I'm running 4 Database Reader nodes (working on the same database but from different views) at the same time but I get around the same running time no matter if I run them parallel or one after the other. I've tried to create separate Database Connectors with different users for every Database Reader but the situation haven't changed. I know that there aren't any restrictions on database side regarding this.
Do you have any ideas how to achive real parallel running?
currently KNIME supports only one connection per database url and user name. By default KNIME also allows only one db operation per connection at a time.
One way to allow parallel operations is to use two different users to connect to the same database. This way you have two connection that allow you to run statements in parallel. The parallelwrite2postgres.png picture shows how 4 different users write in parallel to the same Postgres database.
If the used database driver supports concurrent operations per transaction you can enable this in KNIME by adding the following flag to the knime.ini file which is located in the KNIME installation directory:
-Dknime.database.enable.concurrency=false
I have to confess its a bit confusing but the concurrency flag has to be false to allow concurrent operations. Once the flag is set to false the two top branches that use the same user to connect to the database are also executed in parallel (see picture parallelwrite2postgresnosynchronization.png).
The same hold for other db operations e.g. reading.
I'm using KNIME to load data from several sources (databases) into a warehouse. In order to keep within the available timeframe, queries need to be in parallel. Currently I simply start multiple KNIME instances, each running one statement in parallel. This approach takes system's memory I rather spend elsewhere.
When running analytics on multiple sources, the limitation slows down the routines a lot. This can become a problem when running many iterations requiring newly queried data for each iteration.
Please do consider to prioritize the parallel connection / statement execution for an upcoming release!
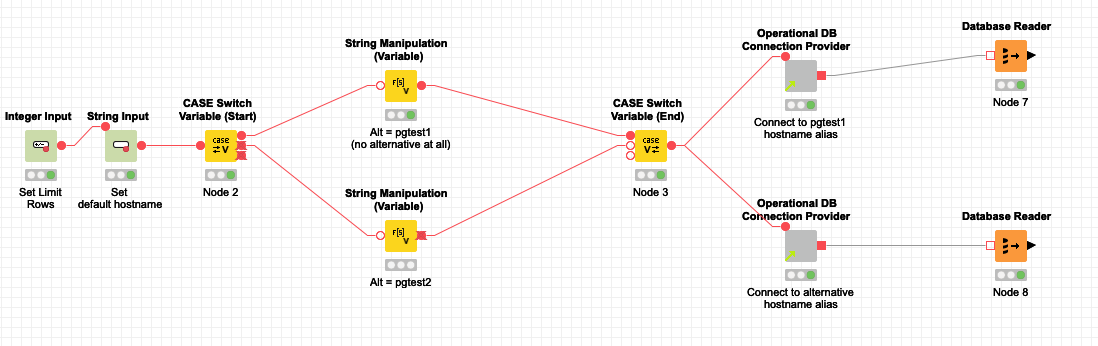
I think I’ve found a workaround too. It’s quite simple. I just added some lines to my /etc/hosts file as follows (let’s say 10.10.10.10 is an IP address of a database KNIME workflow is supposed to connect to):
10.10.10.10 mydb1
10.10.10.10 mydb2
10.10.10.10 mydb3
Next, I prepared several Wrapped Metanode containing String input nodes (hostname, username, db name, passsword) and Integer input node (port), one for each host-alias. All the Wrapped Metanodes (configurable and already pre-configured) provide connection to the same database with the same credentials they differ just in hostname which points to the same db server, though.
After that I combined using particular my connection-providing Metanodes the way I could ensure the nodes (instances of Database Writer, Database Reader and Database SQL Executor) I wanted for them to run in parallel, used connections KNIME considered different.
I performed some tests that convinced me my workaround works.
A test workflow had to read 10.000 rows from a database table. When I used single hostname for both Connector nodes, I could see from the visualisation, from KNIME console the Database Reader nodes worked one after the other one. Both got configured, both obtained their connection from a cache. But one of them performed all its step up to changing its state to EXECUTED before the second one started to execute its query. Feel free to look into knime.log: Single Hostname DB Connections.log (67.5 KB)
After I switched to different hostnames the behaviour got different. Both nodes worked step by step in parallel which is visible in the log: Different Hostname DB Connections.log (70.9 KB)
Well done.
And from the DB perspective, invoking select * from pg_stat_activity revealed one active connection in first case whereas there were two connections invoking the queries in second case.
But I’d appreciate KNIME provided me with a configurable connection pool management much more than this.
Let’s say that I need to write to several tables of the same DB atomically, i.e. if any of those writes fails, all of them should rollback. For that, I need to include them within the same transaction, which is defined over a single DB connection. From what I understand, the writes will then happen sequentially.
It is not entirely clear to me what the knime.database.enable.concurrency flag does. @tobias.koetter speaks about the need for support from the DB driver for concurrent operations per transaction, but his example parallelizes operations executed through different connections, which therefore cannot be part of the same transaction. So, what the flag seems to enable is not concurrent operations per transaction but concurrent operations across connections.
Hello,
the above mentioned post are all related to the old database framework and not valid for the new database framework which was introduced with KNIME Analytics Platform 4.0.
If you want to perform several database manipulations within a single transaction you need to use the dedicated transaction nodes that define the transaction scope otherwise each DML node (write, delete, update) will be considered as one transaction.
To run multiple database operations simultaneously you need to use multiple DB Connector nodes. Each node represents one database connection that can be used in the workflow.
Bye
Tobias
Thank you @tobias.koetter. My question is: can I do several DB operations in parallel within the same transaction, so that all of them are rolled back if any of them fails? I don’t see how to achieve that if I have to set up multiple DB connections to run the different parallel operations, given that the transaction nodes work on a single connection.
I see, no you can not do multiple DB manipulations in parallel. This would require a cross connection transaction which is not supported in KNIME Analytics Platform.
I was mistakenly thinking on PostgreSQL, but I see that indeed it only supports a single concurrent operation per connection. A workaround could be to implement the KNIME transaction as a “distributed” one using a two-phase commit. In that case, a new DB connection would be established under the hood (using the settings of the KNIME DB session) and a new DB transaction started for each branch executed in parallel within the KNIME transaction. Making all branches end on a single DB Transaction End node would allow it to prepare the various DB transactions, and commit them only if the preparation completed successfully for all of them.
Thanks for the info. I agree that Two-phase commit using XADataSources could be used for such a case. I will open a feature request for this.
Bye
Tobias