My workflow is supposed to perform some DB operations. Some of them depends on another ones so they must get invoked after the other nodes finish.
What I need to do in more detail but still simplified, is writing data into table A and table B and filling table C with data from A and B afterwards.
I had a look at Meta Nodes but I didn’t get convinced that this was the right way. Another option would be not to wait until nodes another ones depend on, finish but rather work with the data workflow reads from source database - but I’m a bit afraid of memory in that case because tables the workflow is supposed to work with might contain about 4, 11 or 24 Million record in some cases.
Could somebody provide me a pattern how to deal with such a situation as described?
Thank you
If I understood correctly, you want to make sure that nodes execute in a specific order, which do not necessarily have a connection through a data port?
In that case you can use make of the red flow variable connection. This way you still ensure order, but without an explicit table data flow. (the flow variable connection just act as dummies in this case)
Hi Jan!
You can use Call Local Workflow node to orchestrate you jobs. You create 3 workflows. One for each Table writing. Then you create “Master” workflow from which you are calling other workflows with above mentioned node.
Br,
Ivan
Hi Ivan,
Thanks for your answer.
I’ve already started considering this approach. What I’m not happy with is a need of re-creating DB Connector nodes in these “nested” workflows since I don’t know there’s a way how to propagate connection through Call Local Workflow from the “Master” workflow.
Jan
Hi qqilihq,
Thank you for your reply.
This approach would work unless the dependent node depends on two other nodes. And consider those two other nodes running in parallel so we can’t make the chain of them using flow variable connection. What I’ve learnt at the moment I drop another wire to single “bunny ear”, the first wire disappears so it’s not possible to make a node dependent on two or more others this way. I would need a node to join the flow, which could be a node for joining variables, couldn’t it? OK, I’ll test it.
Jan
Exactly. For that case, you can prepend your dependent node with a Merge Variables node which combines multiple flow variable inputs:
Yep. I know 
But luckily you can copy paste.
I’m curious. Why do you see it as a problem?
Br,
Ivan
Hi Ivan,
sorry for answering you that late. That’s because I don’t like the same code scattered all over my project. DB Connection is configured to use a particular DB driver, connection string, credentials and so on. I’d have to configure all my Database Connector nodes providing them with parameters I mentioned. And I’ll even have to update all occurrences of the parameters after they change. This makes me doubt copying Database Connector nodes is the right way.
Or, is there a way of getting Database Connector nodes parametrized so there would be just a single configuration to maintain, and getting all Database Connector nodes taking their settings from such a shared configuration? I haven’t found anything like that yet. Also, I haven’t even noticed I could use Workflow Variables for Database Connector parameters.
Regards,
Jan
Hi Jan!
To battle this I have done following. I have a txt file with connection details. So I first read this file and then control connector nodes with flow variables which can be done. This way changing from Linux/Windows and from development to test/production makes my life easier 
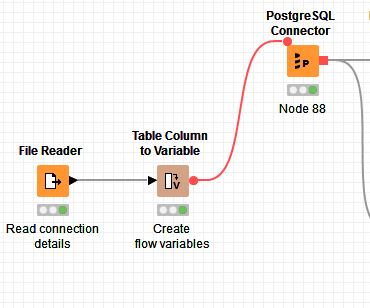
Br,
Ivan
Hi Ivan,
I’ll have a look at it. Thank you.
Jan
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.