Hello, I’m using Knime 4.1.3 on my Windows10. I’m populating an Oracle database by writing data from CSV files into it. I have encountered VERY slow performance especially with DB Merge. It works correctly, but slowly (so I believe I have configured it fine). Indexing the target table in Oracle helps, but not enough. DB Insert, for example, works much faster (with or without Oracle indexes). All Knime memory settings are using default values.
Related to this I have some questions:
In my workflow I have many (>20) individual “threads” (see the attachment image) which are very similar, but not identical (i.e. difficult to parameterise). They are all using a “shared” Oracle Connector. Is this a good idea or would you recommend one connector per “thread”?
The performance seems to slow down as the number of executed threads grows. Does this sound normal?
As an alternative, I considered to replace DB Merge by “truncate target table” and then DB Insert. How would I do it? I tried DB SQL Executor, DB Query, but couldn’t find the way to make them work. I know about DB Delete, but since Oracle offers TRUNCATE TABLE, which is much faster with big tables, I would prefer that
Hope someone has ideas to propose. Thanks in advance!
Hi @tojala , (Welcome to the forum!)
So are all of your “threads” trying to merge data into the same Oracle table? How much data (number of rows) are we talking about in terms of your database size, and data being merged.
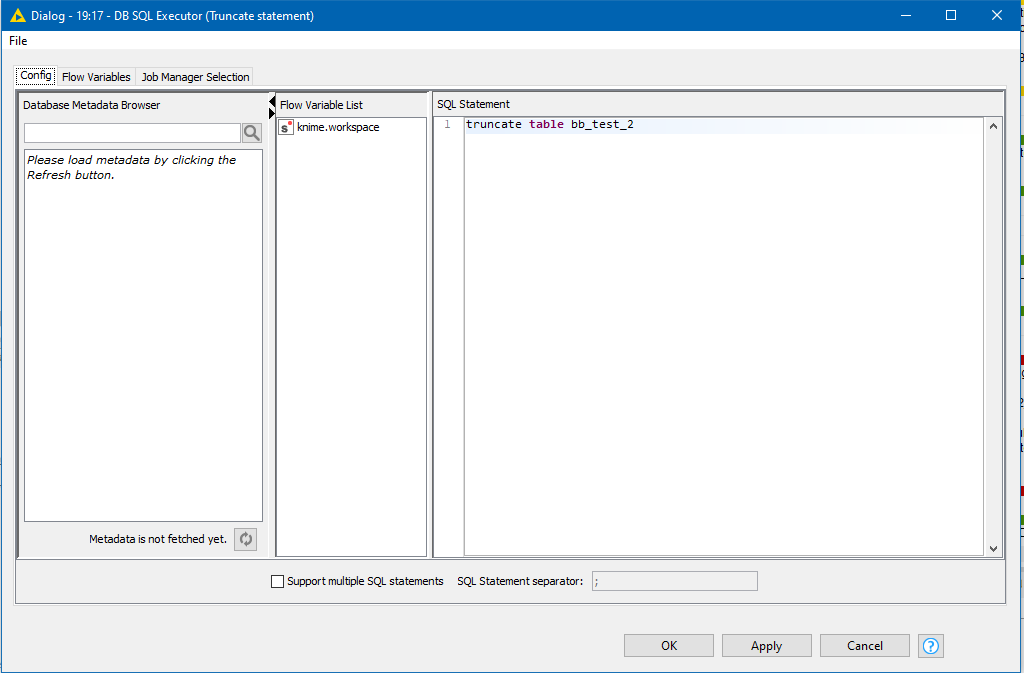
In terms of executing other commands on the database, the Oracle Truncate command is of course DDL rather than DML, and so would have to be executed in the same way that you’d create a stored procedure, or other such statements so should be possible via a DB SQL Executor node.
You may find this workflow I have on the hub of use in making your various Oracle calls such as Truncate work (as I include such things as creating/dropping tables and stored procedures , if that’s the route you decide to take.
edit:
I just tested Truncate on my pc… it worked ok in DB SQL Executor configured as follows:
I guess my question then is this… If Truncate followed by Insert is actually an option to you, is merge definitely the right option in the first place. That feels quite resource-hungry, and maybe there is a better solution. I don’t think I’d advocate using Truncate though generally unless you are always just doing full data loads, as you cannot easily deal with referential integrity constraints that you may want to have in place on your data, but it obviously depends on your use case.
First big thanks for the truncate. I swear I tried it among the numerous other attempts, but (possibly) was distracted by the ORA-03291 error which is returned if I put a semicolon after the truncate. My mistake (newish with Knime
Both merge and truncate-insert are viable options in my case. Merge would keep the “history” of data that is no longer available after a truncate-insert and would be a slightly “better” solution, but it is not such a big deal.
The data amount is typically less than a million (short) rows per thread - and works with INSERT so shouldn’t be an issue. Merge obviously has to do much more processing and despite the indexes this may be the best reason to not use it.
BTW, the “batch size” setting in DB Insert (default 1000) doesn’t seem to commit after each batch. Is there a way to force commits?