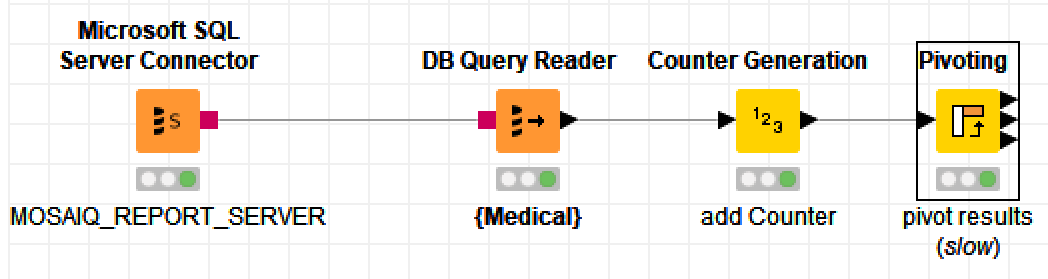
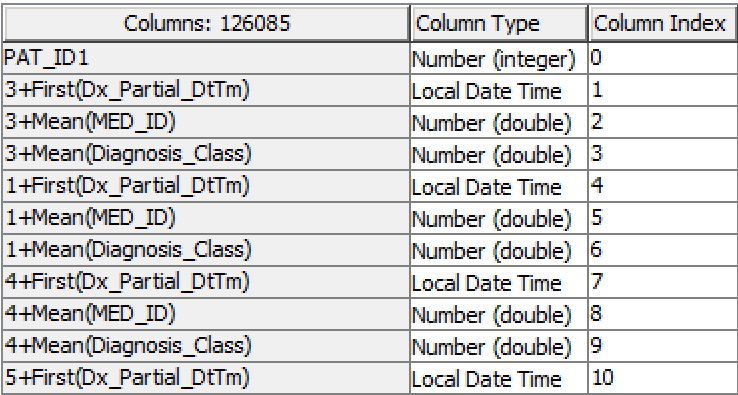
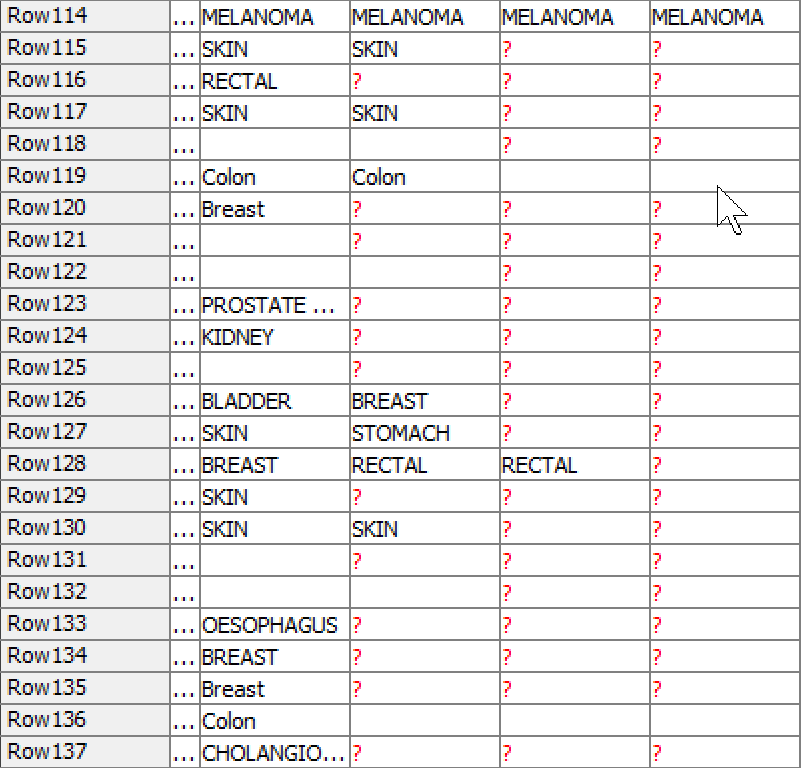
if I got you right you can use Counter Generation to add unique id to every row. Then use Pivoting node where group column is PAT_ID1, pivot column is you newly added column and aggregation columns are MED_ID, Dx_Partial and Diagnosis_Class with aggregation first. To avoid getting awkward column names use following setting in Pivoting node:
Hope this helps! If any questions feel free to ask.
Here are three pivoting screenshots showing the configurations for group by PAT_ID1, pivot by counter and aggregation by MED_ID, Dx_Partial & Diagnosis_Class:
I’m sry. I was only looking for one case. So you should add Rank node after Counter Generation node. There you define your Ranking Attribute as Counter column with Ascending option and your Group Attribute as PAT_ID1 column. Now in Pivoting node instead of Counter column use newly created rank column as pivoting column. This should hopefully work
Thank you for the modification. Being somewhat of an ‘IT-idiot’, I can appreciate the difference in your instructions though I would never have achieved this workflow.
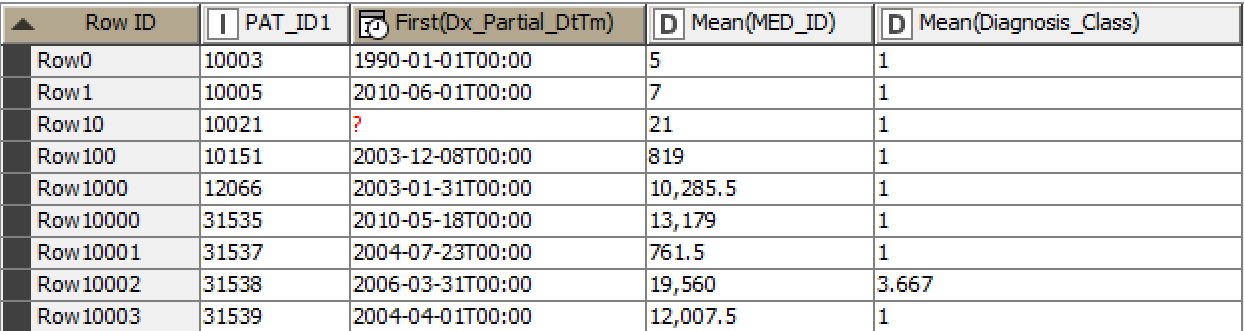
It is working! I had to strip out almost all of the columns so that I could appreciate it working, but it is working. The items are listed in date sequence (earliest at the left) as expected.