I am running into trouble with out of memory issues in several KNIME learners. I am loading an 11G file with something like 30 features and two classes. The "disk limited" paradigm seems to work fine reading and splitting the data set. The problems occur when I attempt to train a model. I am required to train on 70% of the data, so it is a large data set. To this point, random forest has done well. NN, SVM, bayes, and regression learners have all had memory issues.
-I have KNIME running with 15G of RAM, but it seems to top that out and crash the different learners.
-I am running them separately - i.e. not in parallel.
-I have also attempted to tell the learners to write to disk always, but that did not change the memory behaviour.
-Yes, I have done several google searches.
I am evaulating KNIME against commericial offerings that can train and deploy models on this type of large data set. My attempts to this point with KNIME have met with limited success, so I though I'd ask for input. Other than reducing the training size (this is the main point of the test), are there any suggestions? Are any of the learners more efficient? Any thoughts on what would happen if I moved to a machine with more RAM?
Thanks!
My knime.ini has the following changes from default:
Hello my friend, I have the same issue, large datasets leading to crash when running a learner node.
Any news?
I will let you know if I find something useful
Performance issues are difficult to track, so I give you my collection of discussions and tips of what to do about it.
Could you be a little bit more specific about what kind and size of data you are dealing with and especially what kind of model you are trying to use (from my experience the Weka nodes are especially ‘hungry’).
In general if your machine is not powerful enough there is litte choice but to upgrade the machine or reduce the data set. The last part can be done in a meaningful way by dimensionality reduction, just to give a few hints:
remove highly correlated variables (that basically contain the same information)
remove variables with little variance
reduce dimensions thru PCA (principal component analysis) or smth.
Hello MLAUBER71,
I am a little bit upset about this issue, first time ever I cant train a model
Currently I am using a dataset from the Chicago Data Portal, Its a CSV file of 1,8 Gbytes.
I started training a Decision Tree just for data understanding, first time the whole data, and then continued training the same algorithm using chunks of data. Neither 10% of the data has worked for me.
I run a Intel i7 16Gb RAM gaming laptop,
Can you point us to the data file so we might have a look if there is something strange there? If you already have a workflow maybe you can share it with us so we could see.
Hello MALUBER71,
My comments:
Yes I readed and then configured the memory to 14 Gbytes
My PC uses an Western Digital 7200 rpm 1TB Sata Disk drive and I have near 40% of free space.
I will try to restart knime with the clean option, and let you know
I configured the whole workflow to save data to disk, even the Decision Tree Learner Node
Never heard about the Parquet, ps link fails…
Sure…! the data is here:
Click on the Export label, and choose CSV format.
And here the Workflow. Pretty basic, cause its for data undertanding. Crimes Data Project 1.knwf (11.2 KB)
Are you on the version 4.01 or 3.72? You can try if other version is working for you. Also, recently was a discussion with recommendation how to configure v.4.01 to work as 3.72. Unfortunately I do not have it handy.
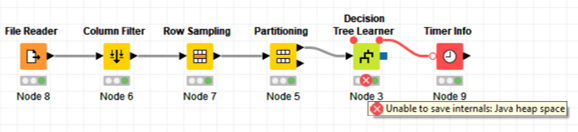
Hi HSRB I managed to run the workflow, my computer specs are not quite different from yours, but when saving it shows the following message “Unable to save internals: Java heap space”
Hello mauuuuu5,
Thank you very much for your response,
Did you downloaded the data? And configured the row sampling to 5%, just like I did?
That is another error, not the one I receive. I cant neither run the Learning Node, nor completing the task.
I was wondering if running Knime under Linux is a better way of memory optimization
What do you guys think?
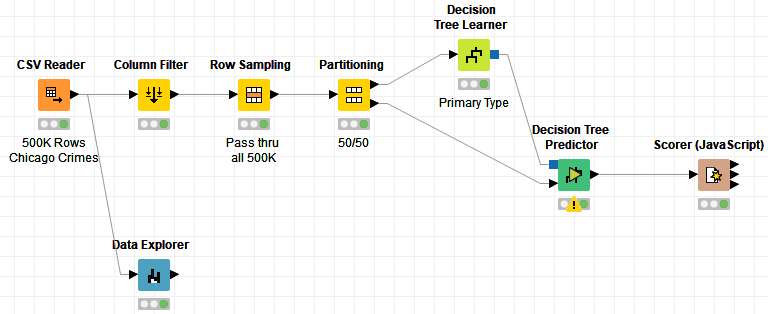
I think the problem here arises from including nominal data in the model that is far too specific to be useful. For example, including fields like Date, Block and Location as features doesn’t really work, since there are far more than 1000 unique values for these fields, and (I believe) this causes the size of the decision tree you’re trying to save to be gigantic, and too large to be effectively handled.
(Identifying fields like this is straightforward if you use the Data Explorer node up front, so you can be sure to remove or modify/bin such fields.)
I took your workflow, read in a trimmed version of the Chicago dataset (about 500K rows to save time), and built a decision tree on the Primary Type field after removing nominal features that were troublesome. I was able to save this model to disk and make predictions with it, although granted, the predictions were terrible.
If you’re just interested in playing with different algorithms in KNIME to see how they work, you might try some of the workflows we have posted on the KNIME Hub.
Hi Hector I used the same configuration as you provided and used the 7 almost million records. I managed to run the node, but I shut down all the remaining programs.
Hello @ScottF
Thank you very much for your time and response.
The point is I am not a knime expert. And all the advices you wrote were a light to me.
My main goal is to run the best and most suitable algorithm available in order to predict the more accurate
How do I get to that is the task