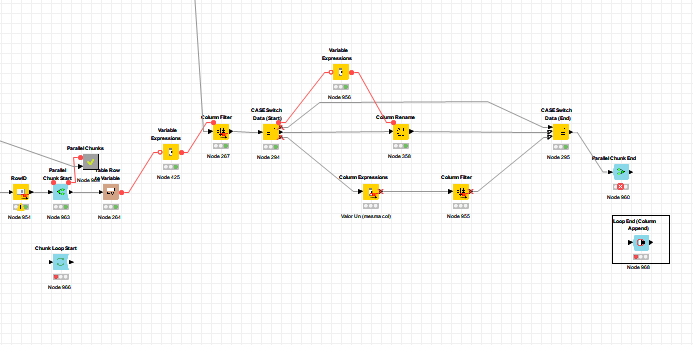
I have a loop and first I was using a Chunk Loop Start and the end I was using a Loop End Column Append. This is because I do a filter in the middle of the loop and add new columns. However the parallel loop end is giving an error, saying that the row id is duplicate, but this is due to the aggregation of new columns. Does anyone know if it is possible to get around this in any way?
My loop goes through lines that I transform into variables, I use those variables to filter in another table.
With these filtered columns, I do my manipulations (Case Switch). That is, the RowId will be really duplicated, because each time the loop goes through, it brings all the rows, but different columns, that’s why I used Loop End Column Append in the first moment, but I need performance, that’s why I’m trying the parallel chunck .
seems to me you need to use Loop End (Column Append) node in your case and try to optimize your loop body for performance. How many iterations you got? Is there some node for which execution lasts a lot?