I encountered the following error while trying to test and run the Tess4j plugin. I get the error below.
ERROR Tess4J 0:1209 Error initializing Tesseract.
ERROR Tess4J 0:1209 Execute failed: Unable to load library 'tesseract': Native library (darwin/libtesseract.dylib) not found in resource path (/Applications/KNIME 4.4.0.app/Contents/MacOS//../Eclipse/plugins/org.eclipse.equinox.launcher_1.6.100.v20201223-0822.jar)
I searched the forum and noticed that few folks encountered the same error a while back, but there wasn’t any resolution. Note: I have tesseract installed, and I can run it from the terminal without any issue.
If you’ve experienced this particular issue, how did you go about resolving it?
This is a known issue, and an issue has been opened on our backlog for it.
As for a quick fix, you can use a Python Script node along with the pytesseract package to perform the same task. Check out the contents of this Python Script node:
import base64
from io import BytesIO
import pytesseract
from PIL import Image
# copy input table to output table
output_table_1 = input_table_1.copy()
# encode the image data
encoded_image = base64.decodebytes(input_table_1['Image'].iloc[0].encode())
# create a byte stream from the image and convert it to the Image type (pillow)
stream = BytesIO(encoded_image)
image = Image.open(stream).convert('RGBA')
stream.close()
# define the command for starting tesseract
pytesseract.pytesseract.tesseract_cmd = r"./data/tesseract"
# extract the text from the image
try:
output_table_1['Image Text'] = pytesseract.image_to_string(image)
except:
output_table_1['Image Text'] = None
# save the image to the node outport
output_image_1 = encoded_image
In the example above, I’m decoding a PNG that was sent to my workflow via REST as a base64 encoded string. You may not need to perform the same decoding and type conversion steps; it’s just an example. Once the image is in a usable state, I’m using pytesseract to extract the text.
Please note - the following line is critical:
# define the command for starting tesseract
pytesseract.pytesseract.tesseract_cmd = r"./data/tesseract"
The line of code above points Python to the tesseract executable, which needs to be downloaded to your PC (see this documentation for more details). In the example above I put tesseract inside the data/ directory within my workflow so that it could be easily referenced with a relative path. If you don’t have a valid executable for your operating system downloaded and referenced in this manner, pytesseract will fail to execute.
Thank you for the above steps and code sample. I’ve not been able to make it work. In my use case, I’m iterating over several png images from the Tika node output.
My python script runs without errors; however, there isn’t any text output. When I run Tesseract locally, I’m able to output text.
Here is my python script code:
try:
from PIL import Image
except ImportError:
import Image
import pytesseract
# Copy input to output
output_table_1 = input_table_1.copy()
# Loop over every cell in the 'Img' column
for index,input_cell in input_table_1['Image'].iteritems():
image = input_cell.array
# define the command for starting tesseract
pytesseract.pytesseract.tesseract_cmd = r"/usr/local/bin/tesseract"
# extract the text from the image
try:
output_table_1['Image Text'] = pytesseract.image_to_string(image)
except:
output_table_1['Image Text'] = None
# save the image to the node outport
output_image_1 = image
@sjporter I tried a similar approach to your implementation without success. see above.
Let me know if I’m missing anything on my end. I can’t extract any text iterating over server jpg files.
My gut feeling is that you aren’t seeing text output because an exception is being raised and quietly handled by the try/catch. If you see whoops! as the output then we can confirm.
Great, at least we can pinpoint that the exception is occuring within your try/catch block. Go ahead and print the exception instead of whoops! like so…
@sjporter Looking at the error message above, I’ve modified the python script to read as followed:
import pytesseract
from PIL import Image
# Loop over every cell in the 'Img' column
for index, input_cell in input_table_1['Image_normalized'].iteritems():
image = input_cell.array
image = Image.fromarray(image[0:,0]).convert('RGBA')
# define the command for starting tesseract
pytesseract.pytesseract.tesseract_cmd = r"/usr/local/bin/tesseract"
# extract the text from the image
try:
output_table_1['Image Text'] = pytesseract.image_to_string(image)
output_table_1['Success'] = True
output_table_1['Error Message'] = None
except Exception as e:
output_table_1['Image Text'] = None
output_table_1['Success'] = False
output_table_1['Error Message'] = str(e)
# save the image to the node outport
output_image_1= image
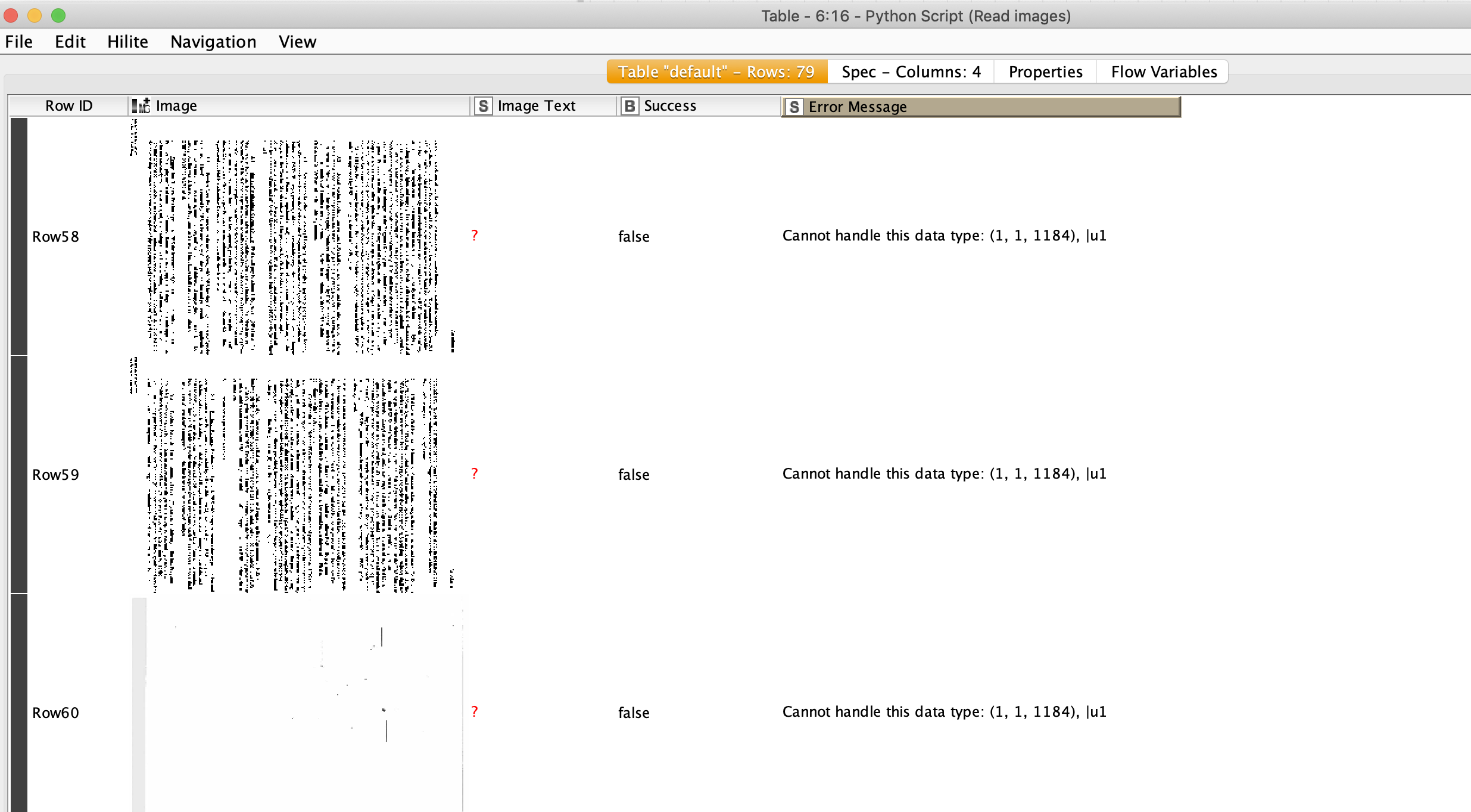
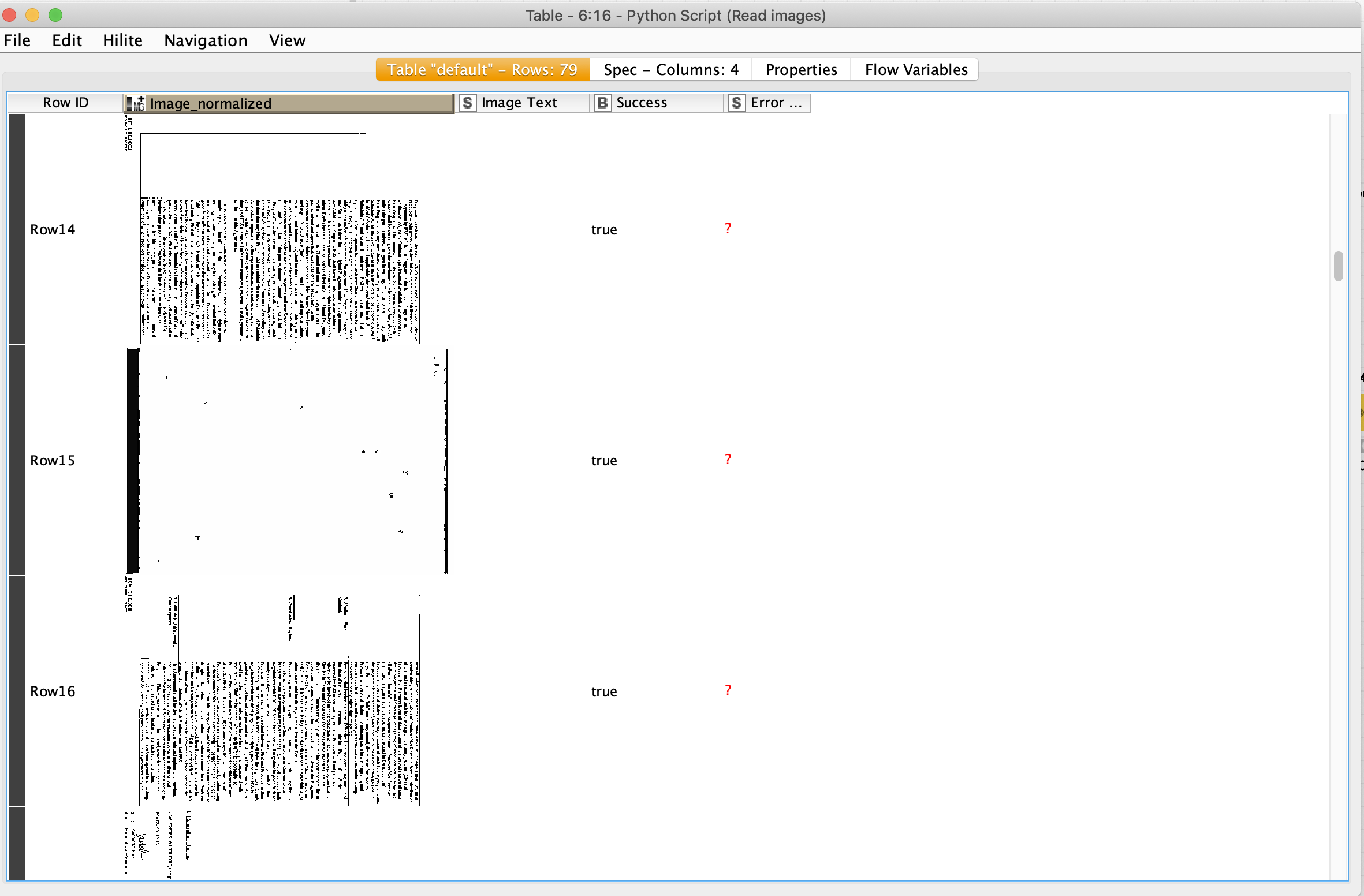
Below find the output but I can’t extract the image text.
From the looks of it, the text in the image is sideways and it looks to be very low resolution(?).
The Tesseract OCR algorithm is only going to be able to do so much in terms of text extraction - there are preprocessing steps that may need to take place, and if the text is unreadable to the human eye it will almost certainly be unreadable to the algorithm.
@sjporter Thank you for all your help. I’m able to extract the text. the issue was the data type. In my use case, I could run tesseract via the terminal without any pre-processing and get the desired output. On the other hand, in knime, I want to batch the different images from a PDF, and store them in an array and iterate over the images from the input node, and image = input_cell.array had to be changed to image = input_cell.array.astype(np.uint8) to make Tesseract extract the text.
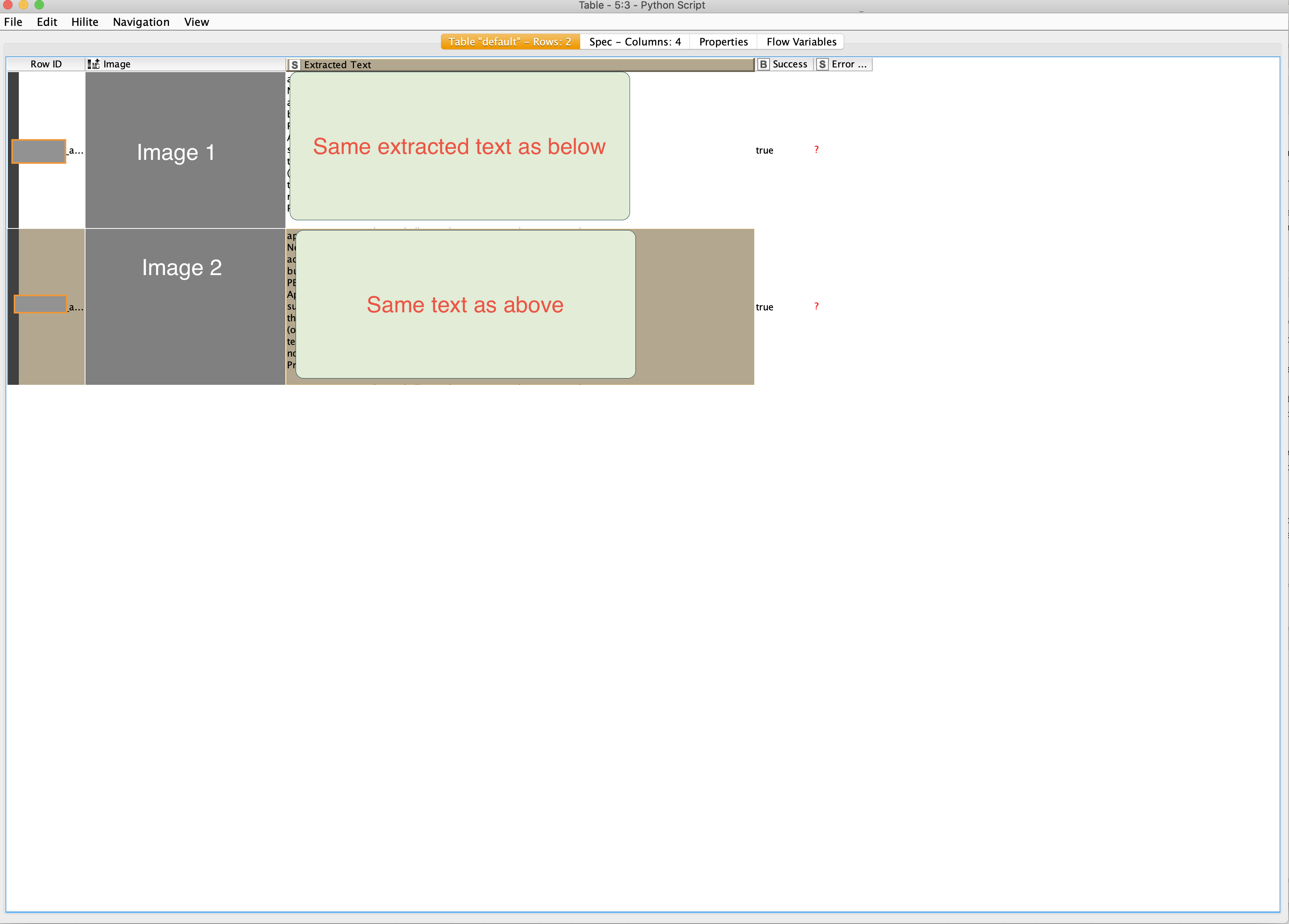
How to output extracted text for individual images in their unique Extracted Text columns?
see the below image 2 extracted text is also showing in the Image 1 extracted text which is not ideal
import pytesseract
from PIL import Image
import numpy as np
import pandas as pd
# Copy input to output
output_table_1 = input_table_1.copy()
# Loop over every cell in the 'Img' column
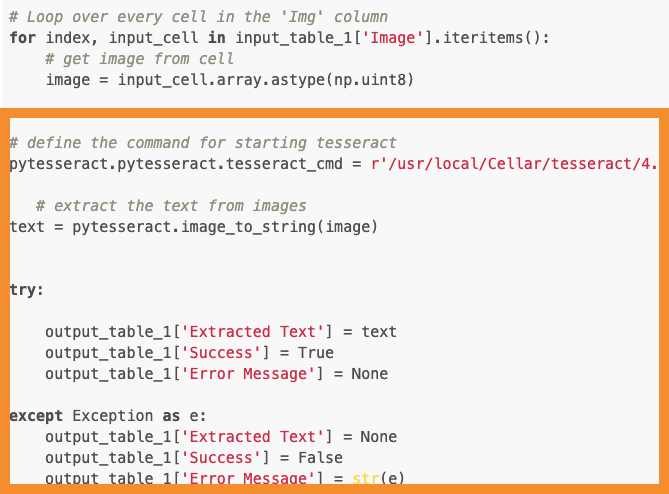
for index, input_cell in input_table_1['Image'].iteritems():
# get image from cell
image = input_cell.array.astype(np.uint8)
# define the command for starting tesseract
pytesseract.pytesseract.tesseract_cmd = r'/usr/local/Cellar/tesseract/4.1.1/bin/tesseract'
# extract the text from images
text = pytesseract.image_to_string(image)
try:
output_table_1['Extracted Text'] = text
output_table_1['Success'] = True
output_table_1['Error Message'] = None
except Exception as e:
output_table_1['Extracted Text'] = None
output_table_1['Success'] = False
output_table_1['Error Message'] = str(e)
The reason you’re seeing duplicated output is that you are reading an image in a for loop but processing it outside of the for loop, so you are only ever performing OCR on the contents of the last image read in the loop.
However, indenting the code highlighted in orange above won’t solve the problem. Your code needs a bit of refactoring to work in the way you’re expecting.
@sjporter, I figured as much. Thank you for the additional resources and pointers. I’m not a python expert yet. I’m merely a “Bricoleur”. I was hoping to get this script working. So that I can deploy it to our knime server to enable the average joe to extract text; it looks like it will take more time than I expected.
Do you know when the dev team will fix the Tess4j node for Mac OS? Like every other node in Knime, I expected it to just work
I currently have over >1000 pdf docs that we need to extract text from.
Here is the script that worked with one document: But it is unstable; I sometimes get Execute failed: An error occurred during serialization. See log for errors. and sometimes it works. It needs to be refactored, and any help from an expert in this forum is greatly appreciated.
import pytesseract
from PIL import Image
import numpy as np
import pandas as pd
from skimage.util import img_as_ubyte
# Copy input to output
output_table_1 = input_table_1.copy()
output_column = []
# Loop over every cell in the 'Img' column
for index, input_cell in input_table_1['Image'].iteritems():
# get image from cell
image = input_cell.array.astype(np.uint8)
# define the command for starting tesseract
pytesseract.pytesseract.tesseract_cmd = r'/usr/local/Cellar/tesseract/4.1.1/bin/tesseract'
# extract the text from images
result = pytesseract.image_to_string(image)
output_column.append(result)
try:
output_table_1['Extracted Text'] = output_column
output_table_1['Success'] = True
output_table_1['Error Message'] = None
except Exception as e:
output_table_1['Extracted Text'] = None
output_table_1['Success'] = False
output_table_1['Error Message'] = str(e)