It depends on what you want to do. What is you aim with these data ?
The same, it depends. for instance, normalization is not required when working with tree-like (i.e. Decision Trees, Random-Forest, etc.) models but strongly recommended when using distance-based models such as neural networks.
Z-score is a Gaussian normalization which converts the data distribution so that it has Mean = 0 and Standard Deviation = 1.
Min-Max normalization linearly converts a distribution so that the mimimum variable value macthes value -1 and the maximum matches value +1. These extreme values can be parameterized to other values such as 0 & 1 at will.
Z-score is resiliant to outliers whereas Min-Max normalisation is strongly affected by outliers.
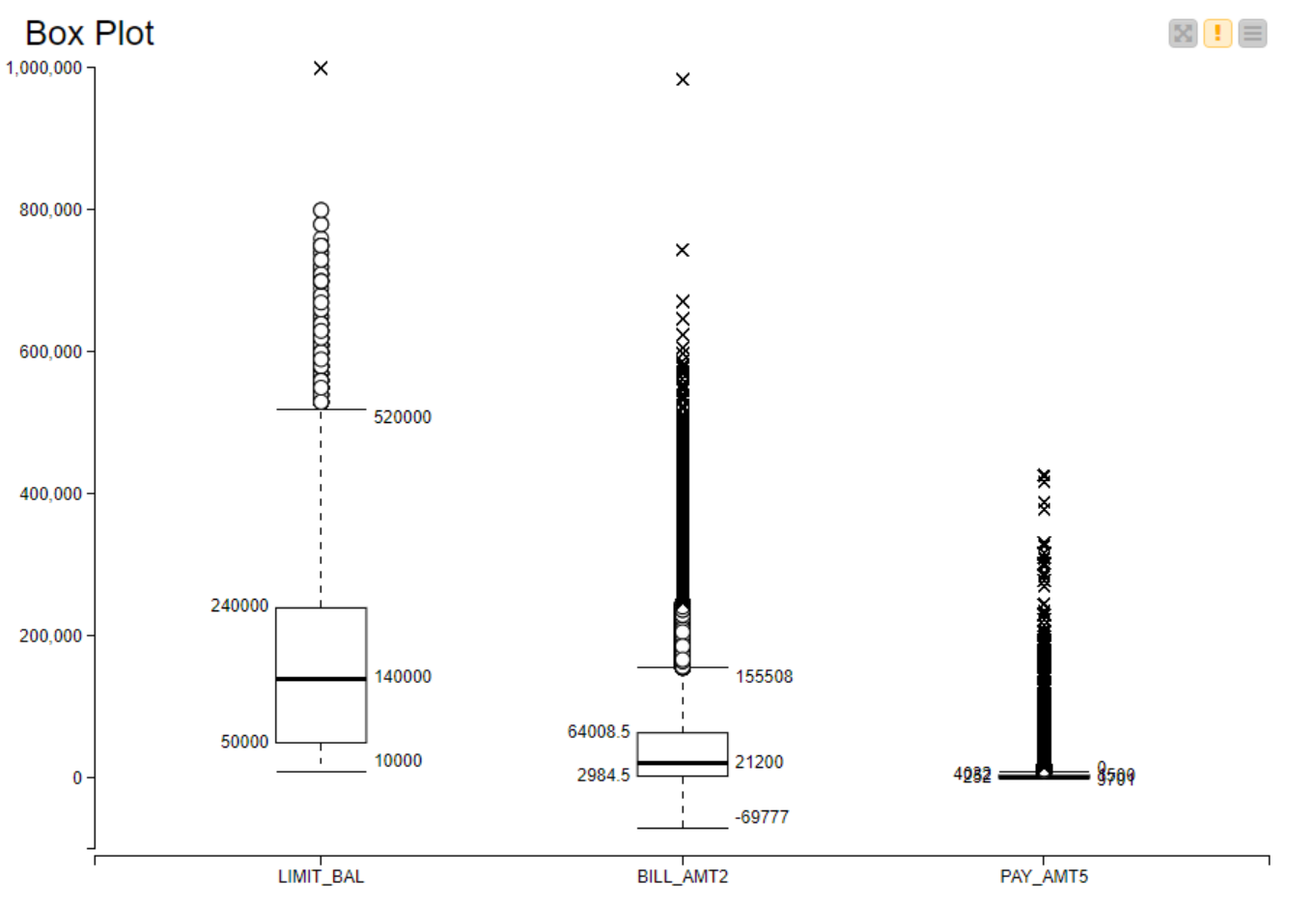
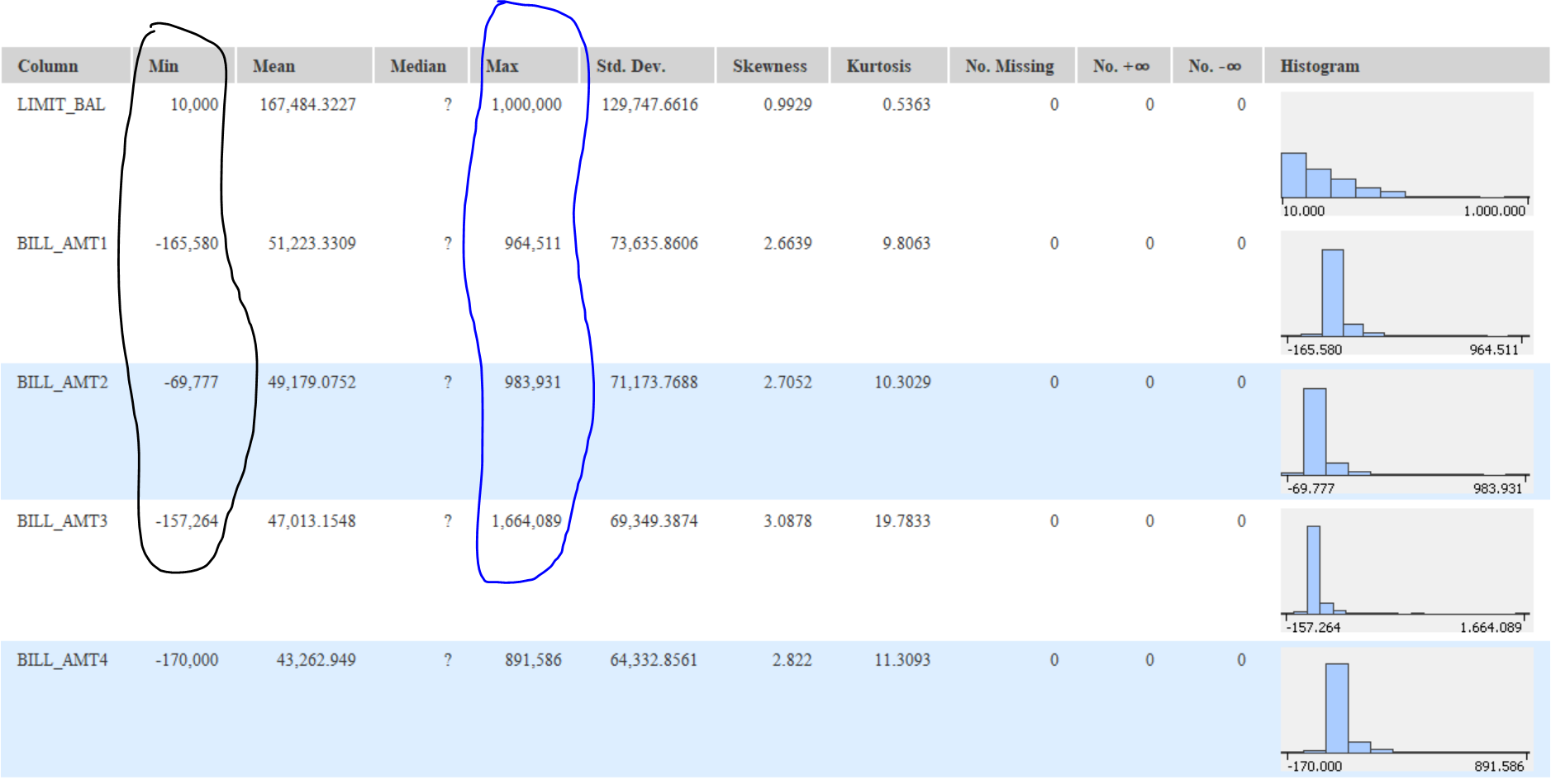
Given the distribution of your data, I would not normalize by Min-Max but by Z-score because of the presence of outliers in your variables.
Whether you need/should remove outliers from your dataset is often data/model/problem dependent.
Please be aware that the previous explanations are very succinct and generic. Maybe sharing here your data and workflow could help people to better understand what you need to achieve and hence better help you.
Thank you for your time answering my question. Actually my workflow is to detect the credit card default payment. I tried to use Decision tree , Naive bayes and logistic regression to predict. But during working in the workflows of decision tree and Naive bayes, I realized that how to deal with outlines. Attached is my workflows and data.
For prediction of credit card default payment, Is logistic regression a preference model ? new model.knwf (194.6 KB)
Thank you for your detailed answers in your last post. The Credit Card Fraud dataset has been extensively used in the KNIME forum, hub and blog web sites as a dataset example to illustrate the implementation of classification models.
Please do a google search typing for instance “KNIME Credit Card Fraud forum” (or hub, blog, nodepit, medium) and you will find plenty of literature with examples which explain well how to tackle this problem. For instance, the following blog can be a good starting point:
Doing a bibliography before and while implenting a classification or regression model will provide you most of the hints you need and save plenty of time.
Hope this helps to start with your development.
Best
Ael
PS: I’m replying from a mobile phone because far from a computer for a whole week.
Please attach the @ sign to the forum member names as follows “@Aworker” so that we get a notification of your replies when you post them and are made aware faster.