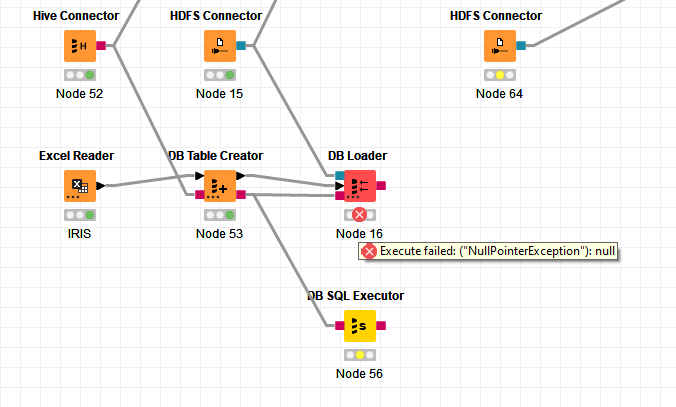
I have an error on DB Loader node while i am trying to transfer data from Excel Reader to Hadoop Cluster. I have attached related workflow photo and log details to this topic and also you can find my error log below the topic.
Note: I can use insert-update etc. operations via DB SQL Executor when i try to transfer it but DB Loader is not working.
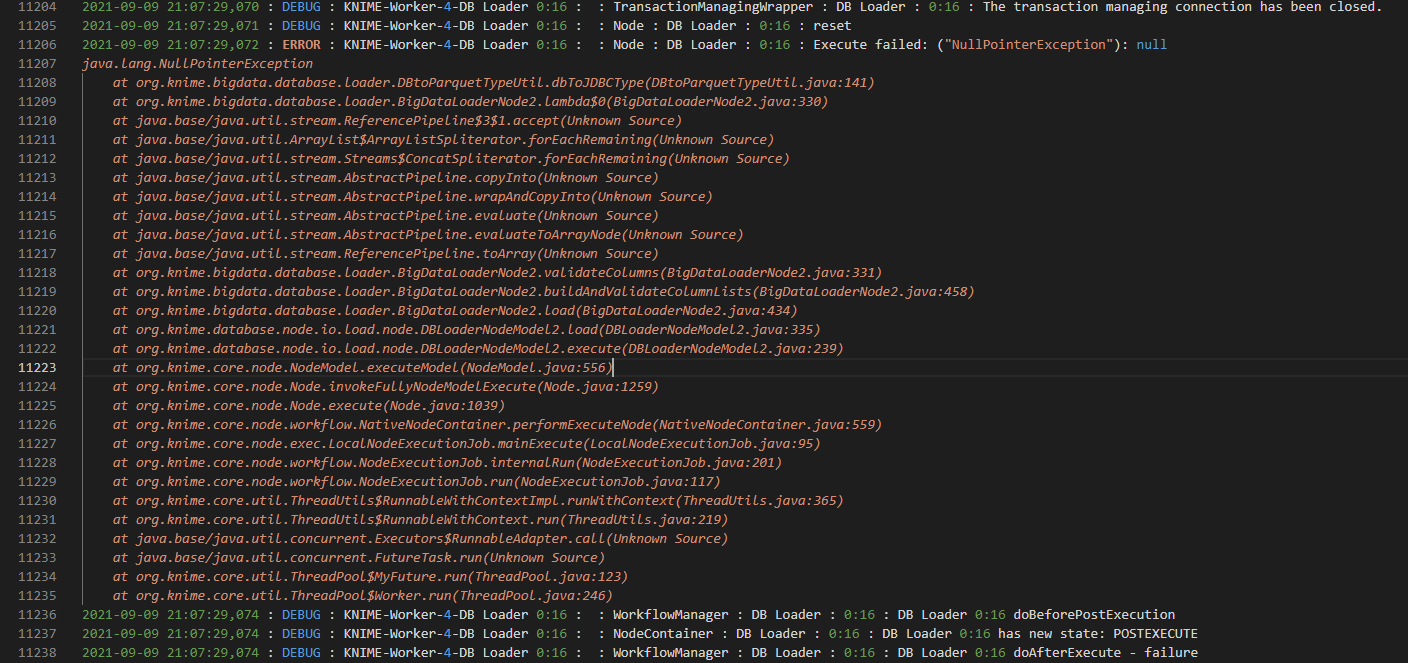
2021-09-09 21:07:29,072 : ERROR : KNIME-Worker-4-DB Loader 0:16 : : Node : DB Loader : 0:16 : Execute failed: ("NullPointerException"): null
java.lang.NullPointerException
at org.knime.bigdata.database.loader.DBtoParquetTypeUtil.dbToJDBCType(DBtoParquetTypeUtil.java:141)
at org.knime.bigdata.database.loader.BigDataLoaderNode2.lambda$0(BigDataLoaderNode2.java:330)
at java.base/java.util.stream.ReferencePipeline$3$1.accept(Unknown Source)
at java.base/java.util.ArrayList$ArrayListSpliterator.forEachRemaining(Unknown Source)
at java.base/java.util.stream.Streams$ConcatSpliterator.forEachRemaining(Unknown Source)
at java.base/java.util.stream.AbstractPipeline.copyInto(Unknown Source)
at java.base/java.util.stream.AbstractPipeline.wrapAndCopyInto(Unknown Source)
at java.base/java.util.stream.AbstractPipeline.evaluate(Unknown Source)
at java.base/java.util.stream.AbstractPipeline.evaluateToArrayNode(Unknown Source)
at java.base/java.util.stream.ReferencePipeline.toArray(Unknown Source)
at org.knime.bigdata.database.loader.BigDataLoaderNode2.validateColumns(BigDataLoaderNode2.java:331)
at org.knime.bigdata.database.loader.BigDataLoaderNode2.buildAndValidateColumnLists(BigDataLoaderNode2.java:458)
at org.knime.bigdata.database.loader.BigDataLoaderNode2.load(BigDataLoaderNode2.java:434)
at org.knime.database.node.io.load.node.DBLoaderNodeModel2.load(DBLoaderNodeModel2.java:335)
at org.knime.database.node.io.load.node.DBLoaderNodeModel2.execute(DBLoaderNodeModel2.java:239)
at org.knime.core.node.NodeModel.executeModel(NodeModel.java:556)
at org.knime.core.node.Node.invokeFullyNodeModelExecute(Node.java:1259)
at org.knime.core.node.Node.execute(Node.java:1039)
at org.knime.core.node.workflow.NativeNodeContainer.performExecuteNode(NativeNodeContainer.java:559)
at org.knime.core.node.exec.LocalNodeExecutionJob.mainExecute(LocalNodeExecutionJob.java:95)
at org.knime.core.node.workflow.NodeExecutionJob.internalRun(NodeExecutionJob.java:201)
at org.knime.core.node.workflow.NodeExecutionJob.run(NodeExecutionJob.java:117)
at org.knime.core.util.ThreadUtils$RunnableWithContextImpl.runWithContext(ThreadUtils.java:365)
at org.knime.core.util.ThreadUtils$RunnableWithContext.run(ThreadUtils.java:219)
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source)
at java.base/java.util.concurrent.FutureTask.run(Unknown Source)
at org.knime.core.util.ThreadPool$MyFuture.run(ThreadPool.java:123)
at org.knime.core.util.ThreadPool$Worker.run(ThreadPool.java:246)
Most likely you will have to take a look at the numeric column types. Big Data systems are sometimes picky about INTEGERES, TINYINTEGERS and BIGINTEGERS and the loader might not be able to fully refelct that.
What version of Hive are you using?
What you could try is convert your data to parquet or CSV in KNIME and ‘manually’ load the data into HDFS and then use external table commands to import the data. That is not the most elegant solution but might give you further insights (error messages) into what is going on:
Hello @mattyseltz ,
The DB Loader does not support Teradata as of now. However it should throw an appropriate error message instead of a unspecific NullPointerException. What KNIME Analytics Platform version are you using?
Thanks
Tobias
Hi, Tobias. My company is using V. 4.3.4. Here is a description of my problem: I am trying to FASTLOAD about 400,00 records from a legacy SQL Server database into Teradata. No approach that I’ve tried seems to work. But I do appreciate your telling me that DB Loader does not work with Teradata. I’ve tried using DBWriter but it seems that whenever I turn the FASTLOAD option on in my Teradata connection, I get an error. I’ve also tried writing the MS SQL data to a Parquet file and then reading it back out (both operations take under five seconds to complete). From Parquet, I then try to load Teradata. I then get an error where KNIME complains about the structure of the table. There must be some discrepancy between the structure of the MS SQL/Parquet data table and what the structure of the destination table in Teradata is supposed to be. I am stuck and would appreciate any assistance.
After substituting the DB Writer for the DB Loader, the error I get is “A failure occurred while setting a parameter value for database table <schema_name.table_name>.”
@mattyseltz would Teradata support aaconstruct like EXTERNAL TABLES where you would load CSV, Parquet or ORC files into a folder and tell the system to use that as an external table which you can later convert into a ‘real’ table.
I have set up such example for a Hive (Cloudera) environment (1|2):
Admittedly this is not very pretty but it does work in these cases.
Hi, m,
I did try dumping my SQL Server data into a Parquet table (which took about 1 second), and reading it back out (which also took about one second). I then tried to insert this data into Teradata but I was not successful. I don’t remember the exact error but I believe it was data-type-conversion related.
Thanks,
Matt
From my experience it would make sense to check the exact type Teradata wants to have and mabye try to convert that early on. Candidates are Long Integers that would show up as BIGINT on a big data system, all sorts of time and date variables (think zoned time variables) which might be best transferred as STRINGS in the first place. In the example I try to translate KNIME column types to Hive; this may vary over DB systems.
Also you should check for column names with blanks and special characters which also a lot of systems still do not like.
Then you could try and use CSV (not alsways the best option, I know) but sometimes there is a way of using zipped CSV files that would reduce the amout of transfer.
Also if you data is very large it could make sense to do it in chunks that would be easier to upload any maybe use a fail/retry configuration than do it all in one step.
If I were to set up a JDBC trace, would I be able to see the specific details of the “A failure occurred while setting a parameter value for database table <schema_name.table_name>” error?
If it helps, the error number returned by the Teradata JDBC driver is 1151. I have researched it and it is somehow related to parallelism in FASTLOAD. That’s great, but how do I resolve it and get FASTLOAD to work with Teradata? Thank you.
My problem is solved. Here were some of the problems:
I did not specify CHARSET=UTF-8 in my URL parameters;
There was bad data in the same row in two columns. My boss found this by turning off FASTLOAD and loading one row at a time until he found the offending row. He was then able to filter out the ‘bad’ characters.
Some of the VARCHAR values were greater than 500 in length, although the fields that were auto-generated in Teradata by Alteryx contradicted this. He compensated for this by making the fields in the Teradata database that were getting loaded by KNIME to be fairly wide.
(I hope this information helps other folks on this board.)