I have a string2doc node that uses rowid’s as document title.
If I next apply a number filter (filtering mode filter terms representing numbers), the numbers get indeed filtered out, but also the numbers in the document title. That last thing shouldn’t happen. Is there any way to prevent this?
Hey @RAPosthumus,
my suggestion is, that you need to specify in your reader node, that the data contains a title / label line. What reader node do you use?
Kind regards,
Patrick
Hi @RAPosthumus,
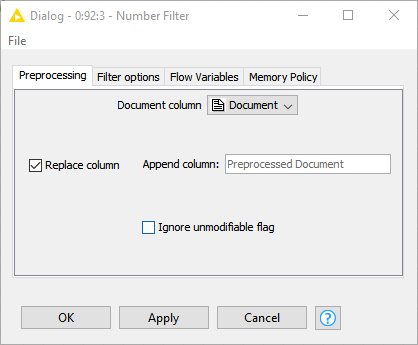
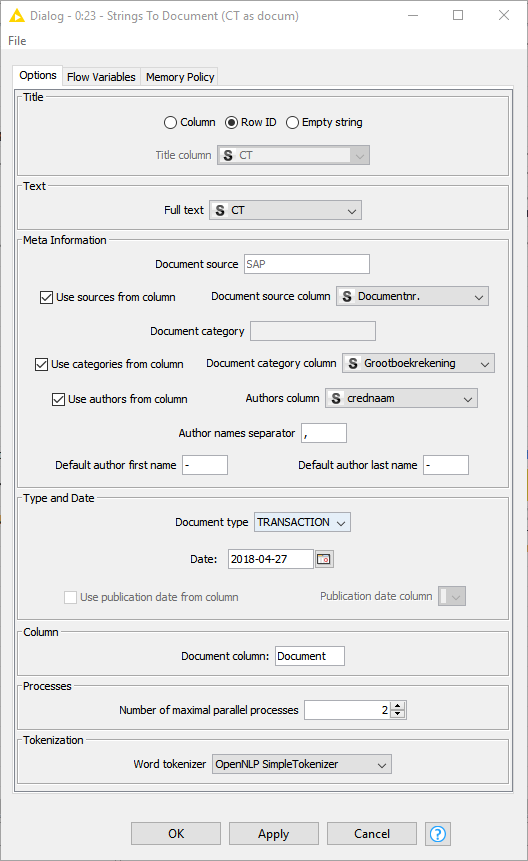
document titles get preprocessed as well, like the document body. This can’t be prevented. You can set up the number filter in a way that is filters out only terms that represent numbers and leave terms that contain numbers. Row IDs contain numbers (but don’t represent a numbers) and thus won’t be filtered. Alternatively use a different string for the titles.
I hope this helps.
Cheers, Kilian
Thanks Kilian.
I need the rowid in order to make references later on in the chain (i.e. to get info past a document vector node).
It sure would help if there was an extra checkbox in the string to document node: exclude field from preprocessing operations.
For your use case I recommend to use the RowID also as document category field. This field will not be preprocessed and can be extracted later on for joining.
Cheers, Kilian
Ah that is a nice workaround.
I discovered another workaround:set the tokenizer to OpenNLP English Wordtokenizer (I used to have Open Simpletokenizer).
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.