Hi there,
I’m trying to parallelize the execution of a set of nodes which parse out a bunch of XML files into a table. Given the nature of the data, table specs may vary from file to file.
I tried wrapping the parser between a parallel chunk start/end, but it crashes with the error:
ERROR Parallel Chunk End 0:854 Execute failed: Cell count in row “values_Row0#8_Row0_1#0” is not equal to length of column names array: 89 vs. 83
I feel that this is related to the varying table specs. Is there a workaround this? Is it possible to have an “Allow changing table specifications” option to the parallel chunk end akin to the loop end nodes?
Thanks!
Mauricio A.
You’ve got a couple of options, depending on the exact circumstances.
First up, do you need the parallel chunk loop? Many nodes will run multithreaded anyway, so simply removing the loop might solve this for you.
Failing that, do you know what the final output table should have by way of columns? If so, then creating an empty table with all the right columns using e.g. a Table Creator node, and then concatenate the empty table with the last output of the loop body, immediately before the loop end should do the trick, as it will force all loops to have the same table columns.
Steve
2 Likes
@s.roughley, thanks for this.
as for the first, I’m currently doing running the file parsing w/o the parrallel chunk loop, it just takes several hours. After seeing what the workflow is doing, most of the time is spent doing i/o (reading the file), which is where I thought that paralellizing the thing would help me. After running the parallelized version, the execution time for all the chunks is only 20 or so minutes (w/ the caveat that I can’t yet collect the results into one table)
As for the second, my challenge is that I have 60+ columns, and getting the full schema is not really possible until I parse all the files. I’m trying to figure out how to dynamically do what you’re suggesting (creating an empty table w/missing columns).
I hacked something, it’s just not pretty. I added a set of steps after the big metanode. In a nutshel, it take the partial schema of the resulting table in each of the threads and append it to a CSV, read it again, pivot it into columns and have the empty table w/the missing columns. Since this runs in parallel, all the parallel chunks will incrementally append their column names into the CSV. It’s a pain, it kinda works
I wish the parallel chunk end was a more forgiving about table specs
1 Like
Gave up on the parallel chunk hack… it requires executing it multiple times so that it captures all the column names
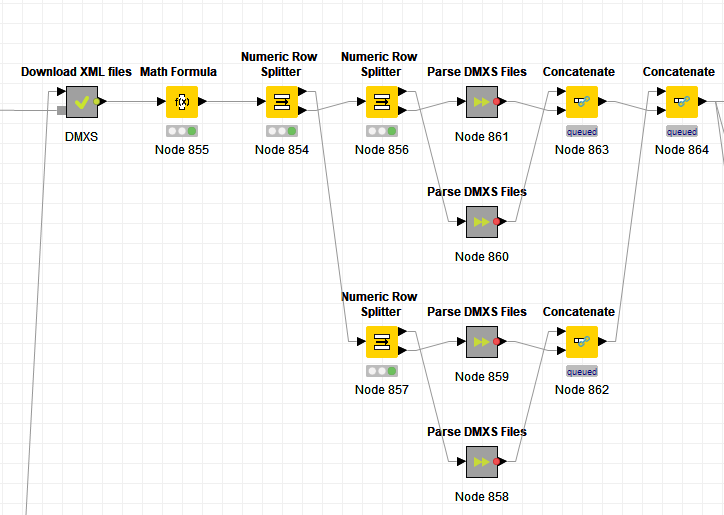
Ended up manually chunking the input table, parsing the files, and concatenating the resulting output.
The bummer is that I’d have to repeat the above 3 times so that I could fully use all the available threads in my system… and would have to adjust if I take this to another config… annoying… I guess some level of parallelism is better than none
How are you downloading your XML files? If you have a list of them, and loop one file per loop then I would strongly recommend using instead the Load text-based files node from the Vernalis community plugin:
followed by a String to XML node - this will almost certainly be much quicker.
Steve
3 Likes
Yes, I’m looping thru the list of files and loading each at a time. This sounds like a good solution to my problem
Thanks @s.roughley
1 Like
@s.roughley your idea about table creator lead me to a solution to:
- Extract table dimension and created an empty table with the amount of columns
- Extract column headers and insert into emtpy table
- Filter data table by columns only desired
- Use table concat with union
Thanks for the idea!
2 Likes