First post here, so I hope I am clear enough in my request so you can help me please.
You have an excel file, with the input and desired ouput.
4 columns:
ID = people id
ID_2 = input id
Start_date
End_date
The goal is to have no more overlapping dates, while keeping as much data as possible and favouring the most recent data.
To deal with it, it is sometimes necessary to recreate entries by splitting up the input.
In the output, datas in green are datas that have been changed. One line is green and crossed out to show you that it’s normal for it to disappear, as the entries ID_2 = 204313878 and ID_2 = 204313879 have completely taken the place of the entry ID_2 = 201234715. We prefer the ID_2 = 204313878 and ID_2 = 204313879 entries as they are more recent (higher ID_2).
Thank you very much in advance. I’ve started down a few different ideas, but I can’t get to the end of any of them.
I took a look at your description and also at the data (thanks for providing that!).
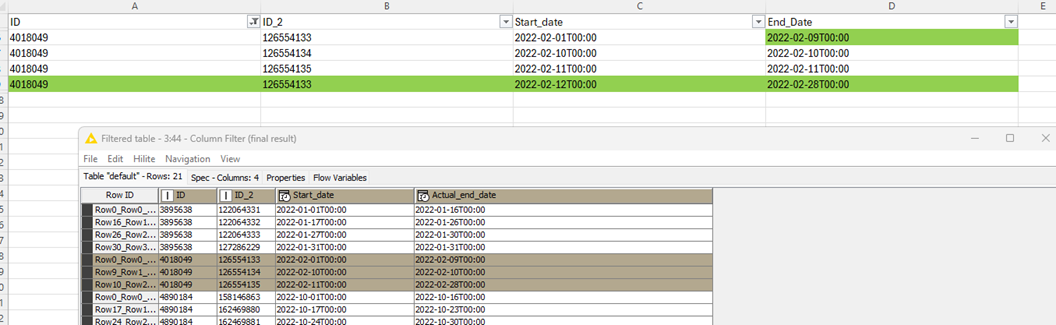
I am still not getting all the logic - e.g. there seem to be some IDs that have 3 entries in Input and the have 4 entries in output (e.g. ID = 4018049) - in the output there’s a new ID_2 = 126554133… can you explain the different cases that you may encounter even more thoroughly?
First of all, here’s the deal: I process employee absences. An employee cannot be absent twice on the same date. That’s why I need to reprocess the absence dates.
Here’s an example with people_id = 4018049.
Input : 3 entries
ID_2 = 126554133 => from 2022-02-01T00:00 to 2022-02-28T00:00
ID_2 = 126554134 => from 2022-02-10T00:00 to 2022-02-10T00:00
ID_2 = 126554135 => from 2022-02-11T00:00 to 2022-02-11T00:00
This is not possible, my employee cannot be absent twice on 2022-02-10 and 2022-02-11 since these dates are also included in his absence from 2022-02-01 to 2022-02-28.
These three entries will therefore become:
ID_2 = 126554133 => from 2022-02-01T00:00 to 2022-02-09T00:00
ID_2 = 126554134 => from 2022-02-10T00:00 to 2022-02-10T00:00
ID_2 = 126554135 => from 2022-02-11T00:00 to 2022-02-11T00:00
ID_2 = 126554133 => from 2022-02-12T00:00 to 2022-02-28T00:00
The first absence from 2022-02-01 to 2022-02-28 is therefore split in two.
We could also have simply deleted the entries 126554134 (from 2022-02-10 to 2022-02-10) and 126554135 (from 2022-02-11 to 2022-02-11) and only kept the entry 126554133 (from 2022-02-01 to 2022-02-28), but we didn’t, as we gave priority to the most recent entries (those with the highest ID_2).
Example 2:
People_id= 4890184
Input = 5 absences:
ID_2 = 158146863 => from 2022-10-01T00:00 to 2022-10-16T00:00
ID_2 = 158146864 => from 2022-10-17T00:00 to 2022-10-31T00:00
ID_2 = 162469880 => from 2022-10-17T00:00 to 2022-10-22T00:00
ID_2 = 162469881 => from 2022-10-24T00:00 to 2022-10-29T00:00
ID_2 = 162469882 => from 2022-10-31T00:00 to 2022-10-31T00:00
The last 3 absences (from 2022-10-17 to 2022-10-22, from 2022-10-24 to 2022-10-29 and from 2022-10-31 to 2022-10-31) duplicate the second absence (from 2022-10-17 to 2022-10-31). Here too, we’re focusing on the most recent absences. So we’ll have to rework the second absence to avoid duplicating dates. This second absence is rewritten in two lines, from 2022-10-23 to 2022-10-23 and from 2022-10-30 to 2022-10-30, because theses two dates are not included in the last three absences.
This would become:
ID_2 = 158146863 => from 2022-10-01T00:00 to 2022-10-16T00:00
ID_2 = 162469880 => from 2022-10-17T00:00 to 2022-10-22T00:00
ID_2 = 158146864 => from 2022-10-23T00:00 to 2022-10-23T00:00
ID_2 = 162469881 => from 2022-10-24T00:00 to 2022-10-29T00:00
ID_2 = 158146864 => from 2022-10-30T00:00 to 2022-10-30T00:00
ID_2 = 162469882 => from 2022-10-31T00:00 to 2022-10-31T00:00
I hope this is enought information to get clear with what we have to do.
I don’t think we’ll exceed 200-300 entries for this small processing on each run. But one run = one company and I have 3000 companies to put through the entire workflow process. So the quicker the better, even though I’d already realized that loops are unavoidable in these cases.
@MartinDDDD , If I can second guess where you might be thinking of a loop, on that size of dataset maybe a cross join (and then discard “unrelated” rows) might be doable and faster to process? Just thinking out loud, so I may be wrong, as I’ve not looked into the finer detail.
Hey @FannyM , have a look at my proposed solution.
Now the intervals are cleaned i.e. no duplicated / overlapping dates. The solution however differs slightly from your suggested output in a few cases to keep the logic consistent. E.g. the last green entry for 4018049 seems to be redundant as the last piece of the interval can be collapsed into “2-11 - 2-28” & we keep the most recent absence ID assigned to it.