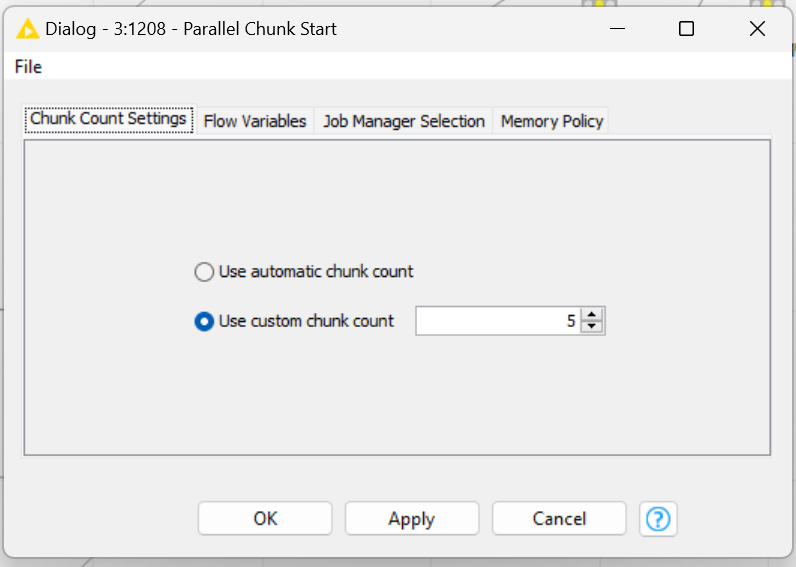
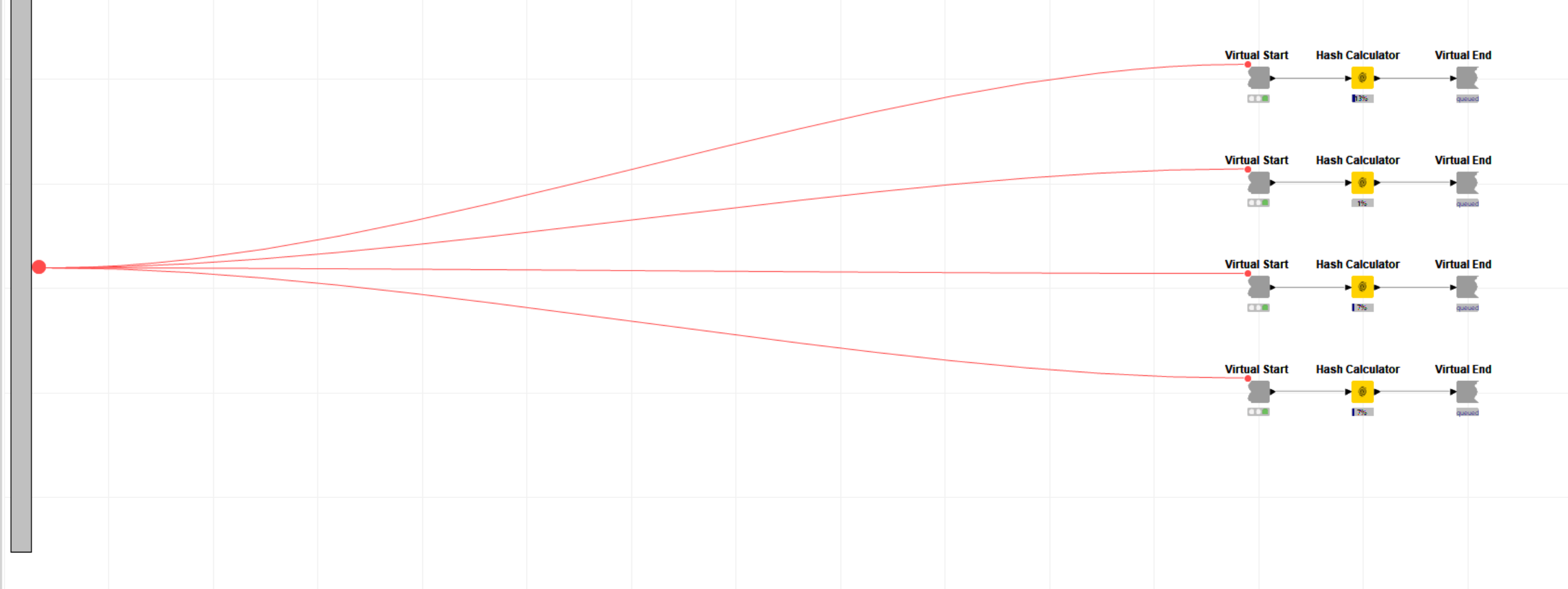
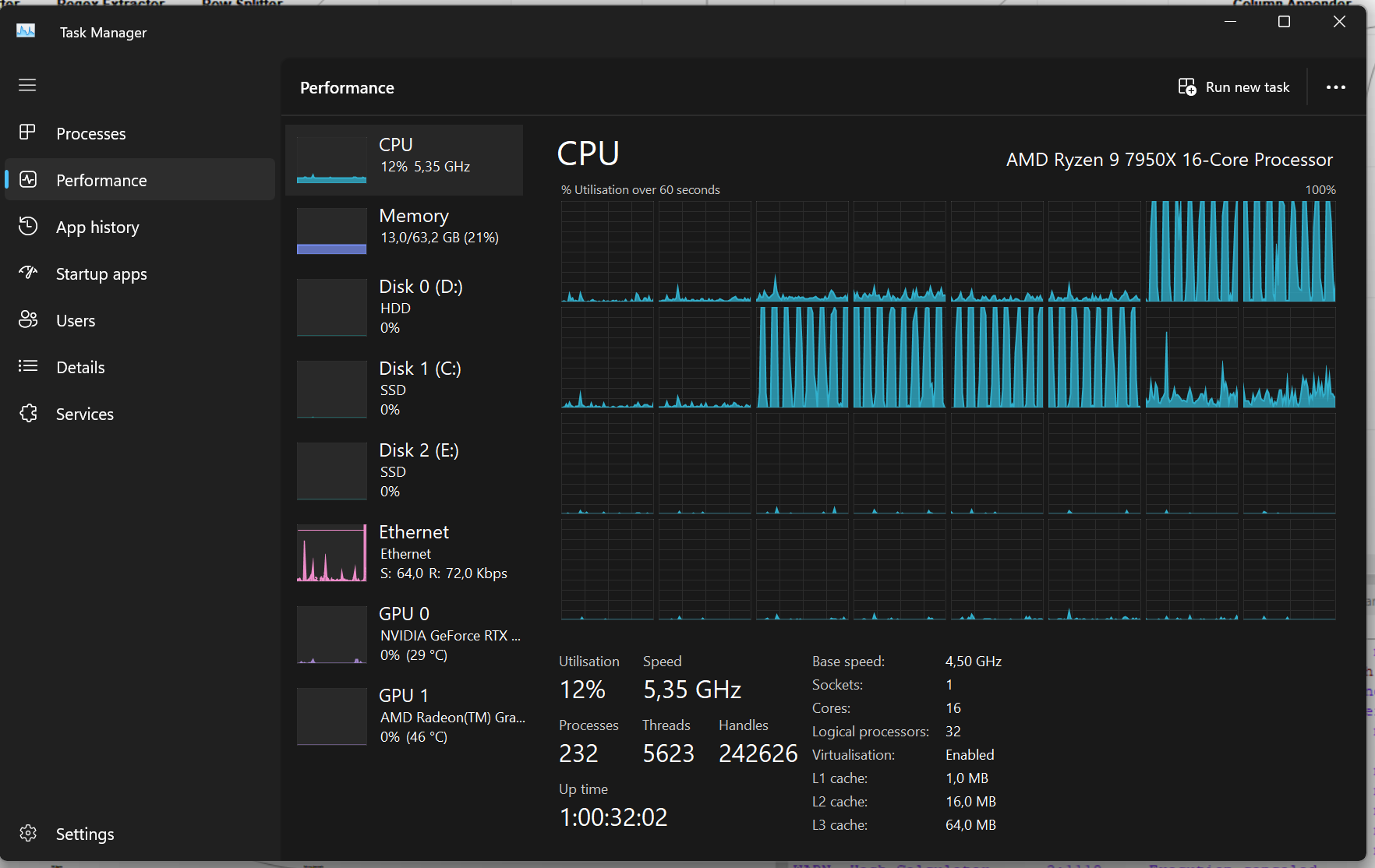
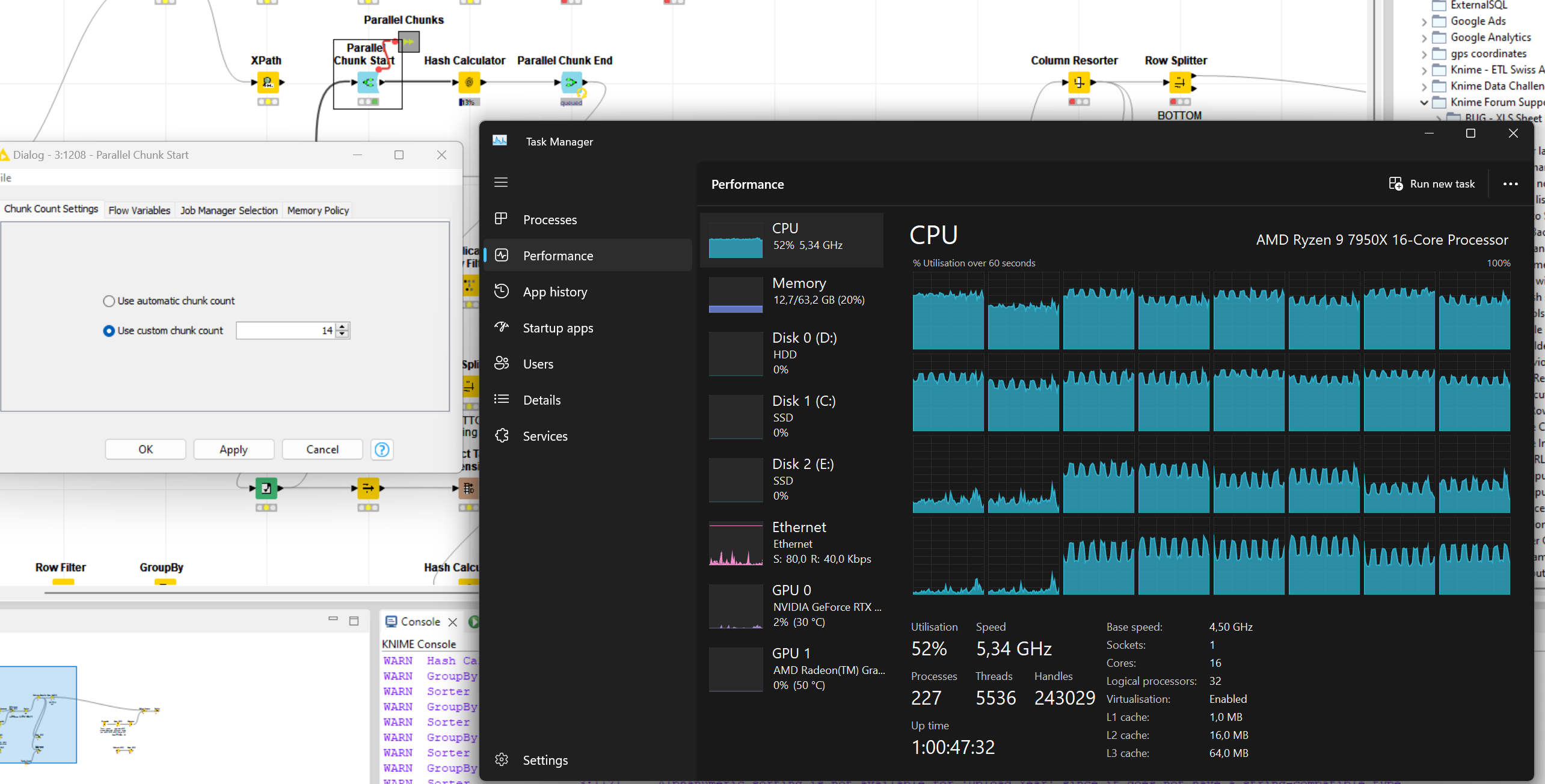
while running some tests I noticed that the Parallel Start / End nodes setting does not reflect the number of CPUs utilized. This might result performance “choke points” or task in collisions, in case the number is important.
As follows you will see I set the chunks to five but six CPUs are utilized. Opening the meta node, there are only four chunks, plus the one from the “root level”.
The number of chunks refers to the number of - well - chunks that input table is split. It has no direct relation to the number of threads except that more chunks can make use of more threads. Some nodes inside the loop can run in parallel on their own and there are other internal threads as well which will result in more threads being active than there are chunks.
Reasonable, thanks for the explanation. Is there any indication / documentation which nodes are optimized for multi threading? I have submitted another topic about a setting. Sometimes, the unpredictable or difficult to comprehend behavior of Knime or it’s nodes makes it challenging to optimized workflows to utilize system resources efficiently.