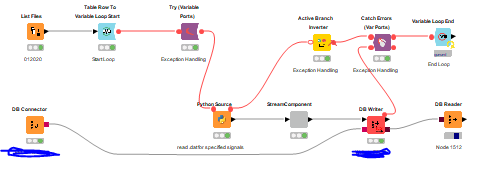
this takes VERYYYYYYYYYYYYYYYYYYYYYYYYY long.
(one day has ~86400 records, so one month…)
May someone suggest tips on how to speed up this process if possible?
in the DB Writer I have set up a batch size = 100, it is using streaming (virtual chunks = 1)
I am worried about the chunks and the batch size skipping records, hence why I kept it low. (I tested both and when higher it skipped)
It is very difficult to say what is going on. Could you provide us with more details especially about what kind of database you are using and where exactly the delay occurs.
If you have a streaming of 1 ? and a chunk of 100 could this result in a situation that would only write 1 line per operation.
And the way you have wired the loop it seems that the DB Reader is reading the (whole?) database at each iteration. Are you sure that is what you want or what is the purpose of the DB reader on the right.
Hi @mlauber71,
Sure!
I am using mysql database, Microsoft SQL Server,
As for delay, occurs when running, it has been running 24+ hours,
To be fair, I am running like a farm, 13 setups,
Python takes a lot of my CPU processing, (could it be my processing power?)
List files is reading a months worth of data, then python source picks out the needed info from the .dat file, then the component does manipulation to the data then it is written to MySQL DB as a table,
WOAH - so is that good or bad? Would a higher number skip? I just want everything accounted for,
Hmm difficult to judge from the screenshots. One idea could be to first collect all of your data locally and then load it into the DB in one single step.
Also if you have 13 parallel sessions accessing the DB from one account it may well be that the configuration would slow that down (only accepting a certain number of connections at one point) - another question would be the connection. How is the DB you are trying to write to connected to your system.
Then you mention you write to a MySQL DB. Is that a remote one or one on your machine. And what configurations are there.
In general you should think about your setup and reduce the number of DB operations to a minimum. You could see if certain calculations in KNIME can be done in memory - depending on your systems RAM.
You would have to identify which nodes cost the most time in oder to do something about it.
And here we have a list of discussions and blog entries about KNIME an performance. You might want to take a look if something strikes you as an idea to explore further.
I have considered running one setup, it can read a folder for a year then the sub-folders which have months and inside the .dat files, it has the maxIterations combined, I thought maybe 13 setups would speed it up … sounds like i am doing the opposite?
It takes a while in the python source,
The MySQL is connected thru a connection source path
You mentioned this: “some method in place to log the current status and be able to restart at a certain point. Eg. write results to disk after each 50 out of 900 processed files or something.”
this is good,
how would you do this in knime?
Mostly agree with mlauber71 and we can only give general advice without knowing more.
In general: looping in knime = terribly slow and should be kept to minimum and loops small and simple. My experience at least. I would load only the data within the loop and do the rest outside of the loop. Second possible issue is the Python source. Simply said after you have your data it will have to be serialized and imported into the JVM so that knime can work with it. So if possible I would find a way to read the data directly.
And then of course the database itself matters (how it is configured) and how you connect to it. Especially with mysql I would check if you are using innodb or myisam. And what data are you writing? string and numbers or clob/blob data?