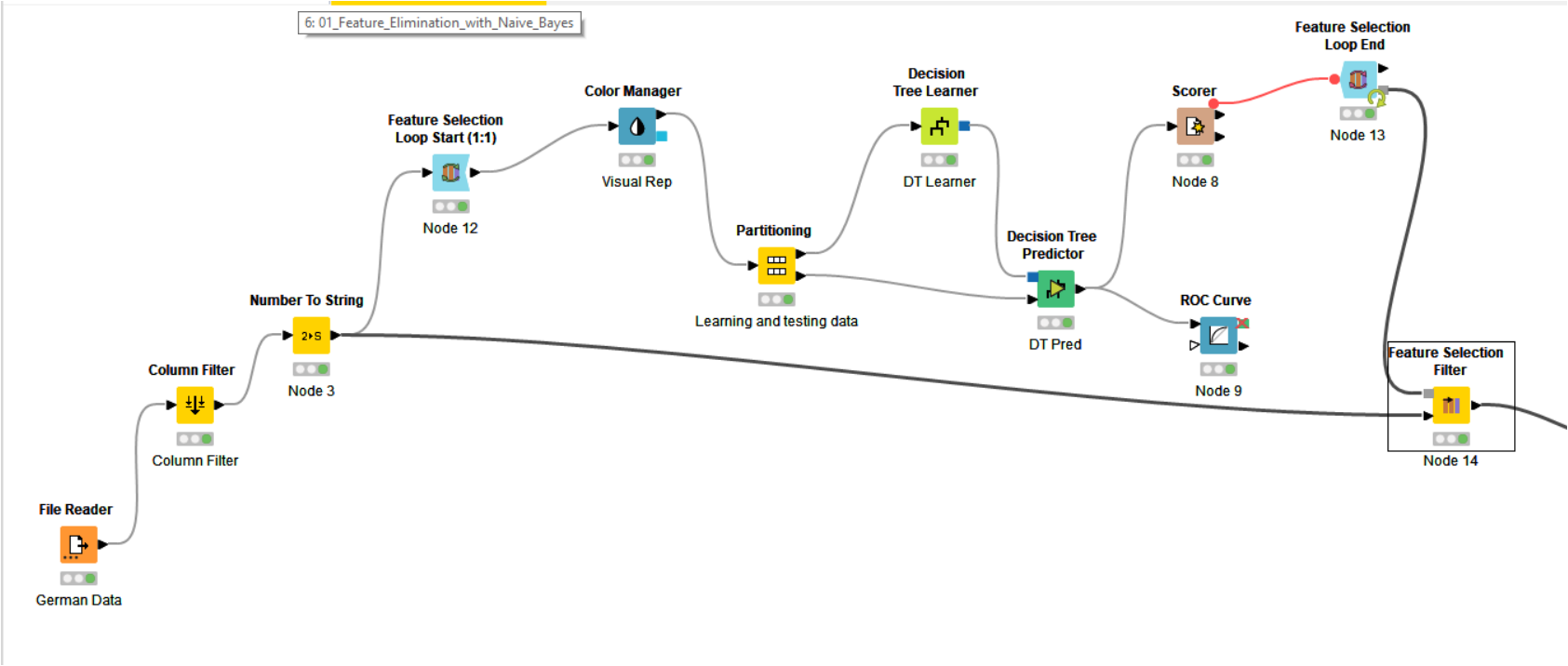
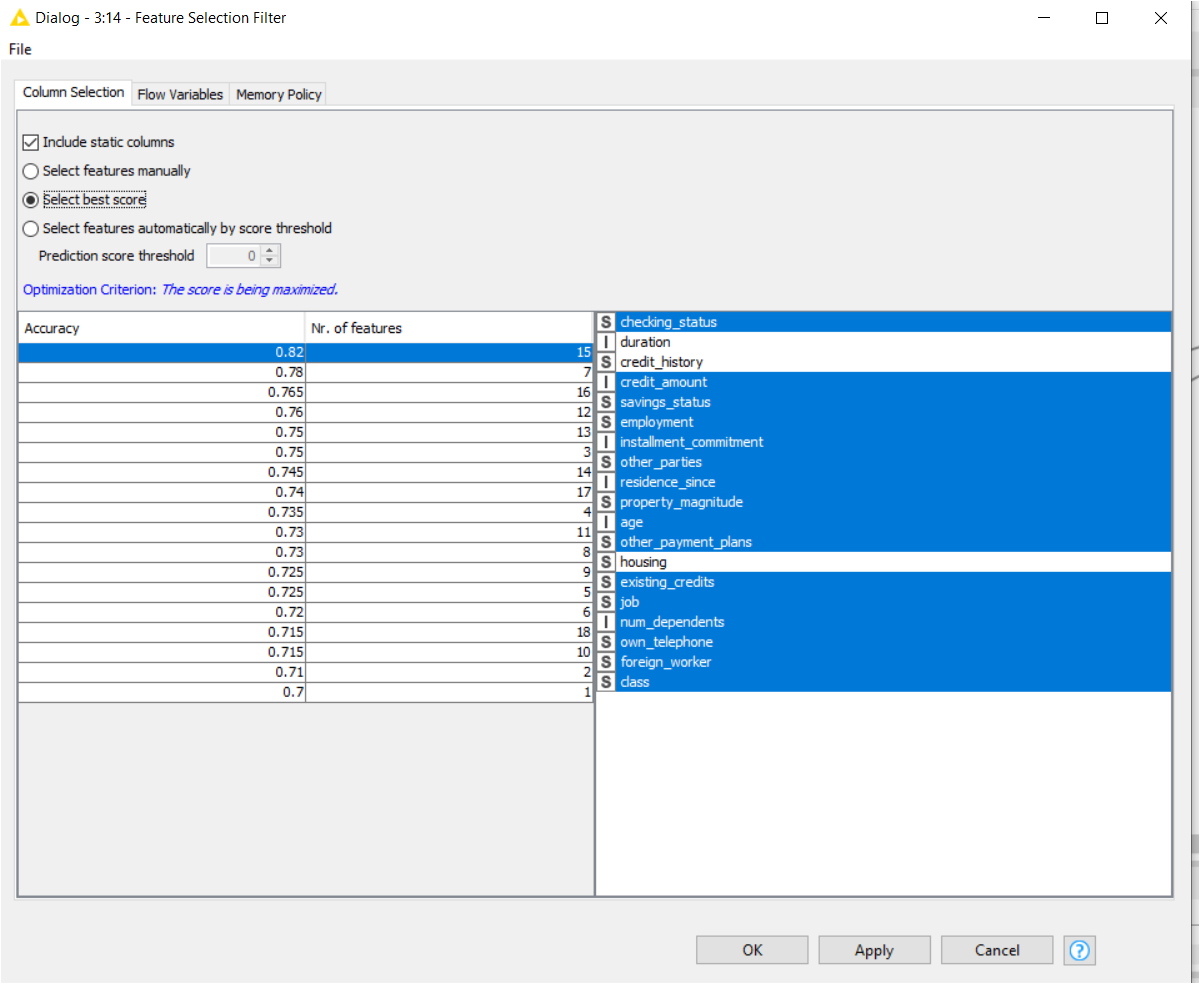
I used the Filter selection loop to know the best features use to optimize the accuracy of the model (decision tree) to the best mark until I get the following result:
Of course I go to select the features based on the recommendation (best score) of the feature selection loop but finally I got another bad performance results again as the following:
You haven’t used the same static seed in the two partitioning nodes. please check the “Use random seed” box and make sure to have the same number there in both nodes, then the accuracy is going to be the same.
We really love our open-source community, you folks are awesome, and we’re giving our best to foster it and answer all the questions! But let’s face it, in the end it’s our paying customers that facilitate our all paychecks and the continuity and maintenance of this software, that’s the world we live in. Therefore please understand we can’t make open-source questions like this our top priority. We ARE trying to answer everything asap and to the best extend, and tagging the admin after 3 days does not speed up this process. I’m sorry you felt ignored!