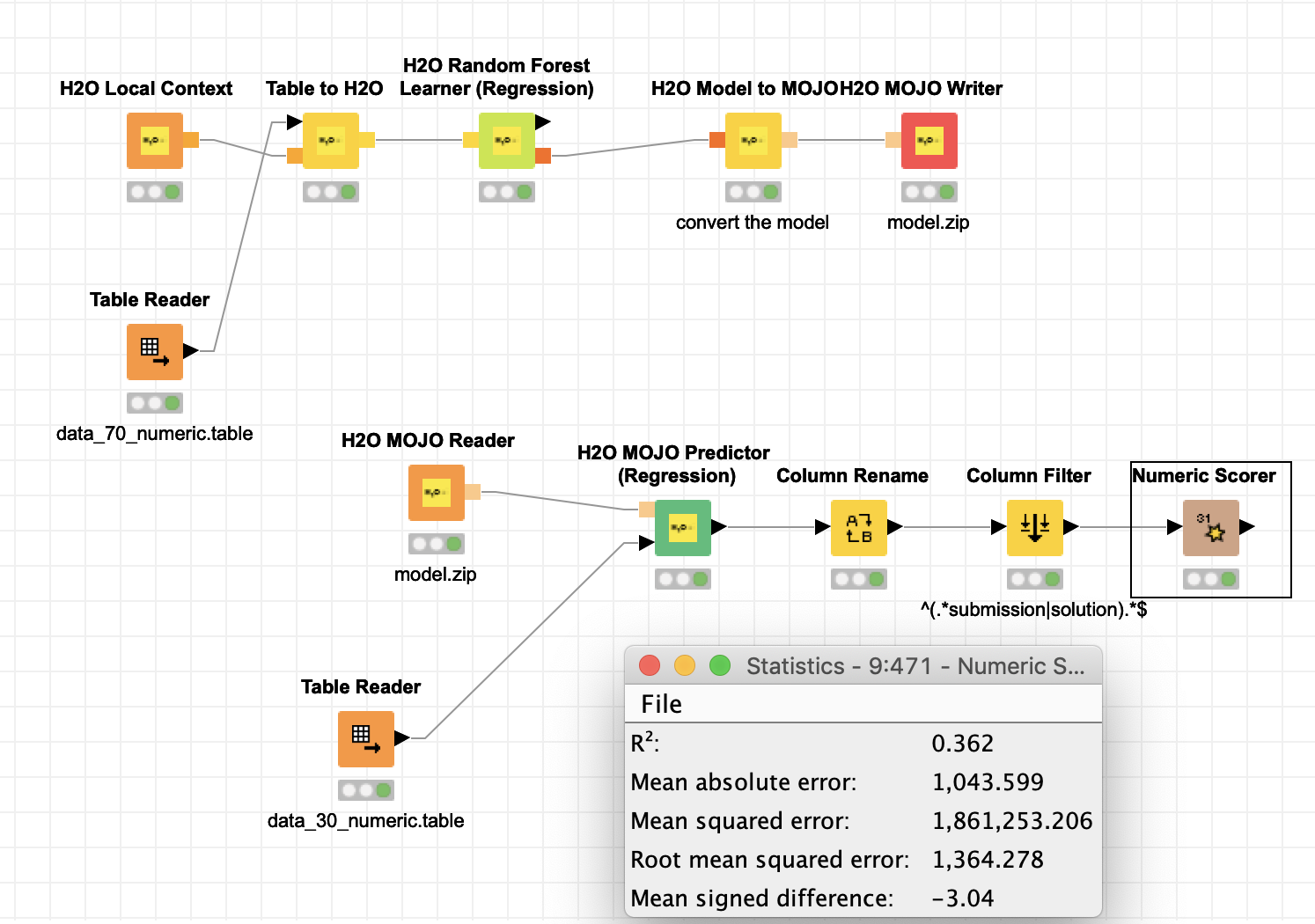
I’ve tried three different prediction models for my project, Linear Regression, XGBoost and Random Forest. They all gave me a negative R^2 value (see screenshot). I have clean data and no missing values.
What can I do to improve my model?
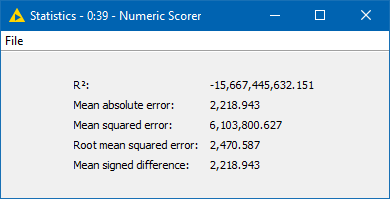
I’ve tried three different prediction models for my project, Linear Regression, XGBoost and Random Forest. They all gave me a negative R^2 value (see screenshot). I have clean data and no missing values.
What can I do to improve my model?
Any ideas regarding improving/fixing this model are greatly appreciated…
Data is clean, must be a setting issue i’m missing…!!
If you could tell us a bit about what your task is and what data you have we might get a better idea about what might help.
Also it would help a lot if you could provide us with sample data, but I understand that often this is not possible. You mention settings; could you tell us which settings you have in mind; which ones do you have used?
I can think of these points first to check the ‘surroundings’
Measures you can take to further improve your features/variables
You could try different model strategies in addition to your current ones, although the ones you use do sound good
@mlauder
Thank you for all your help…
I’m uploading my workflow and the data.
Any advise greatly apreciated…
BigMartSales 2.knwf (2.3 MB)
Train_Dataset.xls (1.6 MB)
Test_Dataset.xls (1.0 MB)
A few quick remarks (more on that later):
Will have more on that later. RMSE of 1.300 seems achievable, not sure if that can help you.
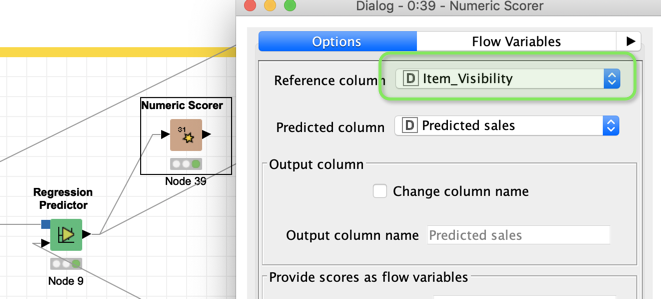
I changed the workflow so it would run and produce a result you can interpret. I also added tie other workflows with a H2O model and a XGBoost ensemble but the numbers are not getting better. There might be some work to do with regards to normalisation and feature engineering. From what I see the models get the direction right but does not match the exact numbers.
Hi @mlauder
Thank you for your reply and help.
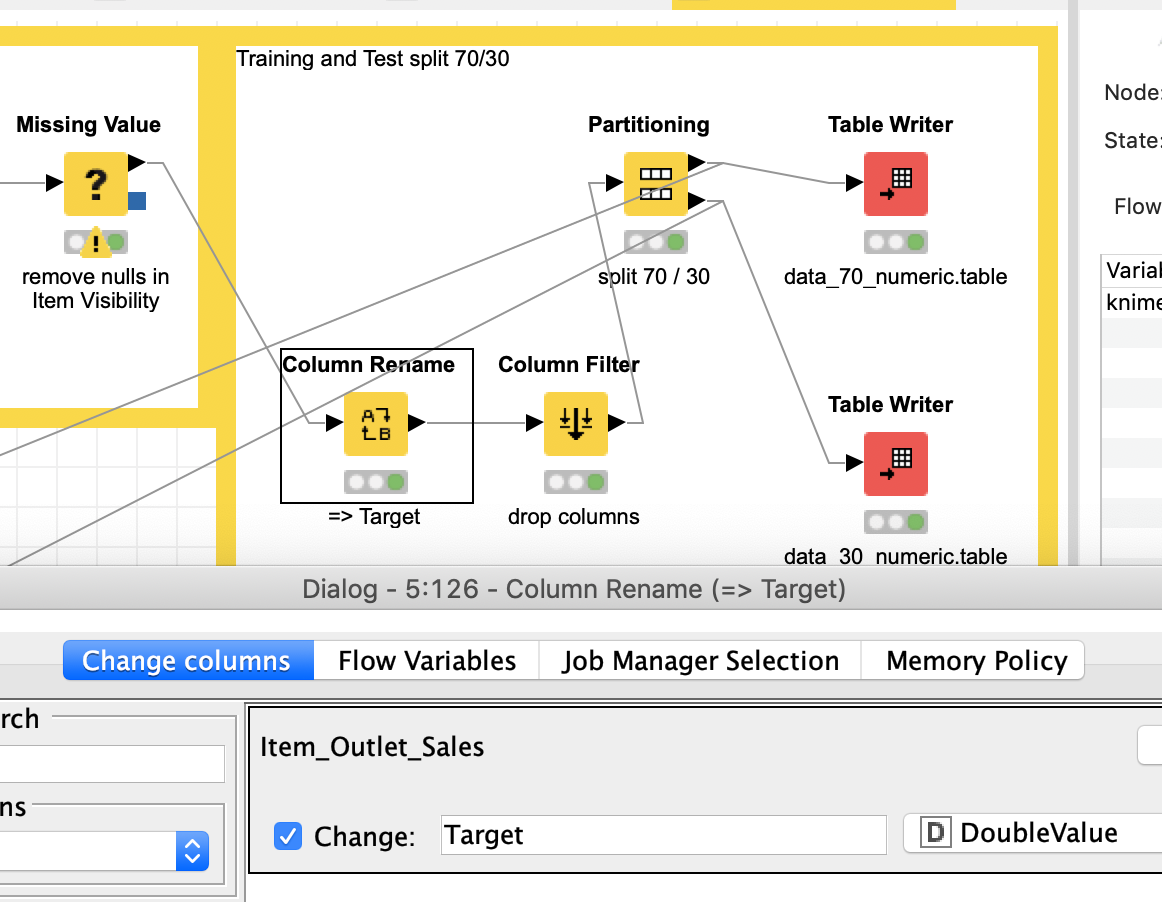
1- I see that me using two separate files, one for training and one for testing doesn’t work. How come? isn’t this the standard.?
2- If I merge my training data with my testing data and use the Partitioning Node, how can I ensure that Knime knows which data is which? My testing file does not have the column with data I need to predict (Item_outlet_sales) column, How do I make sure Knime does not try to use this to train the model?
Thanks in advance!
The question is what is your target variable. From the structure of you data it seemed your second dataset was the one with the unknown target data. You would have to define which column you want to predict. Then you would split your original data into test and training. If your testate does not contain the target variables you will not be able to test the quality of your model.
If you use the Partitioning node you have two Streams of data. You tell them apart by connecting the training nodes to the upper arrow and the testing/predicting nodes to the lower part.
The modification of your workflow I uploaded renames your value to “Target”.
It might be useful to familiarise yourself with the concepts of predicting with a basic example, where you can still read the rules that are generated: