Hi everyone,
I’m analyzing crime data in Boston, where each crime is geolocated with GPS coordinates. Using the DBSCAN node in KNIME, I’ve created clusters with an epsilon of 0.4. While this produces clusters, I’m facing some challenges with their size and coherence.
Objective:
The aim is to identify geographically compact crime hotspots that provide meaningful insights for cross-referencing with additional datasets.
Problem:
- Some clusters stretch over large distances because of the “chaining effect” in DBSCAN, where points are indirectly linked via intermediate points. This results in clusters that are too large to be useful for identifying specific hotspots.
- When I reduce the epsilon to create smaller, more compact clusters, many points are left unclustered even though they are close to others. This leaves gaps in the analysis, as many valid clusters are no longer formed.
Included:
I’ve attached screenshots of the clusters to illustrate the issue. The images show how clusters extend over several kilometers.
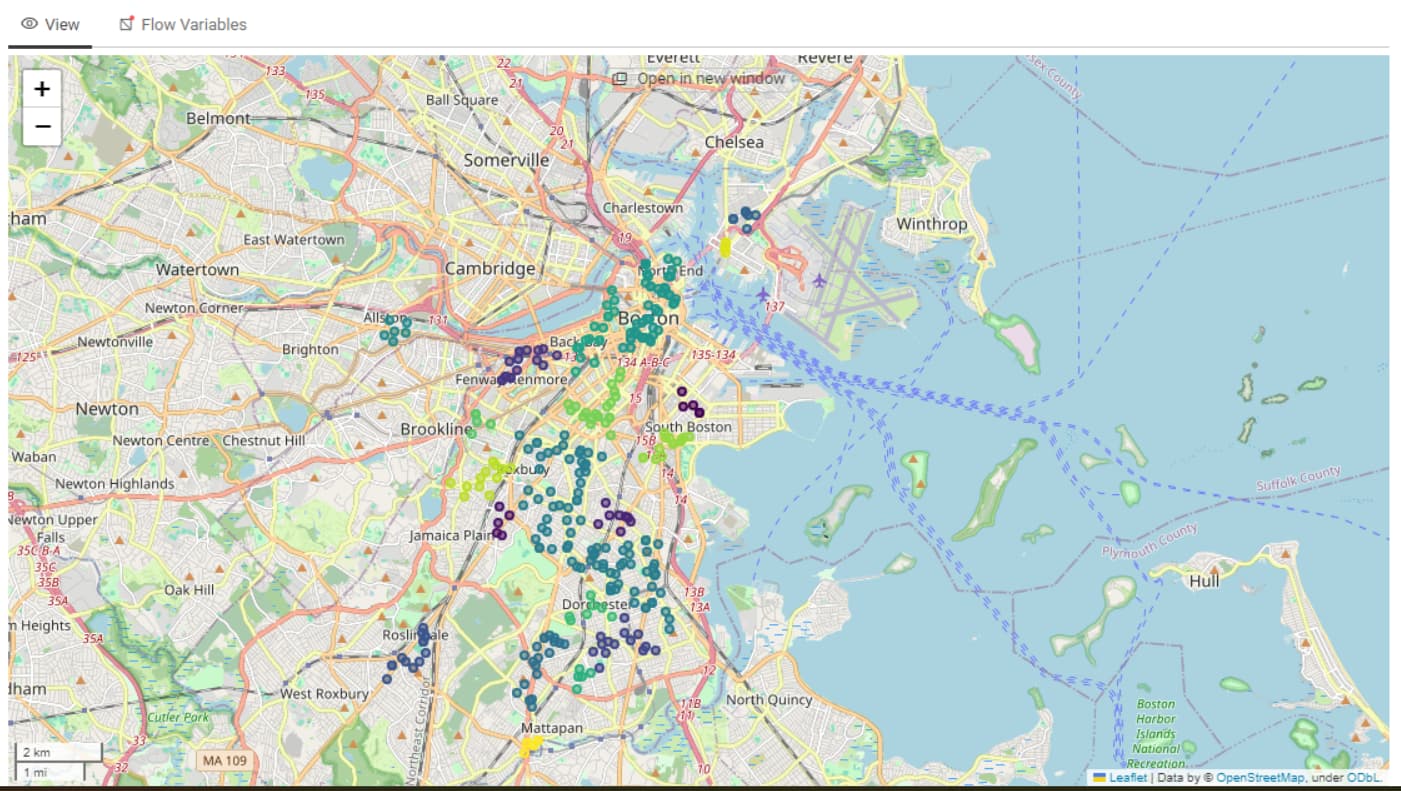
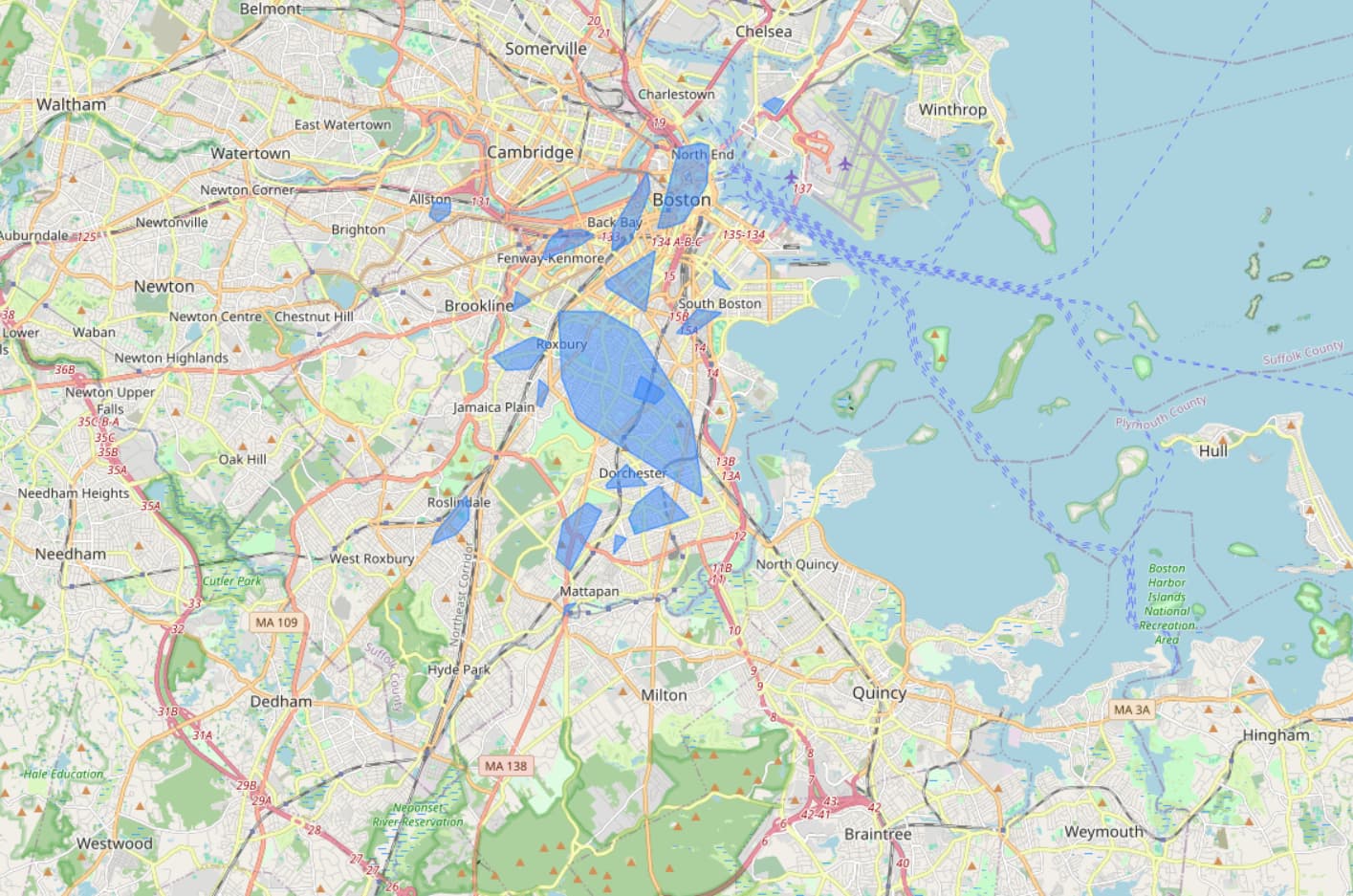
Question:
Is there a way to refine these clusters or post-process the results in KNIME to achieve geographically compact clusters while retaining as many clustered points as possible? Any advice or example workflows to address this balance would be greatly appreciated.
Thank you for your help!
Boston_Crimes.knwf (17.3 KB)