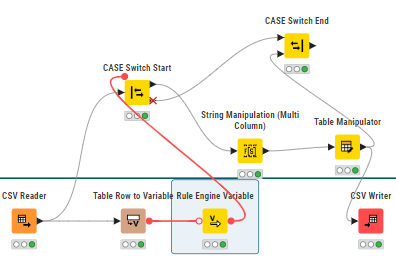
I have a CSV file which I am reading through CSV reader. In this table there is a filed by the name UniqContactName. This basically stores unique ID values. I want that the node that is generating a unique value(String Manipulation Node) should be processed only once if the UniqContactName field is empty or missing or has a ? mark. Following is my workflow:
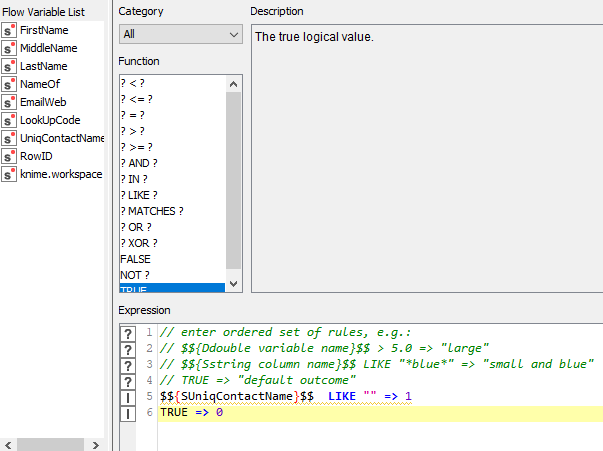
The Rule Engine Variable is organized as follows: -
If you have a ? it’s most likely because the result doesn’t match both of your defined cases. Replace the “TRUE => 0” with a “NOT [your first line] => 0” and give it a try.
Thanks for your reply. I tried what you suggested but still it is executing the string manipulation node. The string manipulation node should be just executed once when the UniqContactName field is blank.
Hi
Thanks for your reply. Let me explain. I have a CSV file in which I have a field UniqContactName. This field stores a unique ID value which is generated by the String Manipulation Node. This node should not be executed if the UniqContactName field is not blank otherwise it will generate another value for the unique ID. This is what I want to achieve. In a programming language it will be represented by
let me have a go here - I get what you want to do.
I take that the csv reader reads a full table (e.g. multiple rows) and not just one row. Correct?
If that is the case then looking at your workflow above, your logic will ever only apply to the very first row (table row to variable converts the top row to variables, everything else is discarded). So unless there is some looping mechanic that is not visible to us your rule will only apply to the first row and my best guess is that this row is not missing or empty.
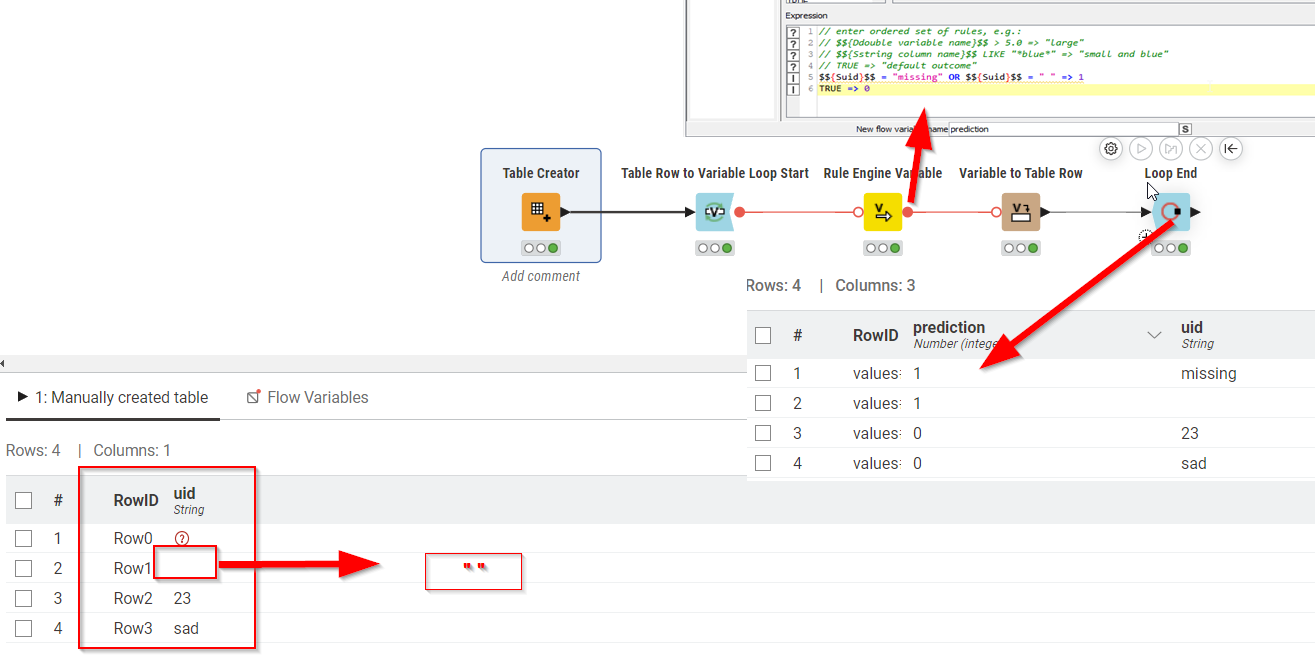
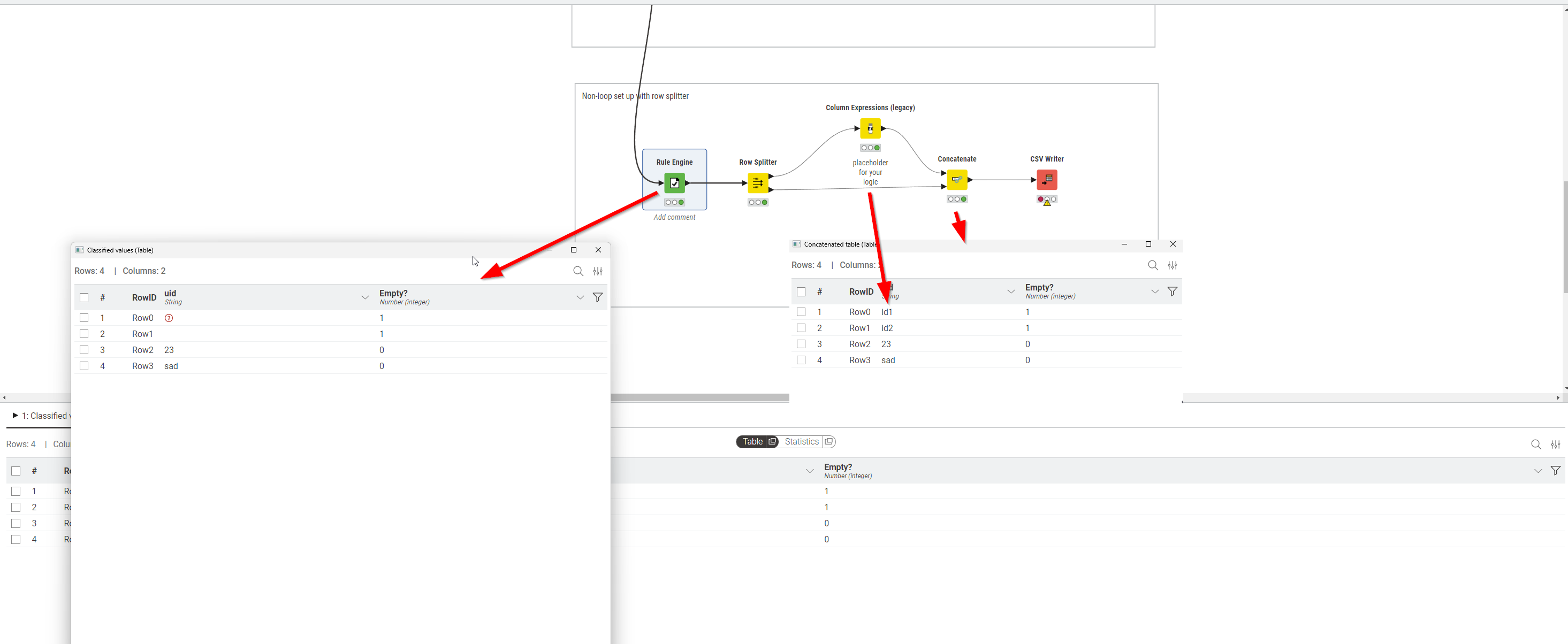
There are different ways on how to address this - in the screenshot below I used a Table Row to Variable Loop Start to iterate over every row and to turn the contents of each row into variables:
You’ll notice that my rule captures two scenarios: if something is missing (red question mark) it will show up as a string “missing” once turned into a variable. I also capture the scenario where there’s an empty string (" "). If any of those are true then the variable is 1 in any other case 0.
In this minimal example I then turn all variables into a table row and collect them with loop end which allows inspecting all the results and at least from my perspective it is showing up correctly.
If you are looping already or if there’s only ever one row in the file that is read then my apologies :-).
Best is always for you to provide a minimal, anonymised example which showcases your issues - if that does not happen there’s always some guessing involved when trying to help.
The field that I am interested is only UniqContactName.
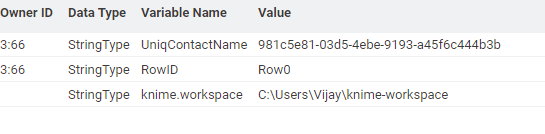
The Table Row to Varibale display as follows: I have only included one field.
The output display from this node is
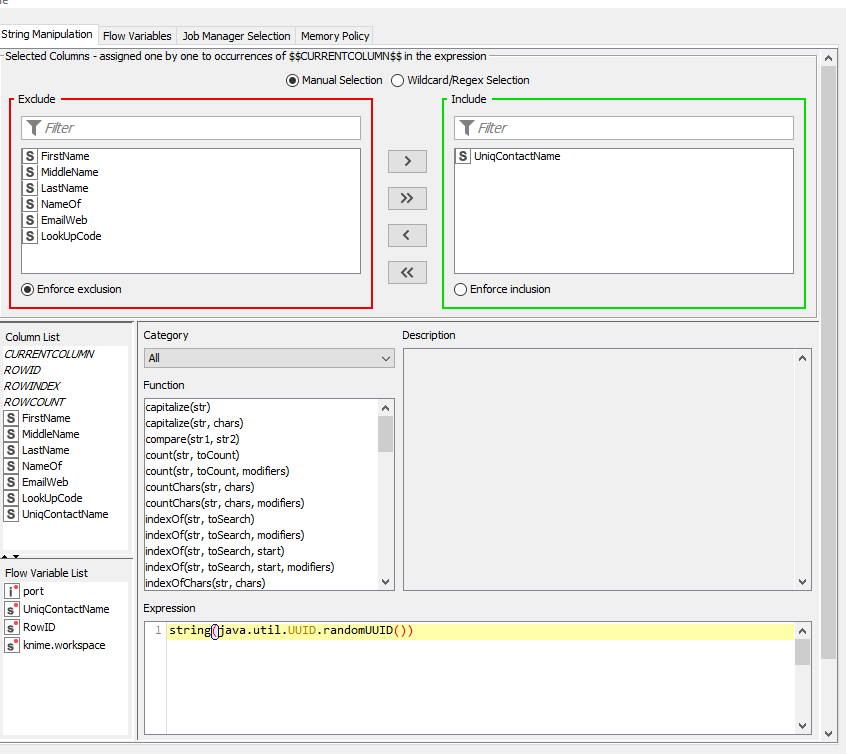
Then I have a Case Switch Start with 2 ports 0 and 1. Now comes the main part the String Manipulation Node which is were the unique ID is being created and that will be stored in UniqContactName filed.
This node through the Case Switch should only get activated when the UniqContactName field is either “missing” or is " ". If UniqContactName has value then it should use the other path through Case Switch node. This is what I am trying to achieve. I hope this should give you a better idea as I have put all my details above.
It is as I suspected: your workflow only processes the very first row of the file you are reading.
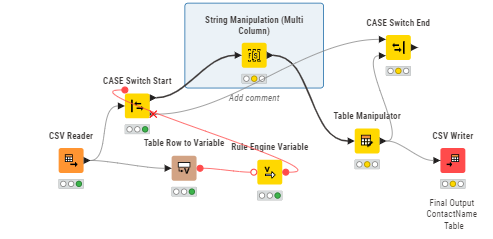
I think if you combine what you have with the WF I posted (collect everything in loop end, then use CSV writer)
Can’t provide a WF right now but may be able to help tomorrow
Other thought:
To avoid looping why not use row splitter to split into two tables - one where those rows w/o issues go a one where everything else goes. Then after adding ID concate again…
Knime have a node to mark duplicated or count. With this information, you can sort by firts/unique ID fisrt and then, you can see if you need to stay with the data or remove duplicated ones.
A simple solution that you can use too the groupby node to show only the first occour and group by ID as key OR just set to duplicated node to remove the others lines that match with column ID duplicated.
If you need to remove empty, just use the row filter to remove missing values OR em Missing node to adjust the values (copy, define new one, remove line…)