Hello everyone,
I have been trying to make a workflow that analyses a given library for similarity distance distributuion. The workflow I came up with works like a charm for smaller libraries, but my actual use case for it is to analyse sets of 10k+ compounds, and here is where it struggles.
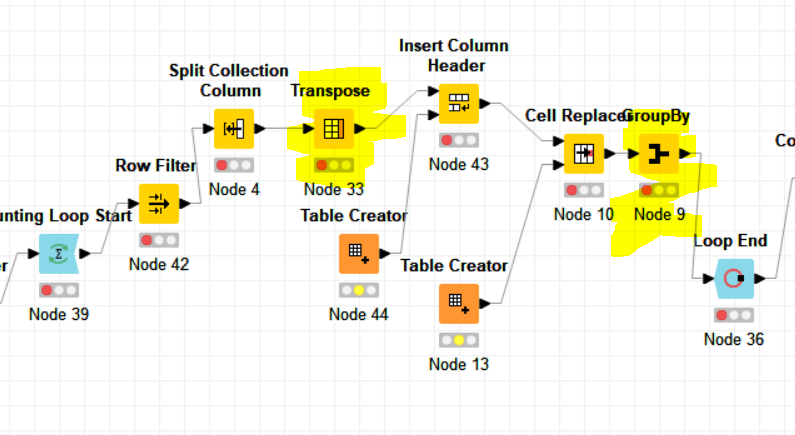
For example, I left it running overnight on a library of 40k compounds, and my loop count only got to a thousand. I have noticed that the Transpose node is likely the rate-limiting step in my loop, when working with these bigger libraries. Is thete a way to avoid using it in this case?
I have attached a workflow to this post, and would be really grateful if someone took a look at it and pointed me at what exactly am I doing wrong. Similarity distance.knwf (454.6 KB)
I had a quick look at your workflow and although it is difficult to evaluate what is going on without data, I’ll focus on your hint about the transpose node. Indeed, transposing tables are very CPU & time consuming in KNIME. This is basically because of the way tables are organized in KNIME. I would try to avoid it whenever is possible.
In your case, I saw that you are transposing and then doing a groupby of the transposed data, among other things in between. I wonder whether this could be achieved using the “Column Aggregator” node (which groups by column instead of rows) with a bit of rearranging of your workflow.
Is it possible for you to upload the workflow with a bit of dummy or non confidential data? I believe, it would be easier to help you in this case.
Here I have attached a similarily sized library that’s openly available on the Internet. Similarity distance_data.knwf (448.3 KB)
What that loop is doing, is separating a collection value of a similarity matrix, one row at a time, then transposes resulting columns in a single row, renames it, and replases all 1’s in it (Similarity matrix has all ones on the diagonal, which messes up the following GroupBy), and finally finds the biggest number, giving us a nearest neighbour simmilarity.
I would guess that there is a much more elegant way to do this, but I am just not that familliar with all the different nodes.
I will be trying to use the Column Aggregator one, thank you very much for the tip!
I may be wrong but I have the impression there is no data associated to the workflow. Would you mind please to post it as a SDF file or upload the workflow back with at least the SDF node run (please make sure that the reset box option is not checked when you export it). Thanks in advance.
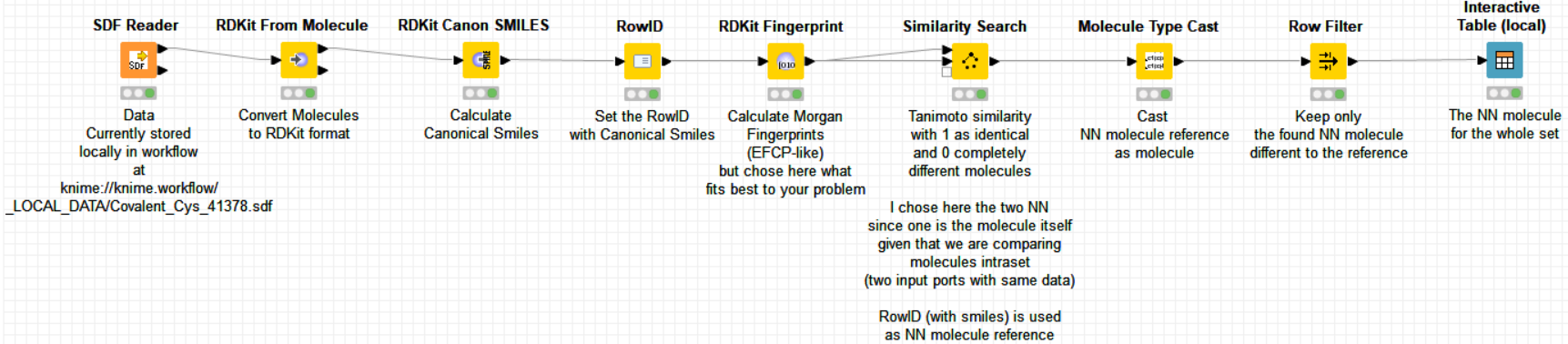
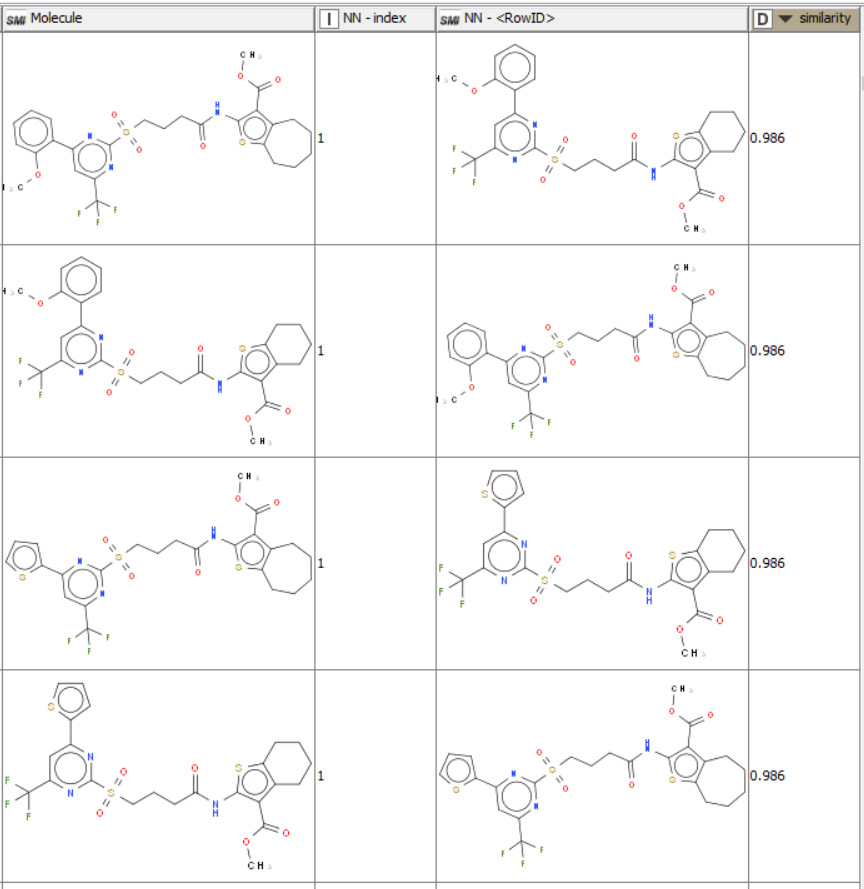
If I understood well, you are trying to calculate the intraset list of 1NN for a dataset of molecules. This can be easily achieved using the RDKit nodes. Please find attached an alternative workflow, at least for the beginning of what you had implemented (I didn’t analyze further but please let us know if you need extra help).
Thank you very much for giving my problem so much effort!!
Indeed, your solution is leagues ahead in terms of efficiency and simplicity than mine.
By the way, I have managed to utilize the Column aggreagtor and a few other things to bypass transposition altogether. The whole workflow still takes hours, but at least it’s not days.
Many thanks @kbisikalo for validating my answer. My pleasure to help.
Besides the Similarity problem and concerning your implementation, I’m glad the column aggregator could help too. By the way, a distance matrix is symetric, so another thing you could try is to use the information directly from every column of the matrix since it is the same as in the rows. Then you could do groupby without the need of transposing. I would take the split collection node out of the counting loop too (split the whole matrix only once) and I would use a “Chunk Loop” (set to one row at a time) or a “Column List” Loop to provide a column at a time, depending on whether you want to group by rows (groupby) or by columns (Column Aggregator). This should improve time execution too.