I am working on work flow to process PDF header files for temperature analysis. Attached is the workflow I’ve started with a file reader and PDF file example (However the topic forum would not let me uploaded it as a PDF so it is uploaded as a jpeg), Variable loop “To parse PDF recursively”, and then the bag of word to gather the list from each PDF. However I’m only looking for one value which is the " Máxima Temperatura Registrada" for 65 deg C.This reoccures in different files as Temperature Maxima or Bottom Hole Temp.
From the examples I’ve seen, most of them are looking word BoW dumps and frequencies with total amount of words. However how could you pin point the search to find one value from the whole PDF? I know I am on the right start for parsing the documents. Since the document is based in chart, am I supposed to do something new? I appreciate the ample amount of help.
I later want to gather the temperature points and plot them for scatter cluster plot and I have many files like this.
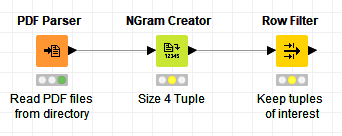
If all you are trying to do is extract a particular phrase, you can probably get away with a very simple workflow, without the usual text analysis preprocessing. I don’t have your PDF to test with, but here’s a toy example that might help. (It assumes the the PDF will parse with the string “Máxima Temperatura Registrada” adjacent to 65, which may not be the case.)
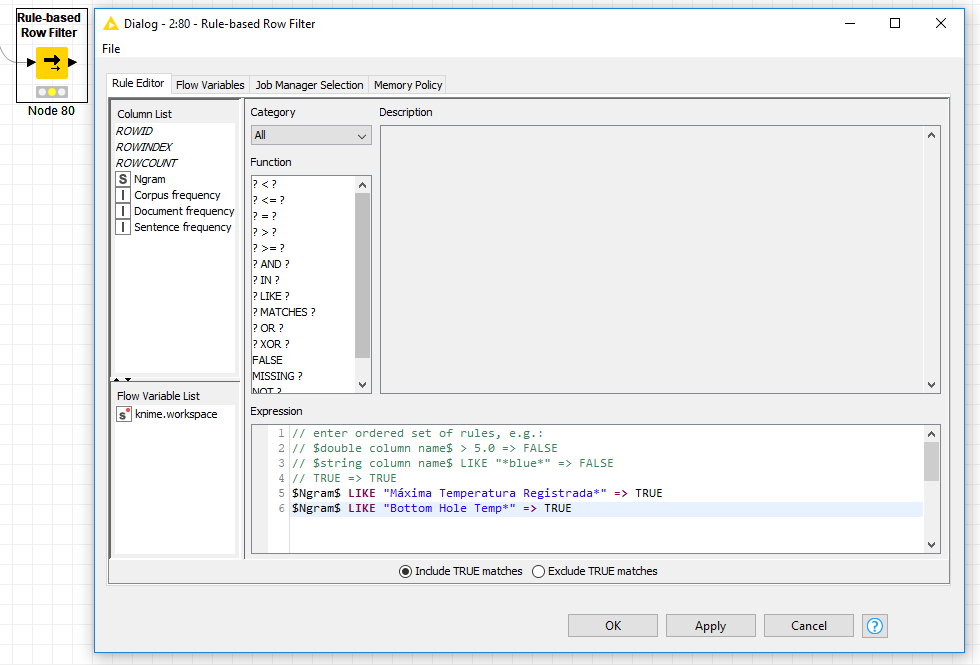
The PDF Parser (set to StanfordNLP Spanish Tokenizer) will read in all PDFs in a directory as individual documents. The NGram Creator node creates a text tuple of size 4 - the hope is that it will create a string like “Máxima Temperatura Registrada 65”. Then the Row Filter node removes everything except the string of interest. One you have this, you can split out the temperature value into a column, and do your analysis or visualization.
Assuming this parses the PDF like I hope it will, this should be extensible to other phrases like “Bottom Hole Temp”. There’s probably a more efficient computational way to do this, but maybe it will help get you started.
This is because the PDF Parser produces documents directly, while the Tika Parser produces strings. If you place a Strings To Document node after the Tika Parser node, you should be OK.
With some adaptation, yes. I didn’t choose it here because Term Neighborhood Extractor returns individual terms (or strings, if chosen) and in this case we’re looking for a tuple to begin with. Does that make sense?
Thank you for the tip. NGram seems to help create the strings needed for what I’m looking for. How could I make this more of a wild card per say? Could I make the row filter a wild card expression for multiple temperature phrases?
I am also going to place this a in a loop on this function for it to read multiple PDF’s however it keeps interating over and over. PDF_Dictionary_Tagger_frequencey.knwf (12.2 KB)
I don’t think you need to use a loop at all, since the PDF Parser will, by default, load all of the PDFs in a given directory into separate documents (even recursively, if needed).
You can create create a loop around the PDF Parser - I didn’t mean to imply that’s not possible. I just don’t think it’s needed here.
If I’m understanding you correctly - and maybe I’m not - you want to load multiple PDFs, and parse them for particular temperature phrases. Then you want to collect the temperatures mentioned across all the documents. The workflow as presented should do that without needing a loop.
The thing to watch out for will be multiple occurrences of the same temperature across documents. This should show up in the frequency counts, though, so you can adjust.
Loop will be best to crawl though multiple files. Similar to searching for temperatures in different regions or etc. I’ve used a loop with the file reader node and it worked great to create work flow to crawl each file one at a time, then oput the information at the final loop node in a table. This way the information from each file is laid out nicely for your interpretation base on where the data came from. Each file would contain its own set of PDF’s.