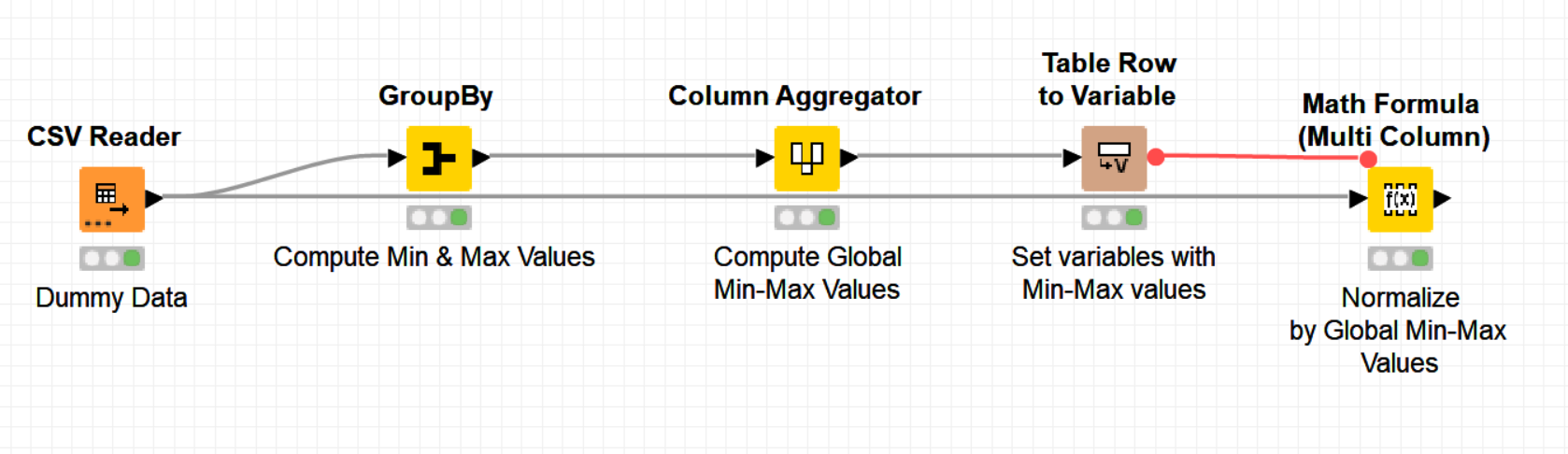
I would like to normalise my data. However, I have different columns refering to the same magnitude, so I would like to apply the normalisation of all these columns (not the normalisation of every variable/column of my data). How can I do that?
There are different ways of achieving this more or less efficient. What kind of normalization do you need to apply, Min-Max, Z-Score (Gaussian), other ? How many rows is your data made of ?
I would like to apply the min-max normalisation. My data is built of 183464 columns, most of which are the same magnitude I want to normalise. How should I do that?
Very nice. I like @aworker solution. @helfortuny you could mark his post as the valid solution if it fits your needs for others to find as well. Instead of GroupBy we might also use Extract Table Spec Node i guess
br
Hi! It seems that there is an error when executing the GroupBy node. It says “No grouping column included. Aggregate complete table”. I think it’s because I have more columns which are not number double type, right? How can I solve this?
You need to add them. Can you show here a snapshot of your groupby configuration for the aggregation tab ? Without at least a snapshot is difficult to help you.
Do you need to normalize all numerical columns together or to globally normalize for instance the integer columns first and then the double columns ? Normalization woulb be different in both cases. Which one is yours ?
Neither of both. I would like to group the variables from “f0A_mean_1” until the last column and normalise them all together. They have all the same units (Hz).
Furthermore, I would like to normalise the other numerical variables independently, each one separetely. My goal is to normalise all the numeric values in my dataset.
There are two ways of doing what you want, the easiest and the more complicated. I’m not in front of a computer and I do not have access to your data so I can only guess and suggest.
My easiest suggestion:
Filter out beforehand any column you do not want to normalize,
Convert the remaining columns from the current type (i.e. integer) to double.
Apply the rest of the workflow as it is.
The more complicated one is to go node by node and configure them based on your needs so that you select manually the columns you want to normalize. Doing this way is a bit more involved but it will force you to understand how the nodes and the workflow work