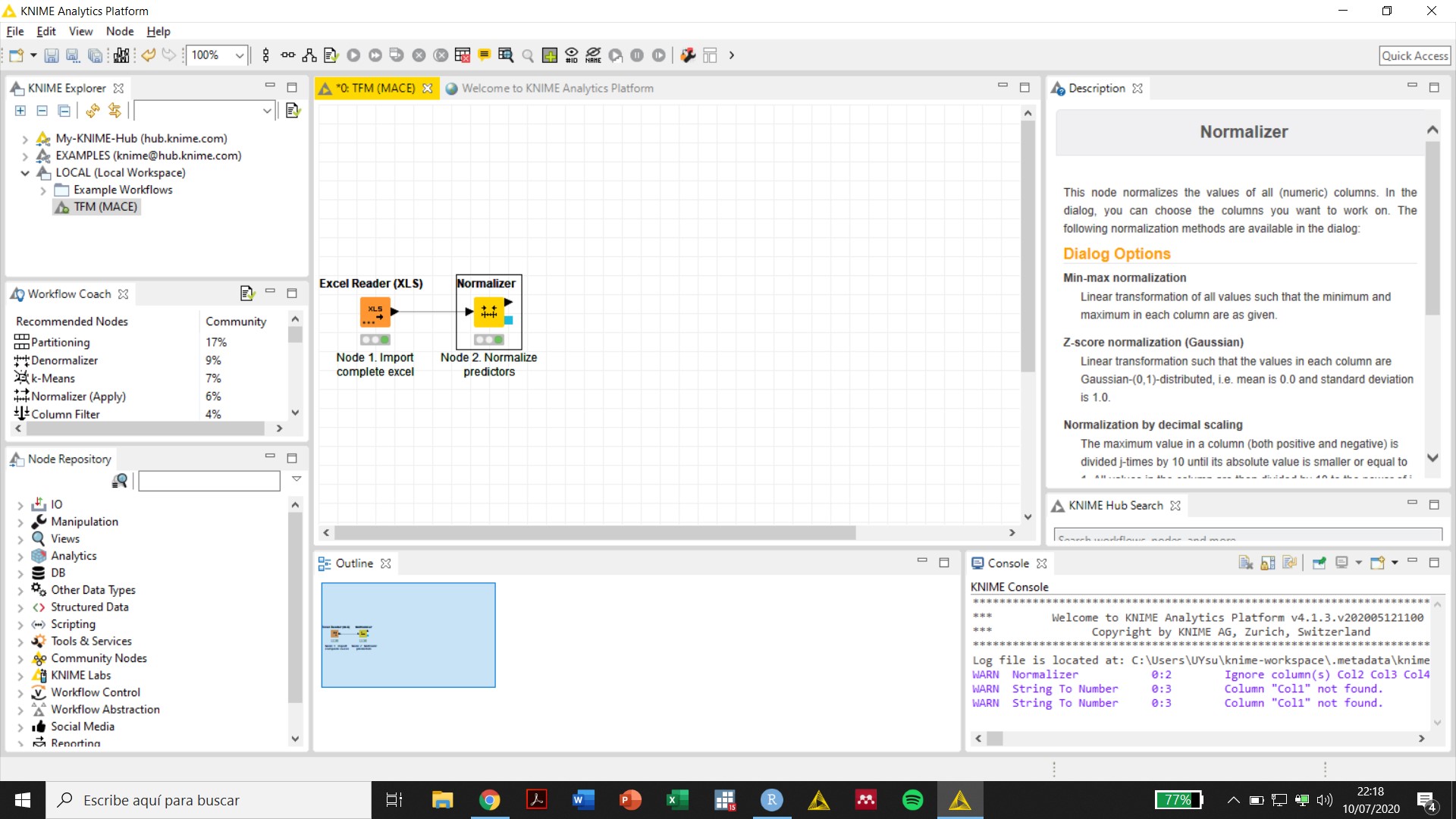
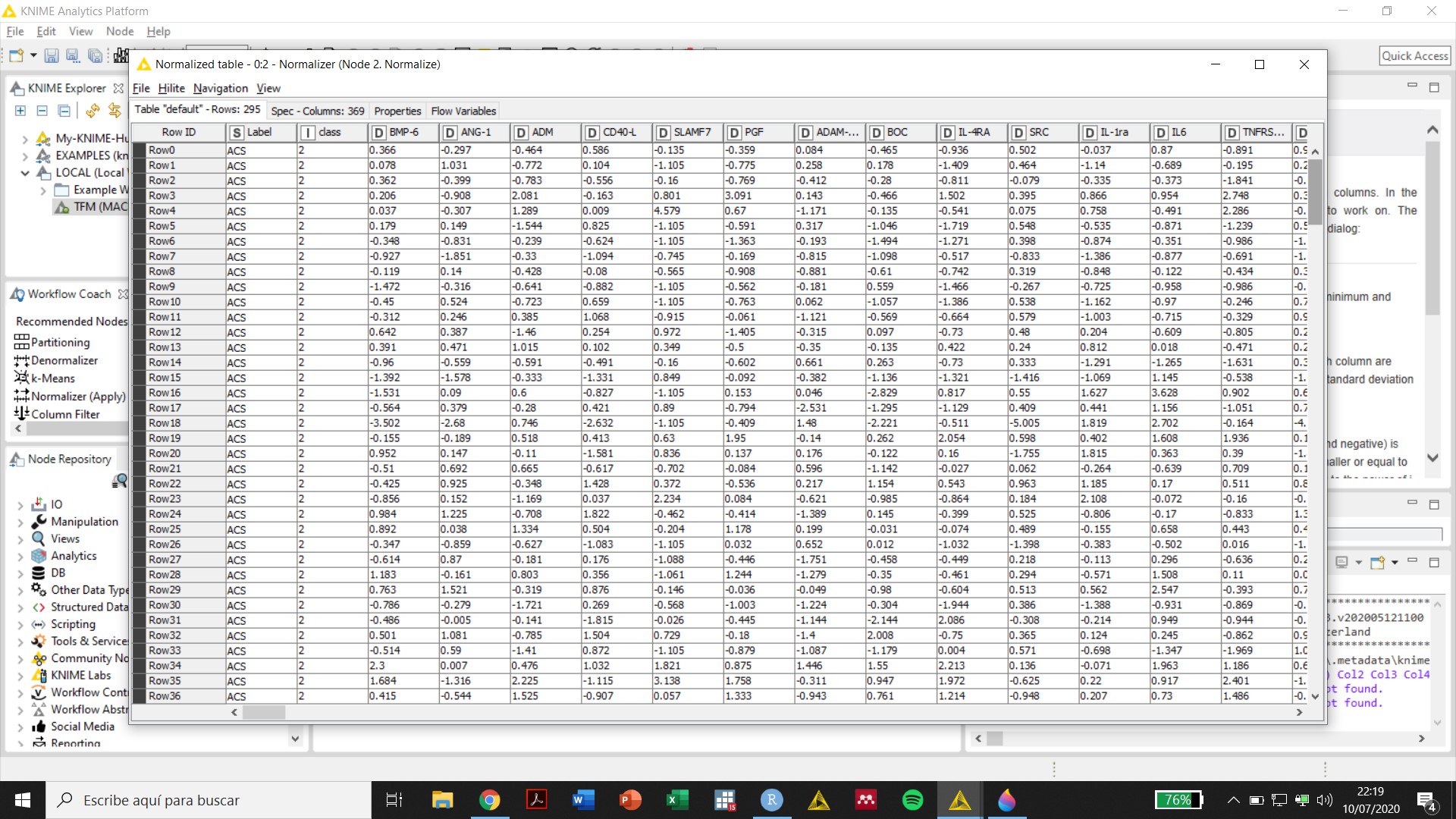
Initially, the variables were imported from excel as “S” even though the first row was marked as the row containing predictor names and all other values in cells were numbers. The use of the String to numbers to convert “S” to “D” generated an error. However, now the variables appear as “D” after the Excel Reader node and I could use the Normalize node without the need of converting the variables to “D” (see screenshots attached). I really do not know what happened, maybe my computer was too slow to incorporate the changes.
In any case, thanks for your help and if you need more explanations to see what happened, please let me know and I will provide the information the best I can.
Seeing unexpected results in Normalizer node. I selected Z-Score Normalization. But after running the node I see some values are > 1… I thought the range is -1 > 0 > 1
to my understanding normalization based on z score transforms data to follow Normal (Gaussian) distribution with parameters 0 (mean) and 1 (standard deviation). Data following Normal distribution with mentioned parameters can have values under -1 and over 1. Maybe you want/need Min-Max normalization?

{kind=link}