I have to deal with events and an over all status of a production machine. If everything works fine, I could use a moving aggregation node over a row-based rule engine provided status. (To make it easy begin-event = 1, wait-event = 0 and end-event = -1). Normally I only have 1‘s and 0‘s in my overall status, but for some unidentified reason, the machine is missing the begin-event and the overall status runs to -1.
Now I have no idea how I can do a cumulative sum with only positive values. If it runs to -1, it should stay at 0.
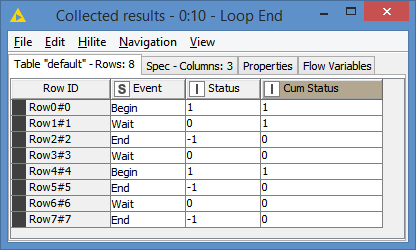
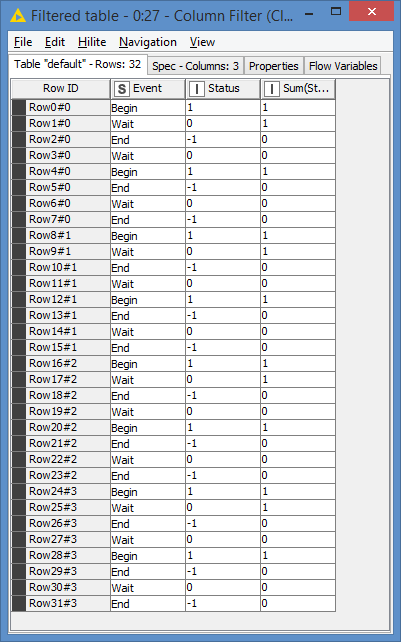
For example:
Event, Status, Cum Status
Begin, 1, 1
Wait, 0, 1
End, -1, 0
Wait, 0, 0
Begin, 1, 1
End, -1, 0
(Begin event is missing)
Wait, 0, 0
End, -1, -1 <— should be 0
This happens only once per month, but crashes the whole result.
Hi @mabm , I’m not sure I understand the logic that you are explaining.
Based on the data, the -1 is the expected results. Why should it be 0 instead of -1?
The Cumulative Status is adding that Status at each line. At each line, it takes the Cumulative Status of the previous row and adds it to the current Status value (previous Cum Status + Status). So, if we were to look at the calculation at each line, it would be something like this:
Event, Status, Cum Status
Did you mean that is how you expected Knime to behave, or rather that’s the result that you are looking for?
I originally thought you meant the former, but the more I am reading this and adding the title with that, I’m now thinking that you meant the latter.
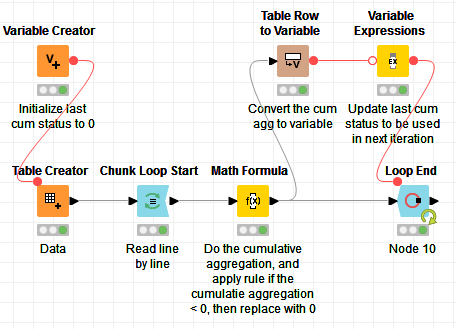
If that is the case, so yes, Knime will give -1 with a Moving Aggregation. If you want to add logic if the cumulative sum is -1 then it should be 0, you can’t really do it in the Moving Aggregation node, at least I don’t think so.
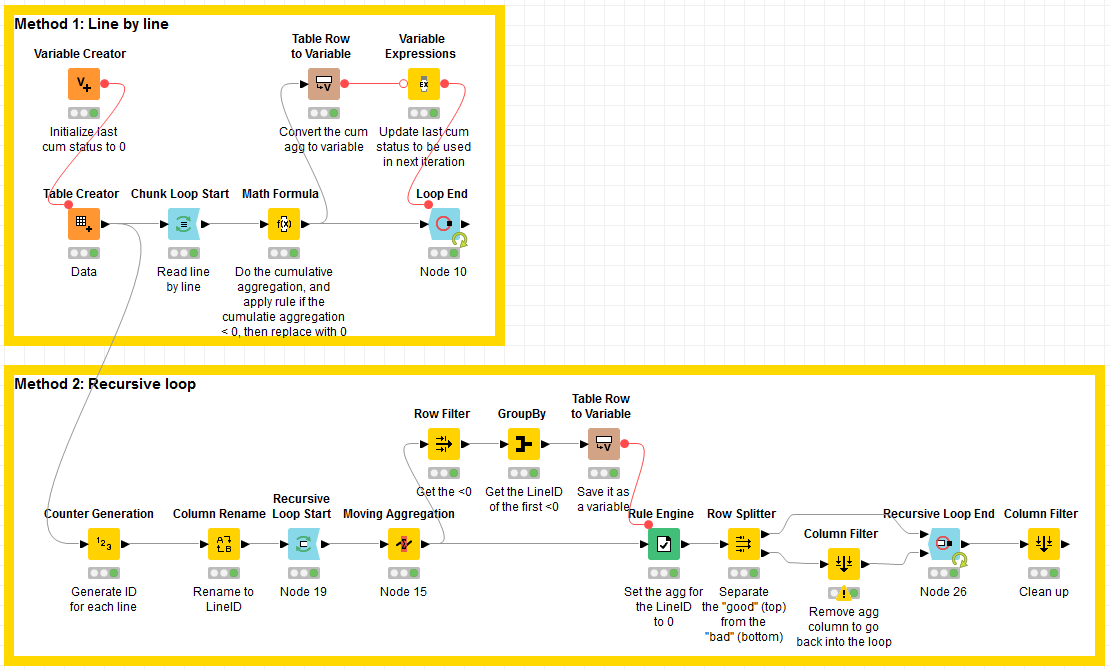
You would have to compute the cumulative sum line by line and apply the rule line by line.
Hi @mabm , yes it is expected to be slow, as it’s reading 1 record at a time unfortunately, but it is guaranteed to work.
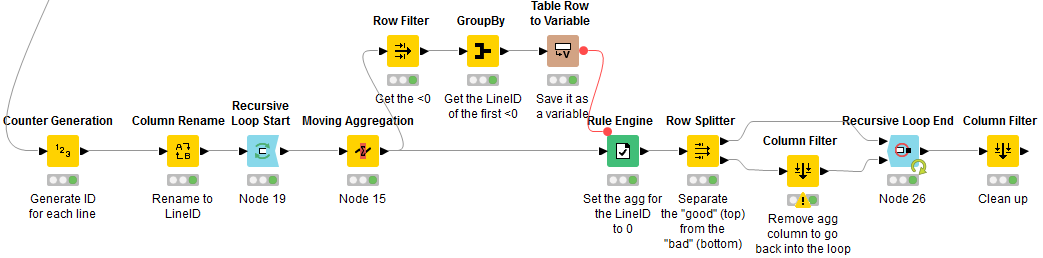
The only other way that could be faster, but more complex would be with recursion. The logic would be to recursively do the following:
Set start_row = Row 0
Start Loop
Do Moving Aggregation starting from start_row
Get Row number where the first <0 aggregation, let’s say Row n
Update aggregation to 0 for Row n and set start_row = Row n
Loop until no more <0 as aggregation
So, the logic would be that most rows would be processed at once. It does not need to process all lines individually, but only a few. The less there are cases of <0 the faster it will execute.
But as you can see, it involves quite some steps, and step 3 is not straight forward.
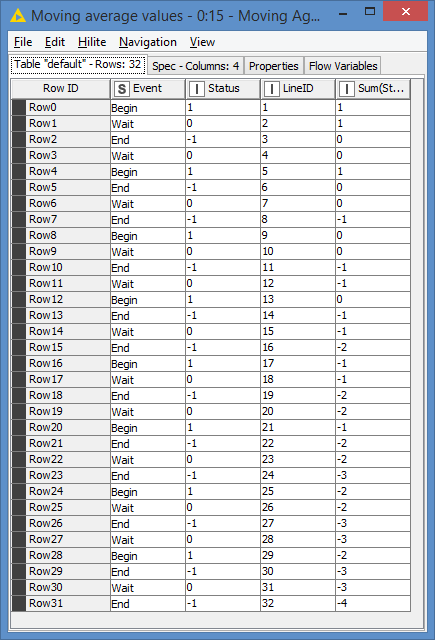
I ran the workflow with a test set. In this test set was no “error” and the status is not getting -1. In this case the min(LineID) is 0 and everything will be set to 0 or was it a implementation error?
On the whole set it is incredible fast. And is working like charm.
Hi @mabm , oh right, if there is no <0 it looks like it will not “qualify” any records lol.
Sorry about that, so I changed the Row Splitter to a Rule-Based Row Splitter, where I also added the condition for min(LineID) is 0. It’s all good now.
EDIT: Just to clarify, the updated workflow will work for both cases, that is if there are no <0 or if there are <0. Please test with your test set and with your whole set
Hi @bruno29a
Thanks a lot.
In the newest data I saw, that things can ran more worst than expected.
The machine data is missing the begin more than one time in a row. Therefore the status is decreasing to -3 right now.
I will prepare a dataset to share, if it is ok for you.
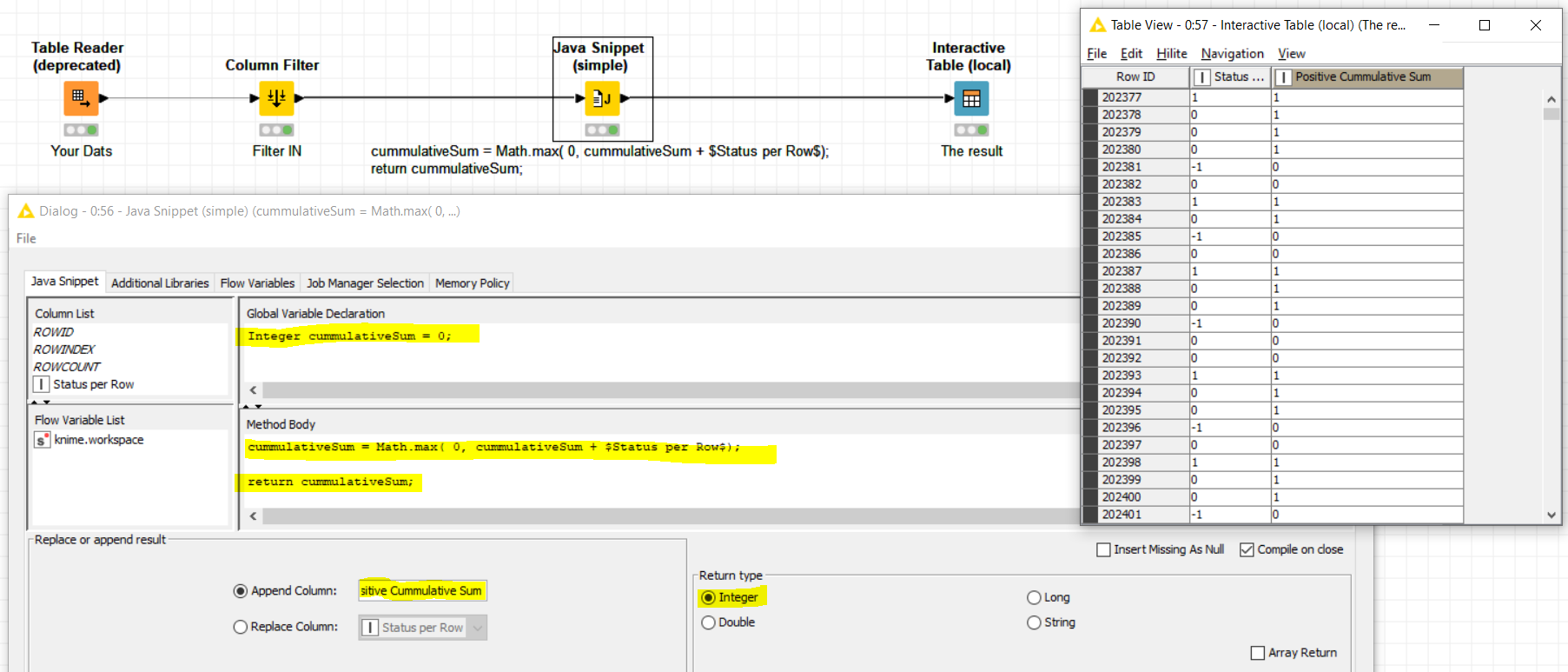
As @bruno29a, I always try to provide a solution purely based on KNIME nodes, without other languages coding. However, I have to say that in this case, a scripting node may be the most appropriate solution to go for. If I understood well the problem you want to solve is a 0-truncated cumulative sum, or in other words, whenever the cumulative sum becomes negative then it is truncated to zero.
Please find a possible solution based on the -Java Snippet (simple)- node:
Hi @mabm , it does not matter how many missing “Begin” you have in a row (I’m assuming you mean consecutive), the workflow should still work the same way.
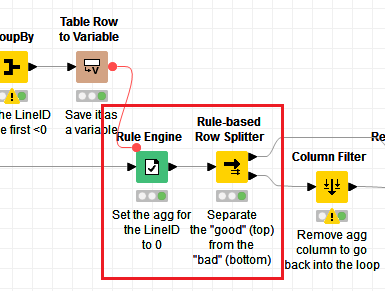
Looking at your workflow, there are no <0 (no -1, nor -2, nor -3). However, you are not using the latest version that I provided, so it is not taking into account the correction that I added, which is handling where min(LineID) is 0. This is an important part of the logic and it’s not just for the beginning of the whole dataset, but rather the beginning of each batch in the loop.
Without this, it does not know how to skip a loop properly, hence why you get 0 all the way after line 48375. If you use my latest version of the workflow, it corrects this issue. The main changes are these 2 nodes that you need to replace:
The most important one is the Row Splitter. For the Rule Engine, it’s a bit more optimized.
You also do not need the Integer Widget which simply contains the variable “last_cum_status”. This variable was only needed for Method 1.
I like @aworker ‘s approach, which is basically doing what my Method 1 was doing, but without needing to loop into 1 line at a time. I keep forgetting about the global variable. It’ up to you if you want to use pure Knime, or if you want to use scripting.
Thanks for your comment. I very much appreciate your different solutions and all the effort and pedagogy to implement them. I think they are great for people to learn how to implement an algorithm in general and discover/use new KNIME nodes in particular. I still find amazing how easy things to implement in other scripting languages are sometimes difficult to implement in KNIME and indeed, viceversa. But I guess, if everything were easy to implement in just a single language, we would be all talking the same language. N’est-ce pas lol?