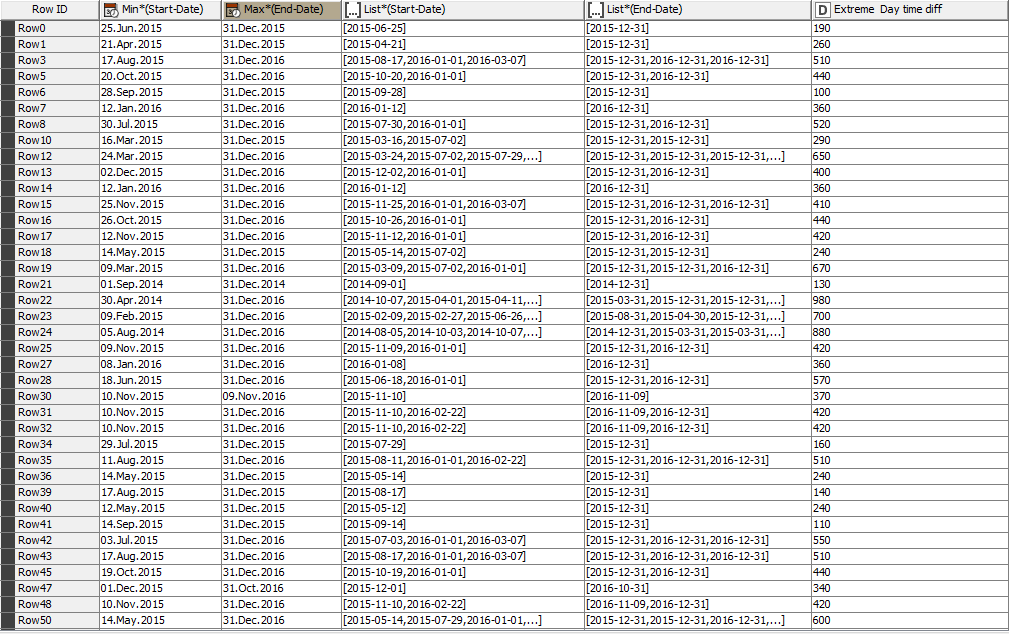
two lists: List*(Start-Date) and List*(End-Date), Each element of List*(Start-Date) correspond to an element of List*(End-Date). It’s intervals during a row is occupied.
the time difference between minimum of start dates (column: “Min*(Start-Date)”) and maximum of end dates (column: “Max*(End-Date)”).
The Time difference between the Min*(Start-Date) and Max*(End-Date) as column “Extreme Day time diff”.
I want to calculate the total of days between the earlier start date and the last end date where each row is occupied (total of occupations without overlap and without gaps)
Well I will do something direct and heavy. I’ll place a line ident via Couter generator. Then ungroup the List Start Date and List en date. They should have the same number of dates within. For each line I will unfold the dates and generate each day in between with this node : Unfolding date event – KNIME Hub. After that, this is only counting distinct days by counter. Perhaps I have misunderstood the problem. Will be easier with an extract of your datas.
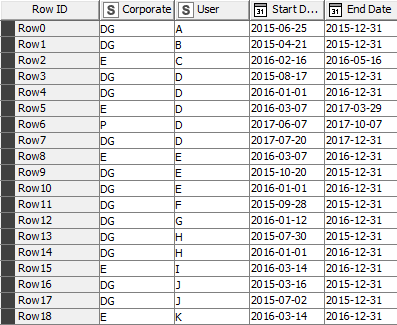
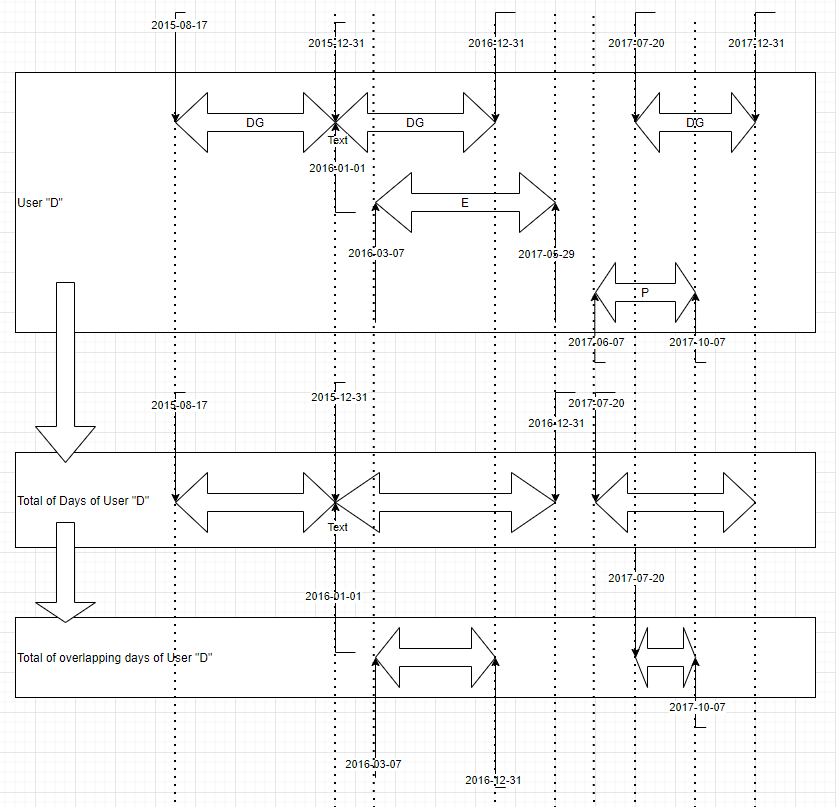
In the table, User “D” works for “DG” Corporate between 2015-08-17 and 2015-12-31, between 2016-01-01 and 2016-12-31 and works for “E” Corporate between 2016-03-07 and 2017-03-29 and works for “P” between 2017-06-07 and 2017-10-07 and again for corporate “DG” between 2017-07-20 nd 2017-12-31.
I want to know the total number of working days of the user “D”.and the total number of overlapped working days of the user “D” as describe in the picture below?