I am trying to parse German HTML sites with the Palladian Node HTMLParser.
The HTML files are already downloaded on my system.
Naturally the German sites contain a lot of umlaute (ä,ö,ü).
The Parser is not able to parse the documents in UTF-8.
Instead I am getting different symbols like question marks or squares.
Somebody got a workaround for this?
so, what is the input which you’re supplying to the HTML Parser? Is it a URL or a file path to these files, or is this the HTML markup as a string?
There is a known issue with proper encoding detection in some cases, but I currently cannot debug this as I’m on the road.
I suggest you try the following: Read the files to binary data and pass the binary object to the HTML parser. This way the encoding detection will work for sure. You can use the following node from the KNIME File Handling Nodes for that:
Please let me know if this helps!
– Philipp
PS: This is on our list for the upcoming Palladian update.
this is an XHTML header, so the file is processable with the HTML Parser.
In order do debug your issue, I’d however need a test file. Feel free to strip sensitive data, but the general structure, header, and an example of invalid encoded characters are necessary. Also please keep the original encoding.
I had a look: This file does not contain any encoding clues, so the parser will simply assume a default encoding (afair this would be some ISO-tralala). It’s behaving the same way as a web browser would do:
Contrary to a web browser we currently do not allow to override the default encoding. But you could manually add the necessary header to the files which you want to parse:
You could add these relatively easily through the KNIME workflow – just append the header, write it to a temporary file, and then supply this to the parser.
Instead of the Java coding, it should also be possible with a combination of several non-coding nodes.
Sorry, I cannot give a more detailed walk-through now as I’m currently loaded with other work, but I’m sure someone else here in the forum can jump in.

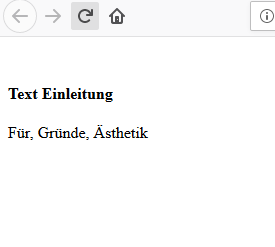
 , several ways to achieve this. I’d personally go for the following:
, several ways to achieve this. I’d personally go for the following: