I have returned! A little wiser, but not wise enough to not need to seek help again. KNIME is fabulous, unlike this user!
I have a table called {Medical}. It contains each new diagnosis/stage entry has a Diag_Code (the site, e.g., 'prostate, ‘breast’), a sequential MED_ID and a Diagnosis_Class=1 and a DxDate.
It also contains each recurrence diagnosis/stage entry which also has a Related_MED_ID (the value of the MED_ID of the original diagnosis/stage entry), a DxDate, and a Diagnosis_Class NOT 1 (3, 5, 7 for example).
Patients can have 0, 1, 2, 3, 4, …n recurrences (all are Diagnosis_Class NOT 1) which can only ranked by Dx_Date (first recurrence has an earlier diagnosis than the second recurrence which is earlier than the third, etc; the Related_MED_ID will not work reliably for this).
-
I want to pull out the original diagnosis
(I have done this by pulling entries from {Medical} with Diagnosis_Class = 1). -
I want to pull out the first recurrence diagnosis
(I have done this by pulling entries from {Medical} with NOT Diagnosis_Class = 1, and then GroupBy Related_Med and Diag_Code, with minimum(Dx_Date) in the manual aggregation tab). -
I want to pull out the second recurrence diagnosis … now I am stuck!
I can’t find a way to identify the second recurrence reliably. I can select the first using the minimum(Dx_Date) in the manual aggregation tab, and the last using the maximum(Dx_Date) in the manual aggregation tab. I could assign a position to the last recurrence by using a group count (if there are four recurrences then the maximum date one must be #4), but #2 and #3 are defeating me.
My question is: if I have the original database dump listing all of the recurrences (a unique MED_ID, a Related_MED_ID (that groups the recurrences), and a Dx_Date (that orders the recurrences), how do I add a new column into which goes a number indicating the temporal position (earliest to latest) of the recurrence within the Related_MED_ID?
It should end up like this:
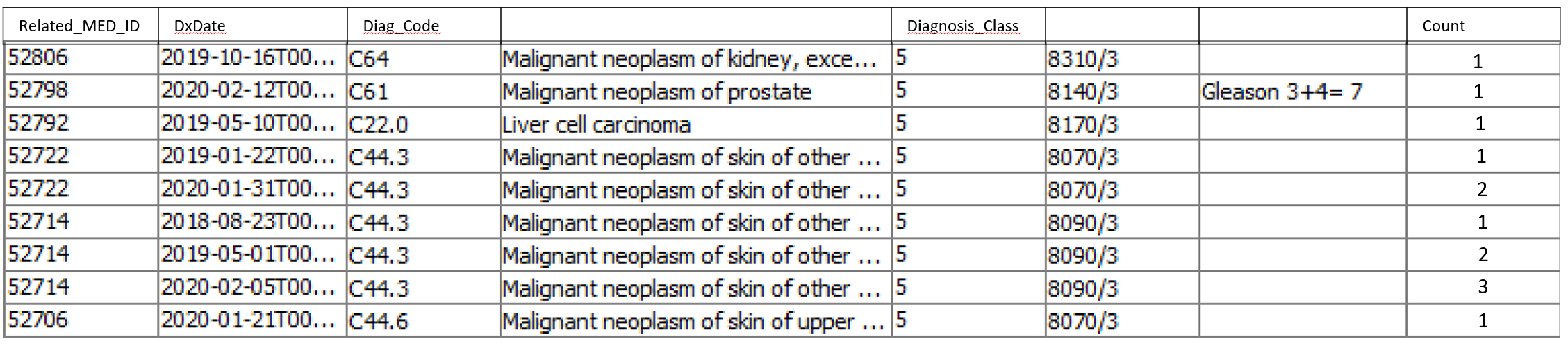
I am grateful for previous help.
A
