Hola, quisiera mejorar mi modelo de regresión lineal múltiple, eliminando las las variables con mayor valor p, pero no se como hacerlo. Tengo columnas de tipo string y trate de hacer con one to many pero los resultados son muy raros, usando ese nodo. Alguien tendrá alguna idea? Gracias.
Hola @Eliseo y bienvenido al fórum de KNIME!
¿Te sería posible compartir el workflow con la data? Nos seria más fácil de esta manera el poder ayudarte. Gracias de antemano.
Saludos
Ael
1 Like
Regresión Multiple Contratos.knwf (17.1 KB)
regresioncontr.xlsx (921.1 KB)
Gracias a ti por responder, convertí el .csv en xlsx, ya que no me dejaba subirlo.
Hola @Eliseo,
Gracias por subir los datos. Los he cargado con el workflow y analizado, pero desde mi punto de vista no hay señal suficiente en los datos para construir un modelo de regresion suficientemente predictivo (por encima de un R^2 de 0.40 para empezar, por ejemplo). Es solo mi punto de vista. Quiza otras personas del forum te puedan ayudar mejor si piensan lo contrario y propongan una solucion.
Suerte,
Ael
Hola @aworker, gracias por tu ayuda
Disculpa, estoy en fase de aprendizaje.
Entonces, ¿si es menor el R^2 a 0.4, no es recomendable realizar una predicción?
¿Puede ser que deba realizar algún tipo preprocesamiento a los datos para que resulte mejor?
Gracias.
Hola @Eliseo,
No te preocupes, todos estamos siempre en fase de aprendizaje.
Voy a darle la vuelta a la pregunta para que la respuesta sea más comprensible. Según comprendí, lo que quieres predecir es el sueldo de las personas en función de un cierto número de parámetros. Me dirás por favor si me equivoco. Olvidemos el 0.4 de R^2 y también la pertinencia de las variables por el momento. La pregunta que hay que hacerse en este caso es:
¿Qué error de salario estoy dispuesto a aceptar por parte de mi modelo de predicción, por ejemplo, un 5%, un 10%, un 15% de error medio? Si uno de estos es el error medio aceptable, ¿a cuánto corresponde este valor en R^2? ¿Y para los otros estimadores?
Imaginemos que el error de predicción sigue una distribución Gaussiana con una media centrada sobre 0 y una desviación típica (Std) correspondiente a un 10% de error. Esto se puede simular en KNIME, y ver de manera experimental cuales son los umbrales estadísticos para R^2 (u otros) más allá de los cuales el modelo no se puede considerar fiable.
Según las simulaciones que he hecho, un error medio del
10 % en la predicción corresponde a un R^2 = 0.98
20 % en la predicción corresponde a un R^2 = 0.95
50 % → R^2 = 0.70
……
70 % → R^2 = 0.42
La calidad del modelo lineal que estas utilizando es de R^2 = 0.27, muy por debajo de estos valores.
Este problema de calidad no es debido solamente al hecho de utilizar un modelo lineal. Hice pruebas con tu data y modelos no lineales que hacen implícitamente selección de variable y no fueron mejores, con lo cual deduzco que las variables, todas ellas o un subconjunto optimizado de ellas no son suficientemente predictivas. Siento llegar a esta conclusión. Pero quizás otros participantes del fórum se interesen a tu problema de predicción y puedan demostrar lo contrario. Me alegraría que así fuera.
Suerte y saludos,
Ael
1 Like
Gracias por tu respuesta.
Específicamente es la variable “años en la empresa” la que quiero predecir, ya que, se quisiera obtener cuanto duraran los empleados en sus empresas. El contexto es que es una base de datos de contratos de varias empresas ya que, esta empresa presta servicios de recursos humanos mediante una aplicación (no puedo decir cual). Dicha base de datos, la pre procese y elimine los registros que tuvieran al menos un “missing value”, ya que, se me pidió que ojala no se inventaran datos y no se sesgaran. Entiendo tu conclusión, ¿Puede ser que falta borrar algún dato que este fuera de lo normal, como outliers? Capaz que no sea conveniente.
También en paralelo, estoy probando si puedo predecir con estos mismos datos una clasificación binaria, ya que, los tengo etiquetados en renuncia y no renuncia. Probé utilizando arboles de decisión, bosques, knn, ann, regresión logística y bayes ingenuo. Modificando variables, siempre obtuve de los arboles y bosques sobre un 80%-85% de precisión, los demás aprox. 70%. También intente optimizar parámetros para mejorarlos, ¿Sabes hasta que punto uno puede decir, este modelo es el definitivo? He escuchado que también usan cross validation, pero no tengo claro como ejecutarlo. Si es que me puedes echar una mano con eso también, estaría muy agradecido.
Hola @Eliseo
Gracias por la precisión. El problema de KNIME cuando se provee el workflow sin los datos (o con los datos separados) es que cuando se vuelven a integrar, a veces los parámetros de configuración cambian y KNIME no me proponía una columna a predecir coherente. Elegí entonces la que me pareció la mas probable. En ese sentido, por favor, cuando subas los protocolos, hazlo con el protocolo ejecutado completamente, para que no haya dudas. Al exportar el protocolo, por favor asegúrate que la opción “Reset Workflow” no está seleccionada.
Aun así, probé con “años en la empresa” y obtuve resultados similares que no son de calidad suficiente. La conclusión sería la misma.
Con respecto al problema de clasificación, ¿te sería posible subir los datos con la columna “renuncia” y “no renuncia” y explicar como la generaste? A partir de ahí, intentaré ayudarte.
Saludos
Ael
Hola @aworker, muchas gracias por tu ayuda.
Primero, elimine registros que tuvieran información mal puesta o que tuvieran missing value. Después, clasifique estos datos gracias a las columnas “motivo de termino”, “fecha de contratación” y “fecha de termino”, lo que hice fue que simular que estábamos antes de la pandemia en chile (ya que no estamos en condiciones normales y gente podría haber renunciado por estos motivos, mi idea es que se aplique el modelo cuando la pandemia este reducida). por ello, saque los que iniciaban su contrato después de la pandemia y puse a los que tenían un contrato previo pero que finalizaron después como que permanecían aun en la empresa y los que ya se habían salido de la empresa dejarlos como renuncia a los que habían renunciado y saque a los que terminaron de forma normal y despidos (si no se entendió algo me dice por favor). Después de eso los coloque a los modelos, teniendo variados resultados en la precisión, siendo mejores los de arboles de decisión y bosques aleatorios.
Aclaro que antes había probado con 2 columnas menos, porque agregue a “tipo de contrato” y “distancia”, siendo este ultimo rellenado con el missForest. En ese entonces, tuve mejores resultados en los demás clasificadores, pero siempre siendo inferior a los arboles y bosques aleatorios.
https://drive.google.com/drive/folders/14Dzweo-zjROtCHbyL5srYbzog9Apcv89?usp=sharing
Hola Eliseo
Gracias por las explicaciones y por subir los datos. Hoy es fiesta nacional aquí (Francia) y el resto de la semana estaré de viaje de trabajo. Bajaré los datos y empezaré a analizarlos a partir del lunes. Espero que no sea demasiado tarde para ti. Entre tanto, quizá otros Knimers del fórum querrán ayudarte también.
Suerte y hasta pronto,
Ael
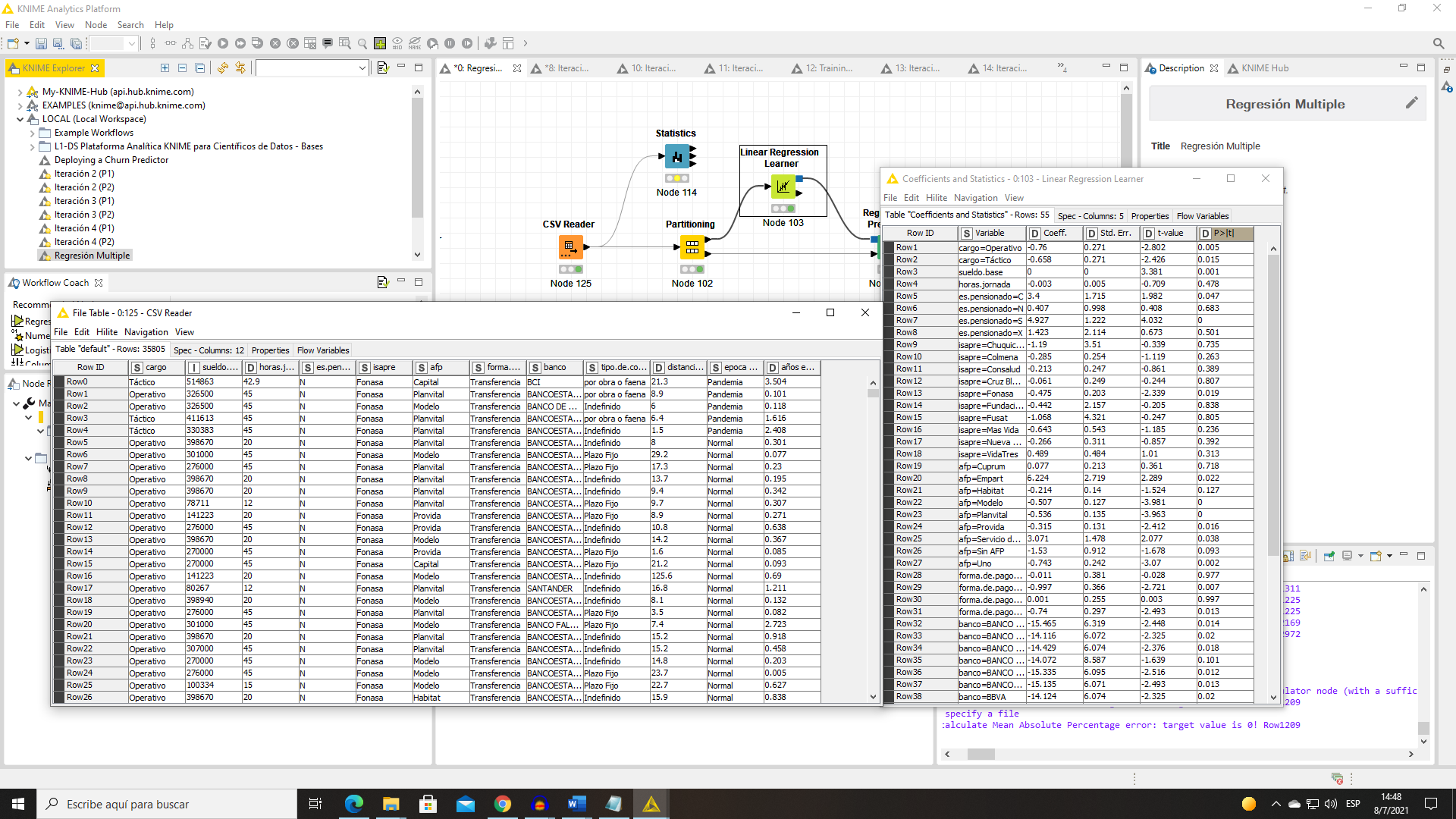
Hola @Eliseo. Examiando los datos de tu variable de respuesta seria bueno que explicaras como los calculaste pues hay algunas cosas qeu llaman la atención:
Hay un outlier (con un valor cercano a 1000 años en la fila 23166). Tienes valores negarivos y la mayor parte de los valores son inferiores a un año:
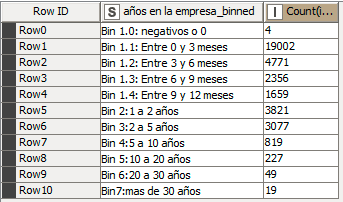
Si se examina el detalle de los valores entre 0 y 3 meses este es el histograma:
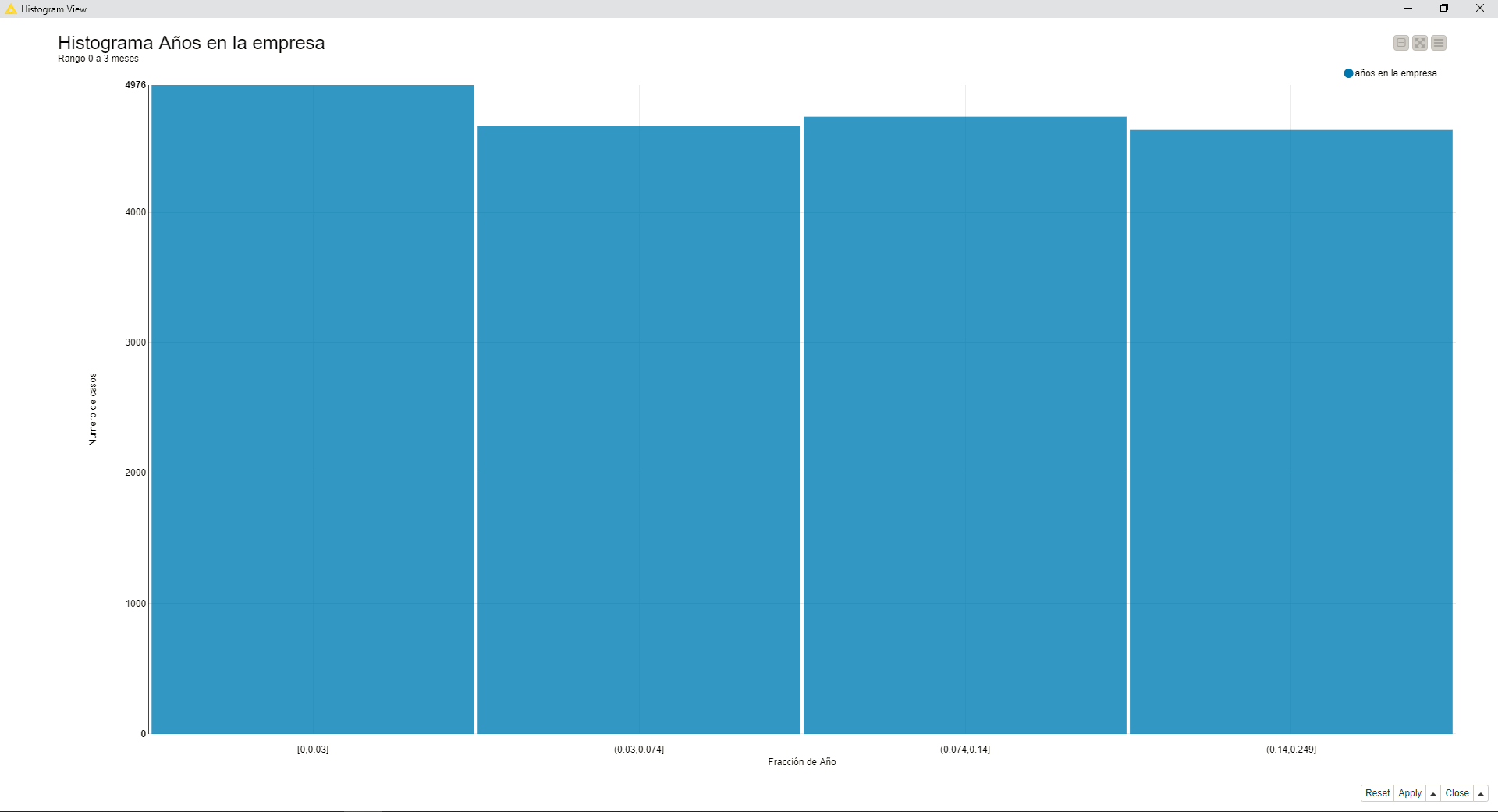
Llama la atención que la cuarta parte de los valores están entre 0 y 0.003 de año que corresponde a 10 dìas. Tienes 244 casos con exactamente 0.0 años.
¿Como se calculó la columna de años en la empresa?
Gracias por tu ayuda @aworker no se preocupe, felices fiestas.
Saludos.
Hola @iperez, gracias por responder.
En los datos hay dos columnas, “fecha de contratación” y “fecha de termino” y se calculo “años en la empresa” en base a esas dos columnas, ya que, esa es la diferencia en años que presentan estas. Ahora bien esos valores (1000 y 0 años) recientemente los elimine con un row filter, porque me di cuenta de lo mismo y deben ser datos mal puestos desde su fuente. Cabe recalcar que esta base es de varias empresas y que esos contratos puede que hayan durado poco tiempo o simplemente llevan muy poco tiempo en la empresa, no sabría mas detalles de porque estuvieron poco tiempo.
Entendido. Puedes compartir tu base definitiva?. Los valores muy bajos como 0.003 no suenan razonables. A priori, y sin conocer el problema yo eliminaria los de menos de 2 o 3 meses pero no tengo el contexto.
Si, no hay problema, también compartí el flujo.
https://drive.google.com/drive/folders/1DeHU2ZV2Pf4__I3FPc6it_3YSHvAioD4?usp=sharing
El contexto, es que se requiere saber cuando un trabajador renuncia de las empresas que son clientes a la dueña de base de datos, ya que este ultimo ofrece servicios de recursos humanos como gestión de contratos, marcaje, remuneraciones, etc… Con la regresión lineal, la idea era predecir cuantos años estaría en la empresa el trabajador. Y con la clasificación, busco predecir si es probable que renuncie en el momento en que se administre el nuevo dato. Quería comprobar si estoy realizando bien el procedimiento y si con la precisión y la precisión media que entrega la validación cruzada, basta con decidir el mejor modelo para este caso.
1 Like
Hola @Eliseo. Gracias por tu explicacion. Estoy mirando los flujos y mirando los datos. En tu flujo P1. Te sugiero revisar si la opcion correcta es hacer un inner join, si miras la curva ROC al interior (por ejemplo) del metanodo de Regresion Logistica y en el flujo general no coinciden, estas dejando observaciones por fuera en el joiner. De otro lado, ¿tiene sentido de negocio tratar de hacer un pronostico como el que quieres para los contratos del tipo “Plazo Fijo” o por “obra o faena”?. Igualmente ¿los casos con 50+ años en el cargo son razonables desde el punto d evisata de negocio?.¿ Tiene sentido de negocio incluir las duraciones de 1, 2 o 3 dias?. Sigo mirando el tema
1 Like
Hola @iperez, gracias por tu alcance, yo creo que tiene sentido ya que, un empleado puede renunciar a los pocos días, de su trabajo. Hay datos de 50 años hacia abajo, con el filtro, no de mas, aunque no son muchos los casos que son de muchos años, podrían ser outliers?. Lo de los tipo de contrato, me cuesta buscar un explicación, pero como es una característica del que tiene el trabajador, encontraba interesante añadirlo en este caso. Muchas gracias por su ayuda.
Hola @Eliseo
Disculpa que no te haya respondido antes. Me alegra que @iperez haya podido ayudarte en analizar los datos entre tanto. Sus comentarios me parecen muy interesantes ya que la calidad inicial y limpieza de la data es más importante que el modelo.
En complemento a lo que @iperez ya te recomendó, aquí adjunto te envío un análisis por Decision Tree que muestra que en tu caso las dos variables más informativas son el -sueldo.base- y los -años en la empresa-.
En este workflow se demuestra que limitando (regularizando) el numero mínimo de muestras por hoja del árbol, se llega a un modelo muy simple de 5 reglas basadas únicamente en el -sueldo.base- y los -años en la empresa-. Este modelo es tan bueno (sin diferencia significativa) como los otros modelos que ya probaste, ya que andan todos alrededor de un ~0.8 de Accuracy. Sin estas 2 variables, tu modelo no pasaría un 0.6 de Accuracy en el Test Set. Esta idea simple se puede mejorar evidentemente, pero la comparto tal cual para que veas que puedes poner facilmente en práctica con KNIME un modelo predictivo con reglas simples a implementar y comprender:
Con respecto a implementar una validación cruzada, evidentemente siempre será mejor, pero en tu caso, dispones de suficientes datos para ya de por si estar seguro de que el resultado que obtienes de Accuracy de aproximadamente 0.8 es fiable. Los resultados medios por validación cruzada no debieran ser significativamente diferentes.
20210720 Pikairos optimizar regresión lineal.knwf (625.5 KB)
(El workflow está reseteado pero contiene los datos al interior)
Espero que estas explicaciones te sean de ayuda.
Saludos
Ael
4 Likes
Muchas gracias @aworker, por tu post. He llegado a la misma conclusión y gracias por ayudarme con este tema, estoy agradecido.
Saludos cordiales.
1 Like