Hi,
I want to process multiple Excel files in parallel without using loops in KNIME, based on dynamic routing from the List Files/Folders node. Each file will be routed to a specific workflow depending on its sheet name, allowing for parallel processing. The file order may change, and there can be more than 3 files at times. For instance, if there are 3 files, each file should be routed to a separate workflow running in parallel, ensuring that each file gets processed independently of the others. The file paths and sheet names should be dynamically handled without looping, and all workflows should run simultaneously.
@san_98 will the sub-workflow(s) which are being called processing the Excel files all be the same or do they have different functions and if so will the input and output ports differ?
Is there a specific reason not to use loops?
Hi @mlauber71 ,
Thanks for the quick response.
The sub-workflows being called for processing Excel files will be the same, but the SQL table used within the workflow will differ based on the specific Excel file being processed. For Excel 1, the workflow will query a certain SQL table for data insertion, and for Excel 2, it will query a different table for data insertion. Essentially, the parallel workflow logic remains consistent, but the table names will change dynamically depending on the input file.
Reasons to Avoid Loops:
Parallelism: When using loops, KNIME processes one file at a time, which can be slower for a large number of files. Parallel processing allows multiple files to be processed simultaneously.
Looking at your screenshot I want to make you aware of the following: If you use the Table Row to Variable node, it will turn the first row into a variable only.
In order to process both paths you’d have to iterate over the table using e.g. Table Row to Variable Loop Start Node.
I think if you indeed go with an approach that calls a different workflow (e.g. via Call Workflow Service node) you may be able to go with minimal “conditional” logic inside your loop (pretty much just the “routing logic” that determines which workflow has to be called) and provided that the Call Workflow Service Node does not have to return an output that is processed in your caller workflow, any looping delay may be negligible.
Here’s a very minimal example…

CallerCallee.knar (243.9 KB)
Edit:
I actually just tested this and it looks like even if you don’t expect something to be returned the loop still only continues once the workflow you call finishes…
Right now I am actually not sure how to make it work that both processes happen in parallel.
1 Like
The problem you wil be facing is that you can process jops in parallel in KNIME but in your case the SQL commands might query the same database/database connection. The question will be how to make sure that this will accept parallel connections. What kind of database is it BTW?
Also: why do you need sub-workflows? You might as well use Components or Metanodes that could run in parallel.
1 Like
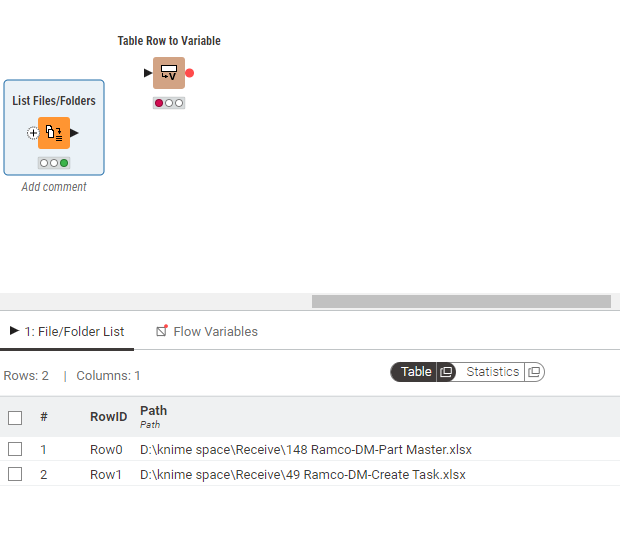
I used the List Files/Folders node to retrieve all the files available in the folder, regardless of the file name. Then, I used the sheet name to read all the available sheets in the Excel files. In my case, I will have more than three sheets in the Excel file. After retrieving the sheets, I applied the Rule Engine node to split the workflow based on conditions.
- If the sheet names are the same, the workflow runs in a loop to process the sheets.
- If the sheet names are different, the workflow runs in parallel to process them concurrently.
This approach ensures that when the sheet names are identical, the process loops through them one by one. If the sheet names vary, the workflow executes in parallel for efficiency…
Please refer the workflow attached.
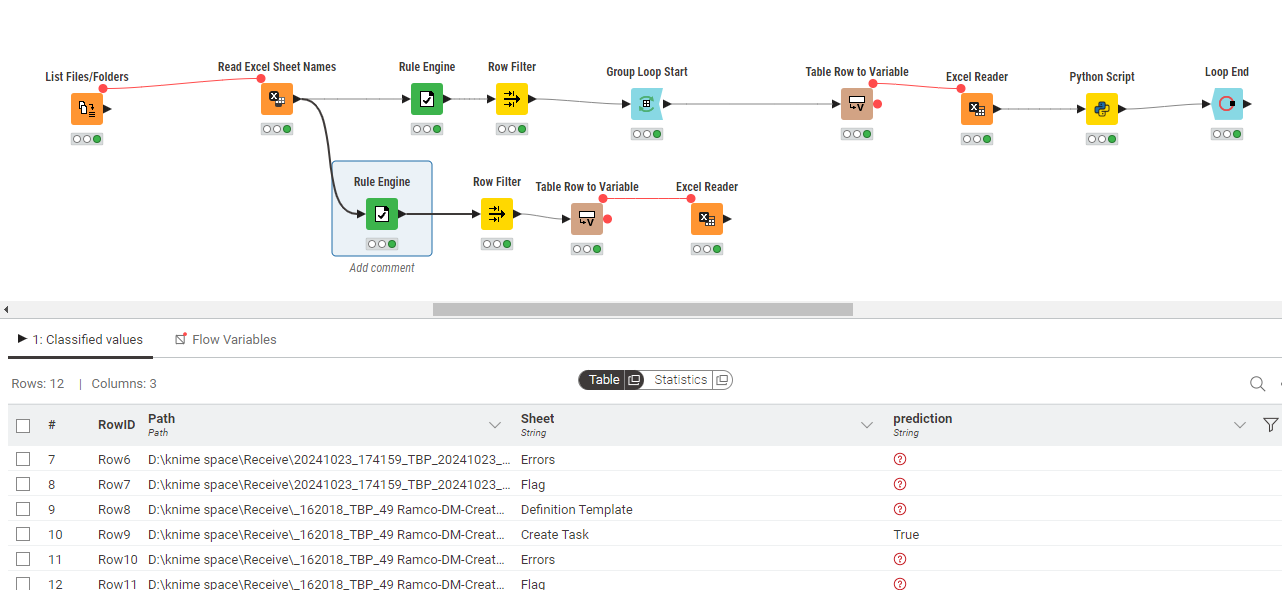
@san_98 In your screenshot I do not see any Parallel Chunks and no database access, but if you are fine we are fine ![]()
For the fun of it I expanded on @MartinDDDD workflow and constructed a parallel access with a database node calling sub-workflow(s) that would then use this connection. So far it seems to work although any benefits in speed might depend heavily on the actual database(-connetion) supporting parallel access.
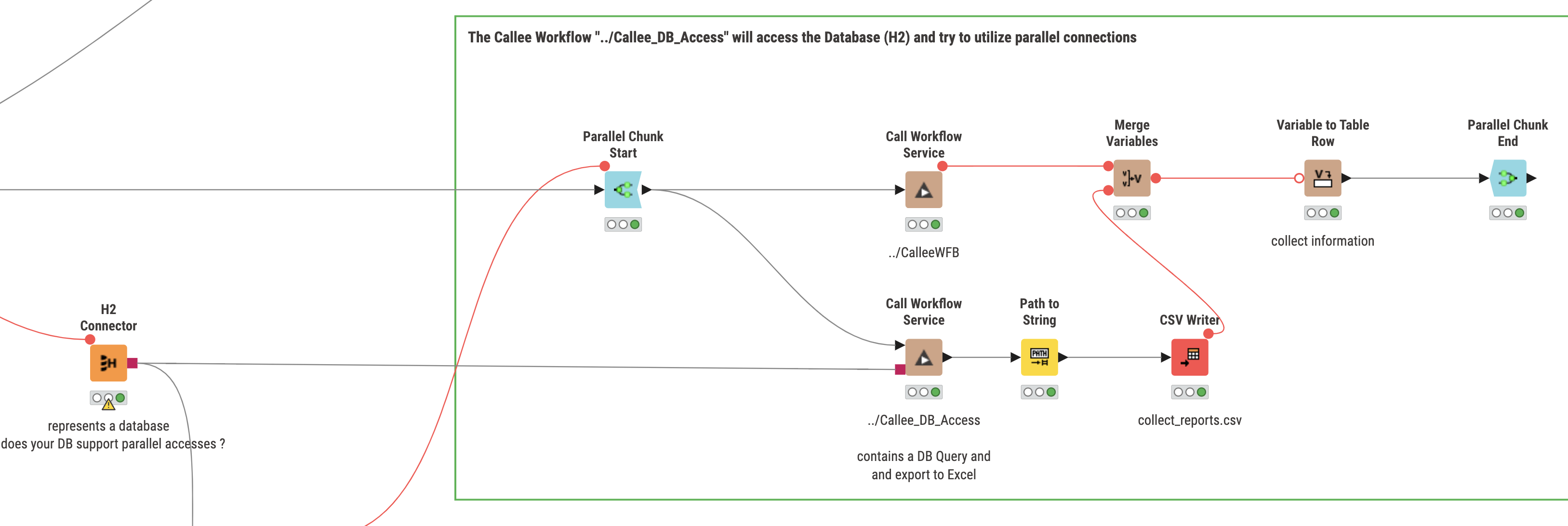
The callee workflow does look like this:
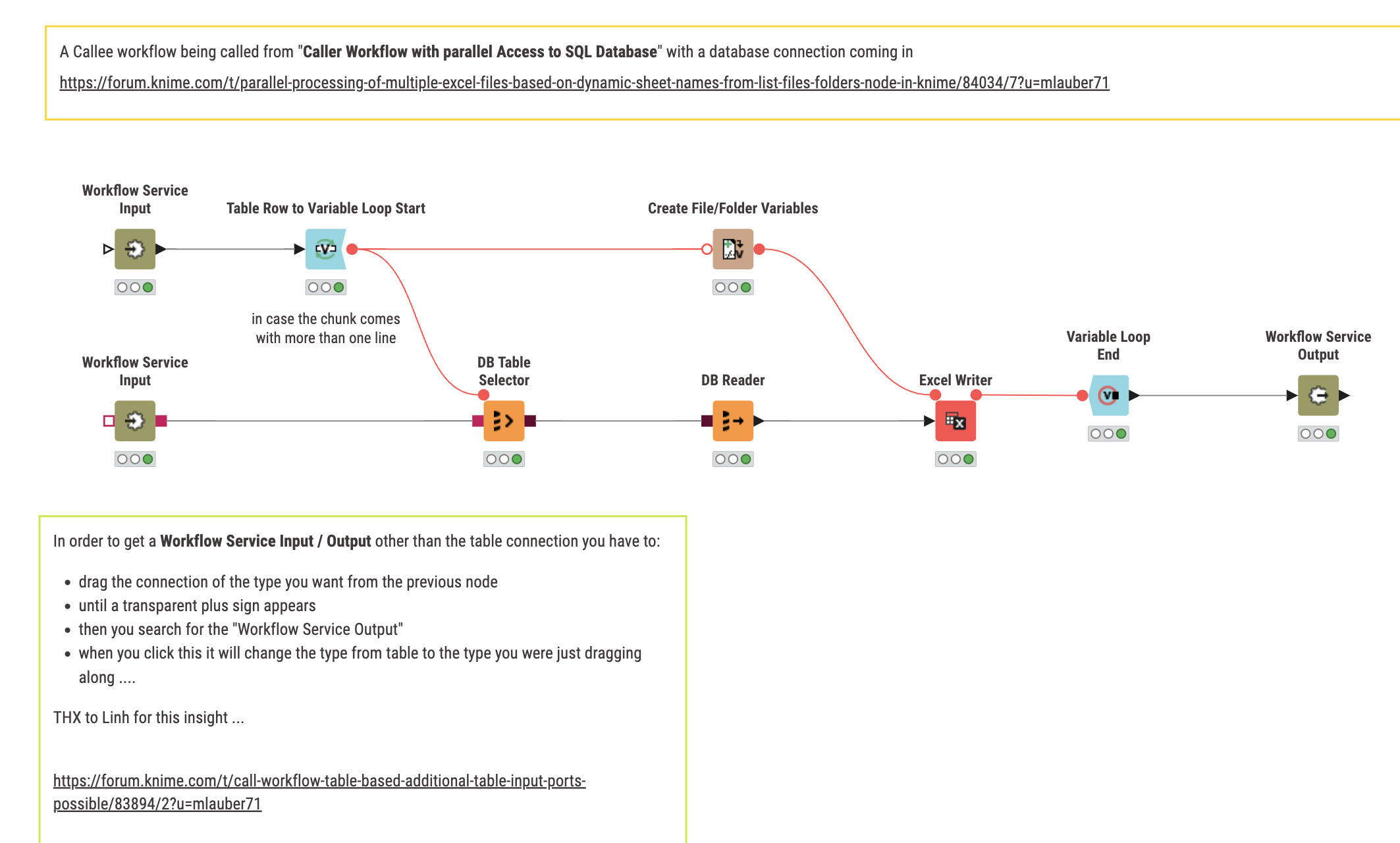
If you want you can explore this further
3 Likes
Hi @mlauber71 ,
Thanks for the solution!
It seems that the workflow runs in parallel without the Parallel Chunk Start node in my case. Additionally, I couldn’t find the Parallel Chunk Start node in my KNIME 5.3.2 version. We are performing some Excel sanity checks using a Python script, and after that, we’ll add the MS SQL connection for further parallel processing.
Is your KNIME version above 5.3.2?
@san_98 you might have to activate the All Nodes settings:
If the extension is not installed knime should prompt you to do so once you load a workflow that requires it.
You can also install additional extensions

3 Likes
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.