hey guys I ran into a problem and I hoped that maybe I could get some help.
I trained a predictive model that can detect diabetes and I reached 91.6 accuracy via Random forest algorithm, but I am not sure that if my model is overfitted or not.
I read somewhere that one of the ways that I can tell if the model is overfitted or not is by comparing training datas accuracy and test datas accuracy. I used the scorer node to find out my training dataset score and it was 73 but my test dataset was 91.6. I also read somewhere that I can get insights by comparing f-measures and recalls and precision, But the thing is I don’t know which f-measures I have to compare. Do I have to compare the f-measures or recalls of two different rows of my test data set or should I compare the f-measures of my training dataset with f-measures of my test datasets?
I also used ROC curves and found out that my training dataset has a 0.8 AUC and my test dataset has a 0.73 AUC.
I will leave pictures of my workflow and my scorer nodes.
I would appreciate any help or explanation about any of the stuff I have problem with
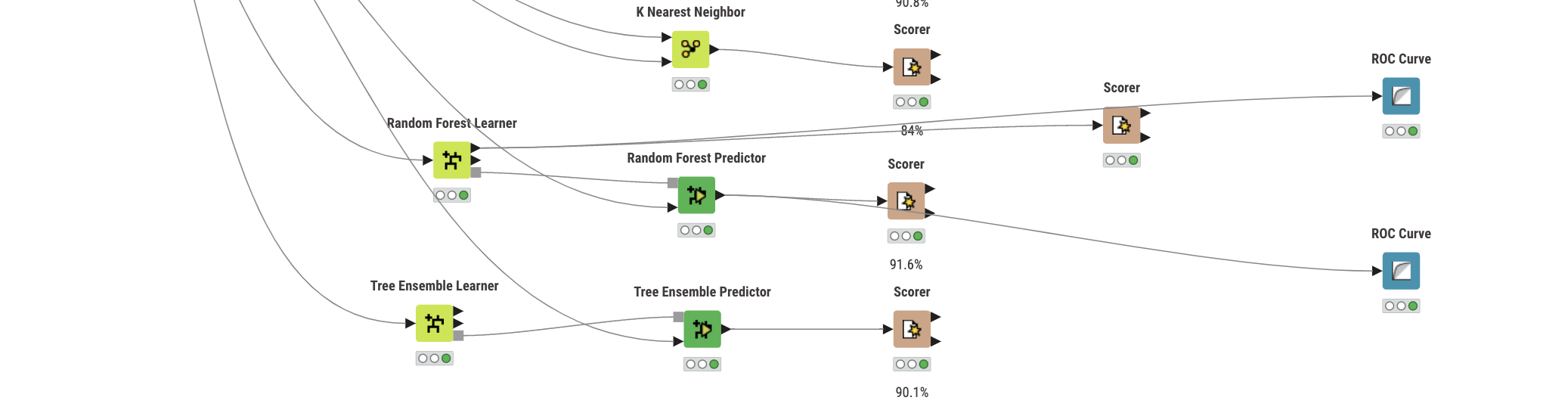

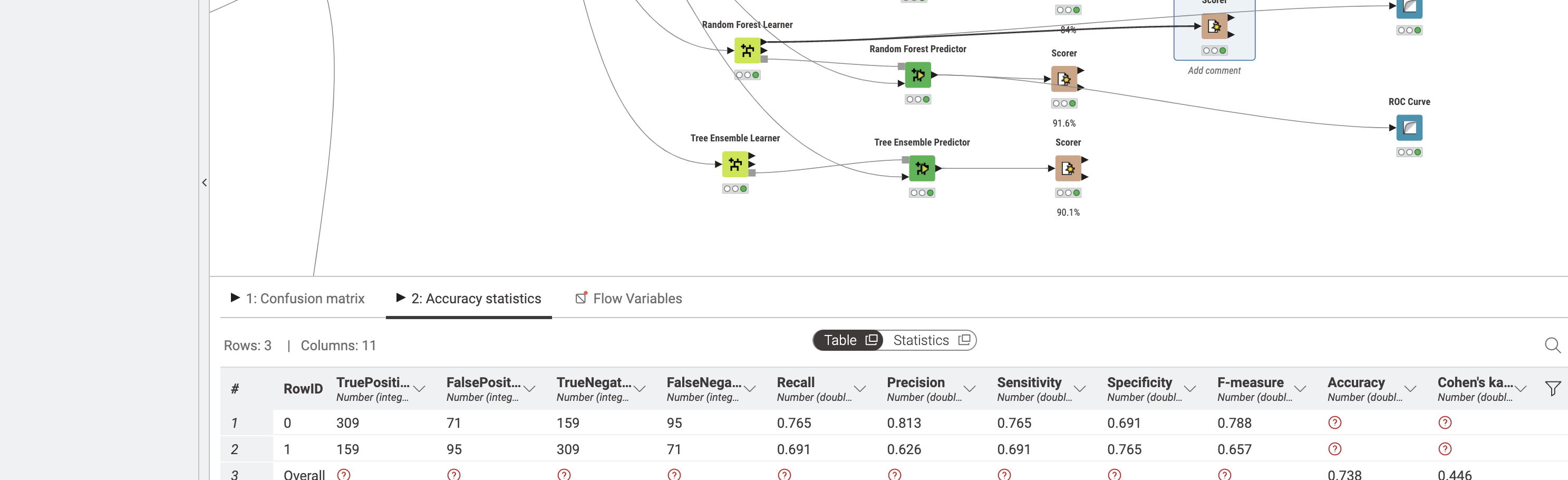
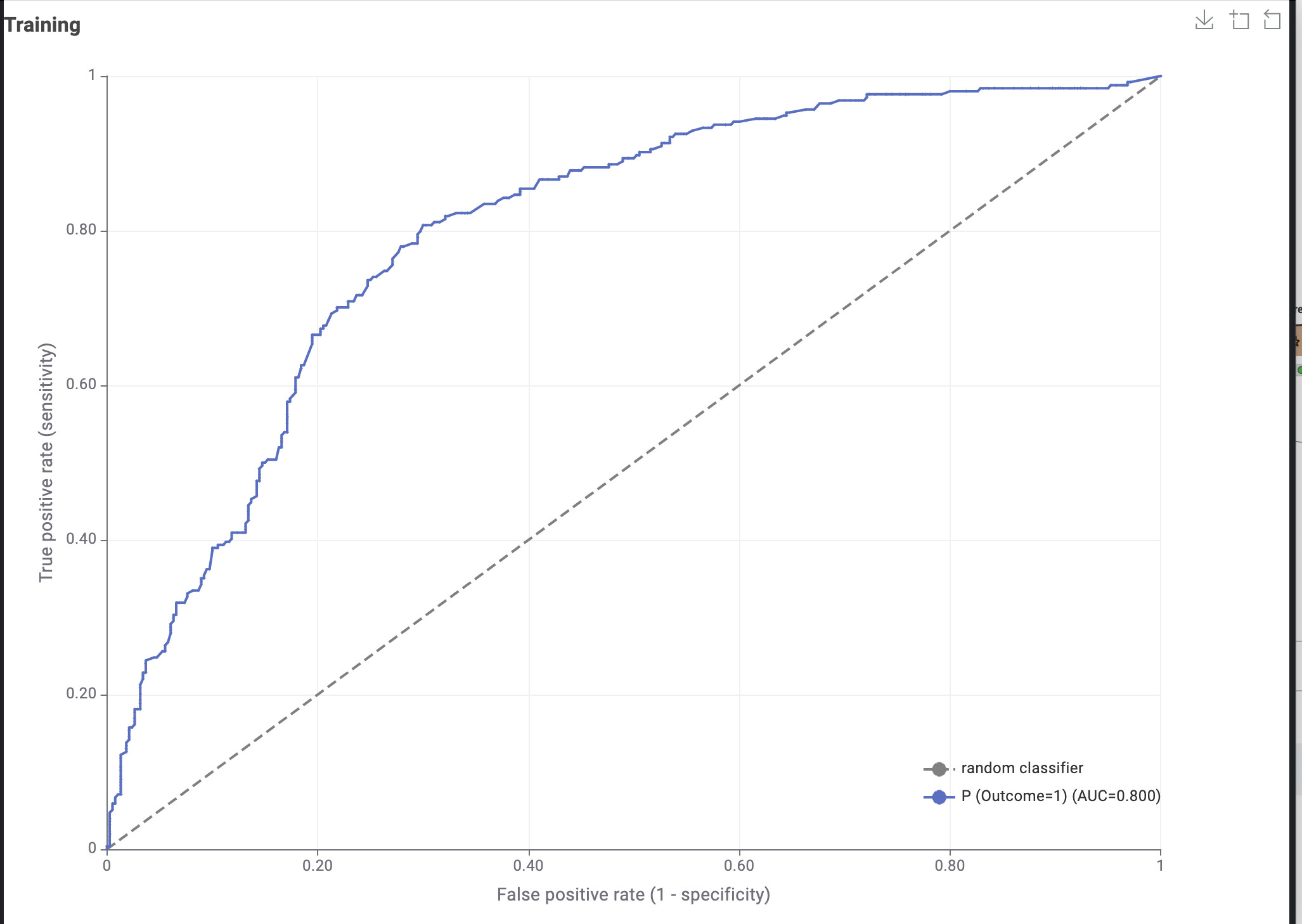
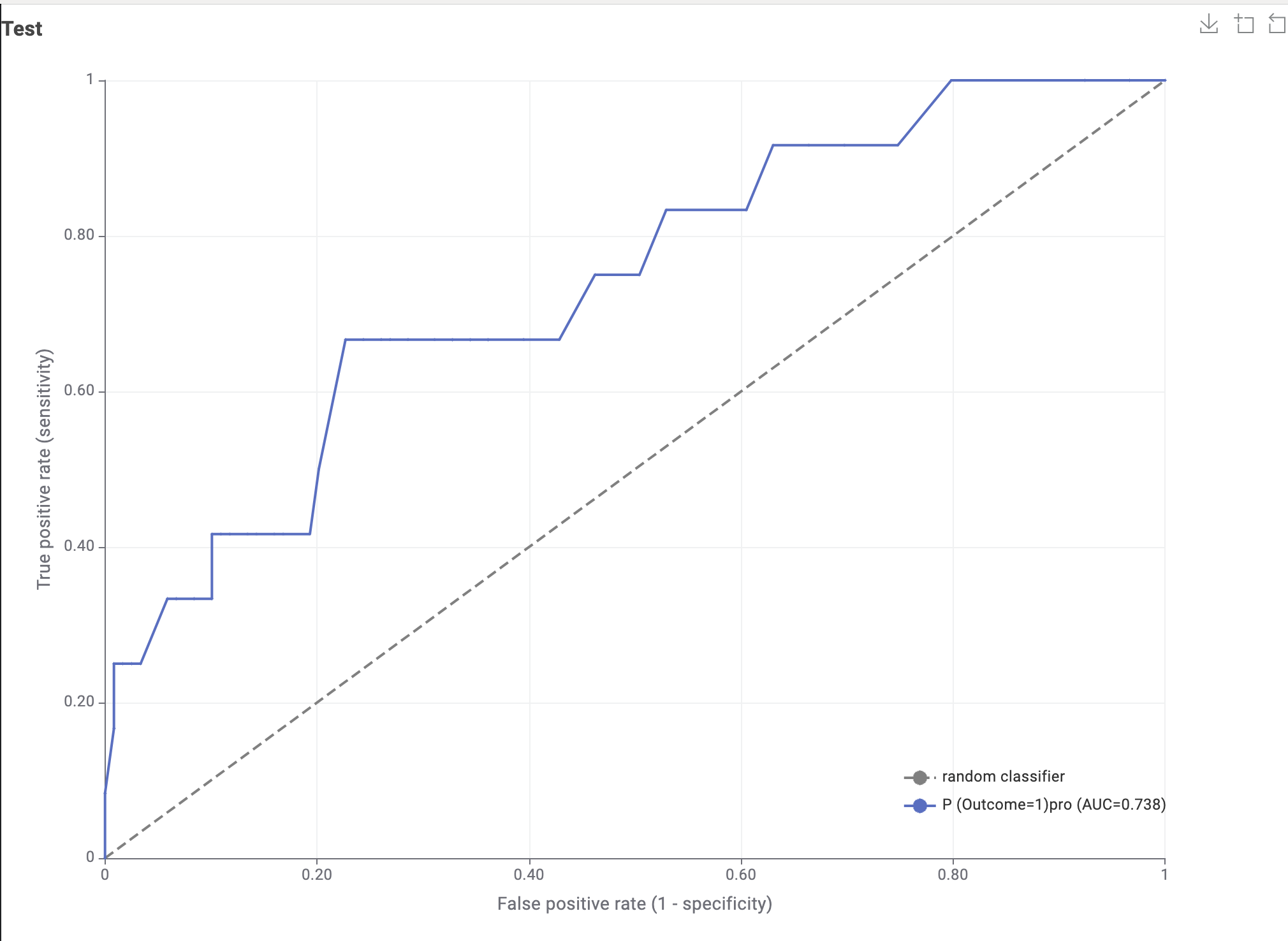
@AminArbab first thing to check is the number of positives in your test and training. From the screenshots they seem to be somewhat ‘off’. The number of positives in your test dataset seems to be much lower that in the training. The second AUC curve suggests small numbers also.
Question is how unbalanced is your initial data. If it is very unbalanced you might consider using AUCPR as a measurement. Also you could try and employ some advanced models like H2O.ai which tries to minimize overfitting by cross-validation (maybe restrict that to 3).
You can use this example to compare algorithms. Name your target Target and make sure it is a 0/1 string.
Also you can use the Binary Classification Inspector to see how your model does perform.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.