Hi, I’m trying to do an analysis on binary, very rare events (0.3% probability of occurrence). I’ve tried logistic and random forest predictors, and they both predict 0 events with 99.7% accuracy. I’m assuming the algorithms are optimizing on accuracy. Are there other options to optimize? The two things I care about are:
of true positives (more the merrier)
True positive/positive ratio (closer to 1 the better)
Its clearly you are dealing with an unbalanced dataset. There are some techniques to to handle this. See e.g. this article on KD Nuggets. But there is a lot more on the KNIME forum if you search for “unbalanced data”.
Hi @montecarlo,
I’ll just had a few KNIME specific comments here as well, perhaps it will help you start your search!
Some common options for dealing with unbalanced data like this, as the article @HansS linked suggests, included over-sampling your minority class, under-sampling your majority class, or adjusting a classification threshold of your model.
1) You may try oversampling your minority class with the SMOTE node, this generates new artificial data points instead of just re-sampling. https://kni.me/n/YznaX_v45d3OzPEV
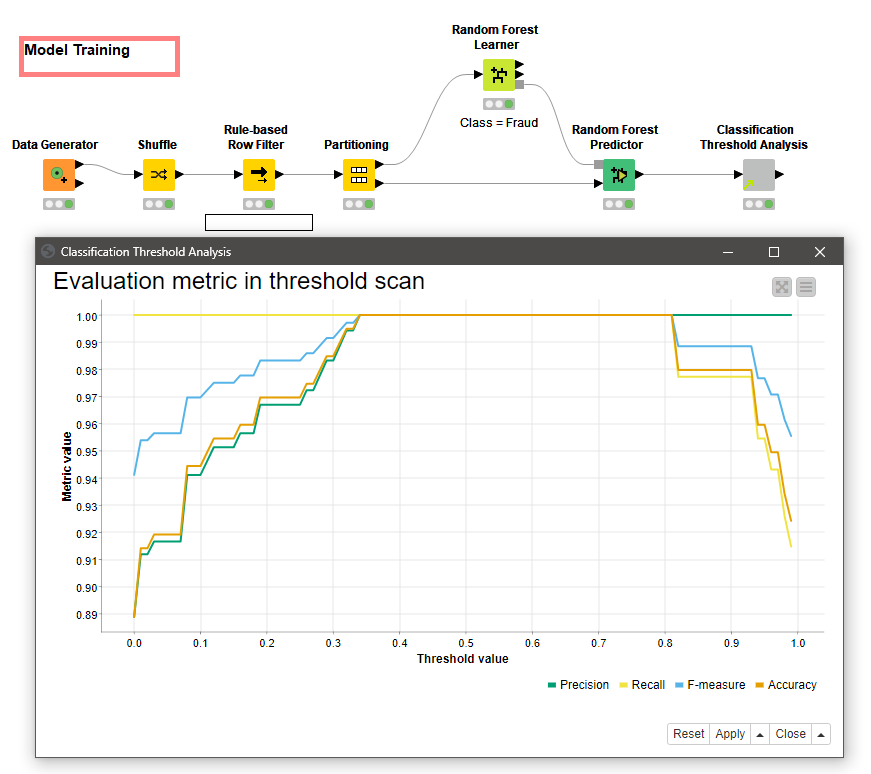
2) Another thing you may want to try out is this new component that we’ve recently released, the Classification Threshold Analysis. You can use it with any model that outputs a probability as well as a classification, such as the random forest.
What it will do is generate different statistics for your model based on a changing classification threshold. For example you may want to classify something as your minority class even if the model only gives 5% probability, this is another way of dealing with unbalanced data without changing your sampling. https://hub.knime.com/knime/space/Examples/00_Components/Guided%20Analytics/Classification%20Threshold%20Analysis
3) And finally to address the question on optimizing for metrics other than accuracy. You won’t be able to adjust that kind of thing in a learner node but the Parameter Optimization Loop nodes can be set to optimize hyper parameters by any metric you choose, such as precision, see this example on the hub! https://kni.me/w/dXpLM-QbwblHGXQe
Hi! Using SMOTE helped with the random forest. What’s worked best so far for me is logistic, and instead of looking at the prediction, I just look at the probability of an event. I found a substantial subset where events had a 1.5% probability, significantly higher than the average. I’m hoping to tune the model and get it up to 5% probability.
For the Classification Threshold Analysis, it’s not clear to me which nodes that goes in between?
It’s just a quick way to how some common metrics change with your classification threshold, that being the probability cut off for choosing one class over another.