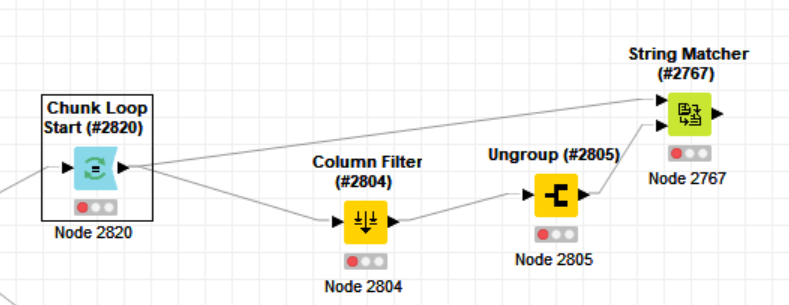
I have another chunk loop I want to improve/replace with something better performing. In this case I have a table with 2 columns, one is a string, the other is a list of strings, I want to use the string matcher to find the closest string in the enum. The same lists can be in multiple rows, thats why I think there is room for optimization. Using a chunk loop is pretty straight forward imo and looks in my example like this:
Example of input data;
string: lists: ab ["abd", "adb", "cde"] cd ["abd", "adb", "cde"] fg ["xy", "bc", "gdfdcde"] xd ["xy", "bc", "gdfdcde"]
I thought about grouping the lists (to only have them once), but how can I then make sure that only the corresponding list gets matched with the string? Can the group loop be used for that? I have no experience with it.
Thanks!