Hi,
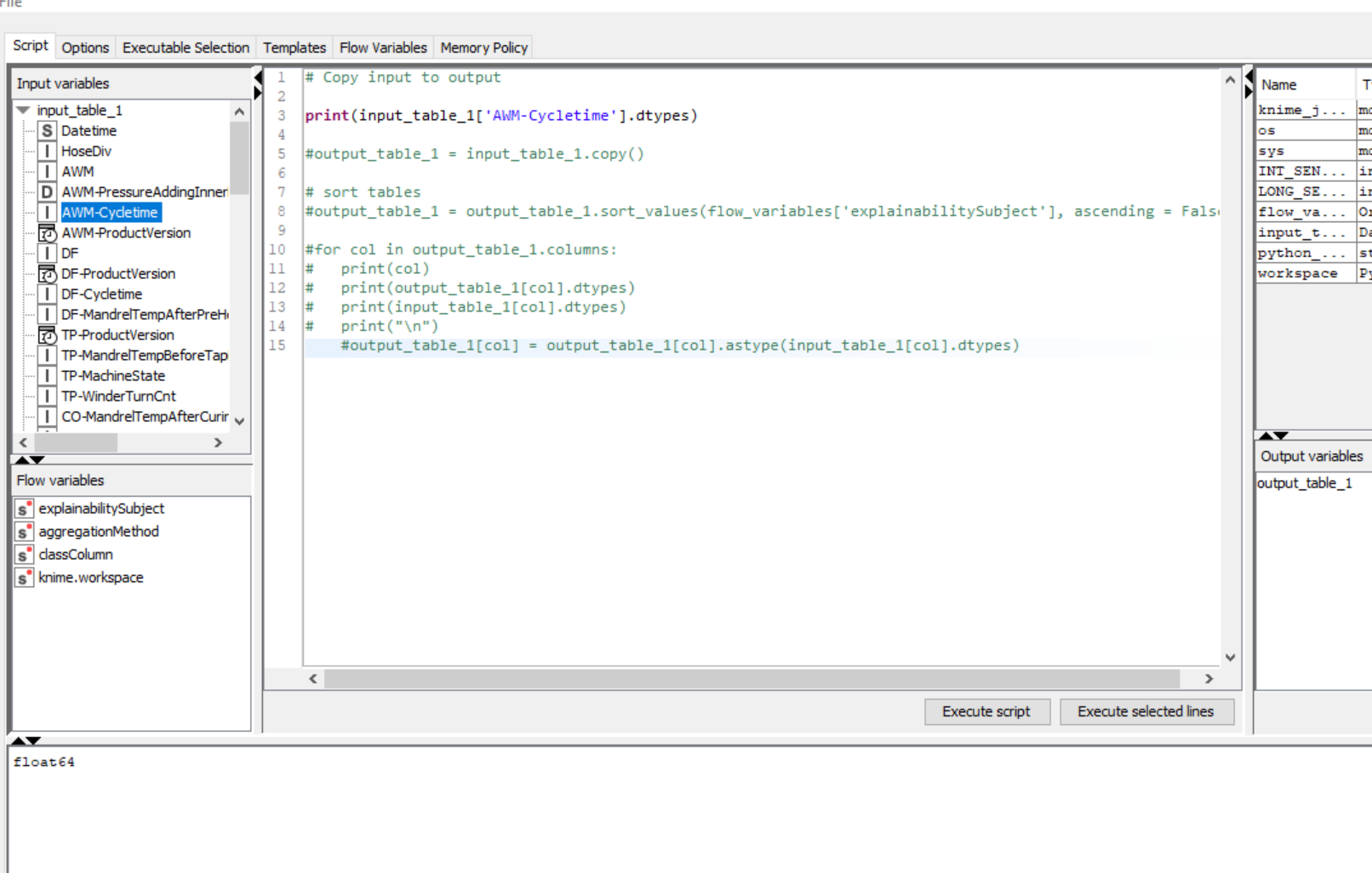
some of my columns in a KNIME python script are loaded via Pandas with a different data type than the original KNIME table, this can be seen in this screenshot (compare input variables - int, and console output float64):
Can somebody think of a solution to convert it into that type again (within a component, so somehow with dynamic column names)? Currently, this causes problems with a model that expects similar data types than before.
Does your integer column contain missing values? If so, they are automatically converted into NaNs, which implies converting the entire column into float. You can avoid that in several ways. One way built into the node would be to convert missings into predefined integer placeholder values (“sentinels”) instead. This is described in more detail in the “Missing values (Integer, Long)” section of the node description.
Alternatively, you could handle missing values outside of the node using e.g. the Missing Value node. Finally, the new Python Script (Labs) node offers an alternative, more type-safe pyarrow API besides the pandas one, where missings are represented explicitly. This might also be interesting to you (note that it is not recommended to use Labs nodes in production, though).