I’m curious how to use KNIME to find out optimal strategy to play ‘Guess who’ game. Let’s say I have a table (rows are persons) with names and some characteristics (columns) that describes persons and can be found by question and binary answer (yes/no, i.e. brown eyes, long hair, etc). I tried to use binary DT (name as a target) at default settings but it doesn’t provide optimal (the shortest) sequence of questions to identify persons from the table - I forced more common question as the root split and obtained a shorter tree. Am I missing something?
This is interesting and I don’t believe I’ve seen anyone create a KNIME workflow for this purpose. It would be interesting to see your workflow and dataset if you’d care to post it.
That said, I don’t know that a decision tree in this case is always going to provide the shortest sequence of rules for identification - it’s trying to be as correct as possible. But I’m just thinking out loud here, so maybe I’m missing something.
You might need some algorithm to sort out the shortest sequence with some limitations. Some Googling brought me to this collection without being immediately able to identify the right one. It is very possible you might have to employ some Python code to achieve this.
Thank you for your interest . I uploaded the dataset guess_who.xls (34.5 KB)
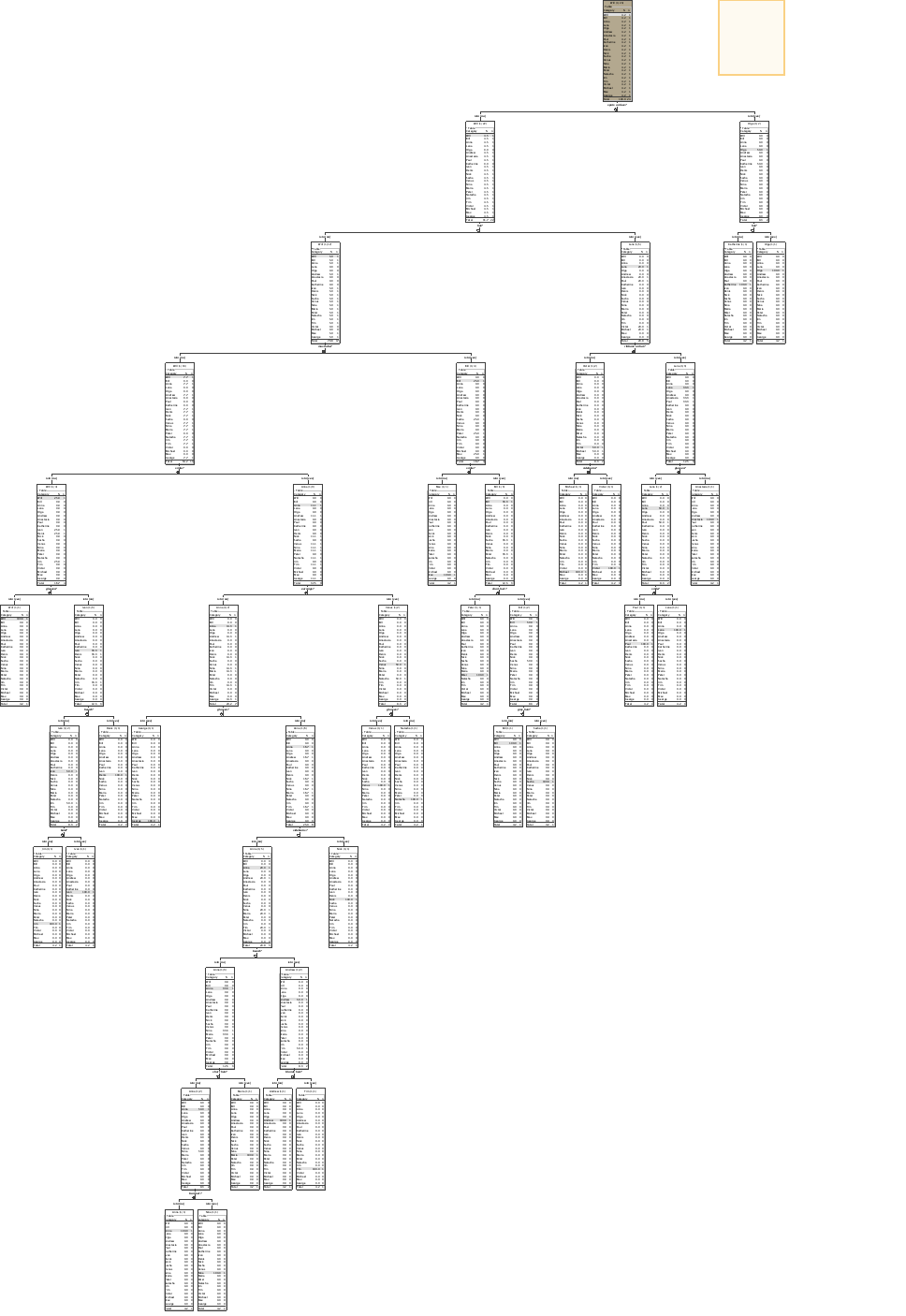
I also think that I have to apply some optimization tool to that DT model in KNIME but have no idea about which one - thank you for ideas and links. I don’t understand what is the reason why DT looks like that by the default (see pic - it has 2-10 levels). Maybe somebody can explain or provide links to read about it (sorry, I’m not a data scientist)?
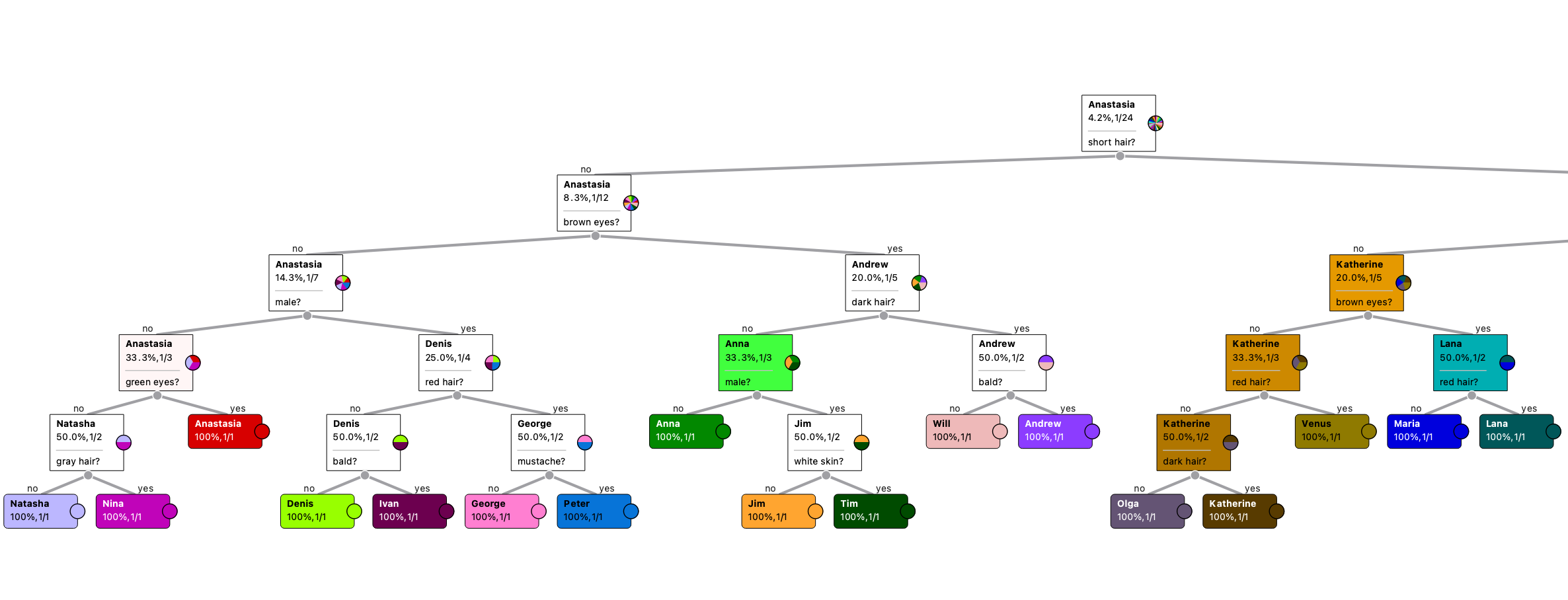
I also tried to analyze the dataset in Orange at default settings and obtained much better results (see the pics - there are 5 levels, the tree is wide and of the same depth).
Regarding the game rules the DT from Orange allows me to identify every person from the dataset in 5 questions. However the DT from KNIME allows me to identify some person within 2 questions but some other persons in 10 questions.
So know the question is what tools/setting should I apply to make KNIME DT shorter and wider? Any ideas?
The default settings for the Decision Tree Learner aren’t quite specific enough to do what you want here. Having said that, you can use the Tree Ensemble Learner to force an ensemble with a single tree, and limit the tree depth to 5.
Maybe it’s worth playing around with that node, which has tons of customization options, to see if you can get something closer to what you want.
thank you @ScottF
Indeed, when I used Tree Ensemble Learner with Split Criterion changed to ‘Information Gain’ I obtained a lot of various tree solutions within 5 levels. Well, it’s time to dig in algorithm and method details to investigate different solutions. Thanks again!
 . I uploaded the dataset
. I uploaded the dataset