Gave up on the parallel chunk hack… it requires executing it multiple times so that it captures all the column names
Ended up manually chunking the input table, parsing the files, and concatenating the resulting output.
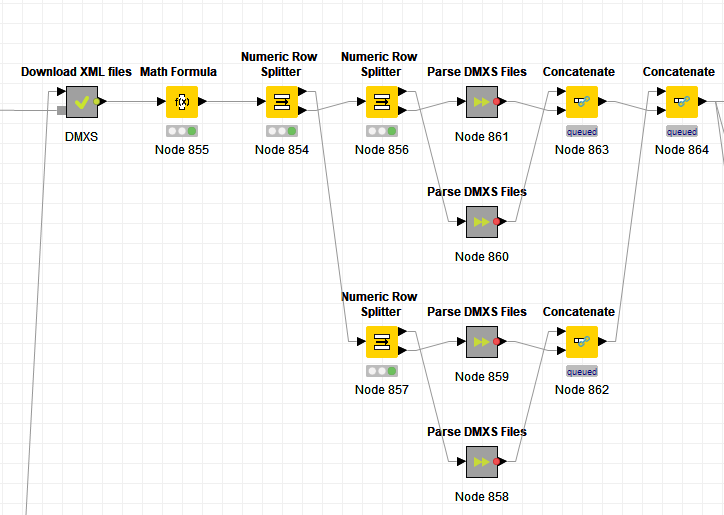
The bummer is that I’d have to repeat the above 3 times so that I could fully use all the available threads in my system… and would have to adjust if I take this to another config… annoying… I guess some level of parallelism is better than none