Hi @hsrb -
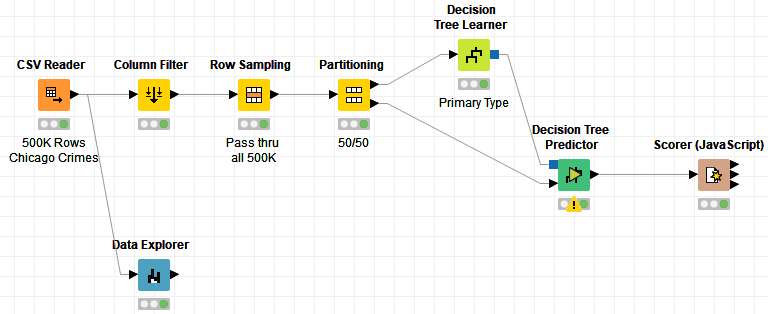
I think the problem here arises from including nominal data in the model that is far too specific to be useful. For example, including fields like Date, Block and Location as features doesn’t really work, since there are far more than 1000 unique values for these fields, and (I believe) this causes the size of the decision tree you’re trying to save to be gigantic, and too large to be effectively handled.
(Identifying fields like this is straightforward if you use the Data Explorer node up front, so you can be sure to remove or modify/bin such fields.)
I took your workflow, read in a trimmed version of the Chicago dataset (about 500K rows to save time), and built a decision tree on the Primary Type field after removing nominal features that were troublesome. I was able to save this model to disk and make predictions with it, although granted, the predictions were terrible.
If you’re just interested in playing with different algorithms in KNIME to see how they work, you might try some of the workflows we have posted on the KNIME Hub.