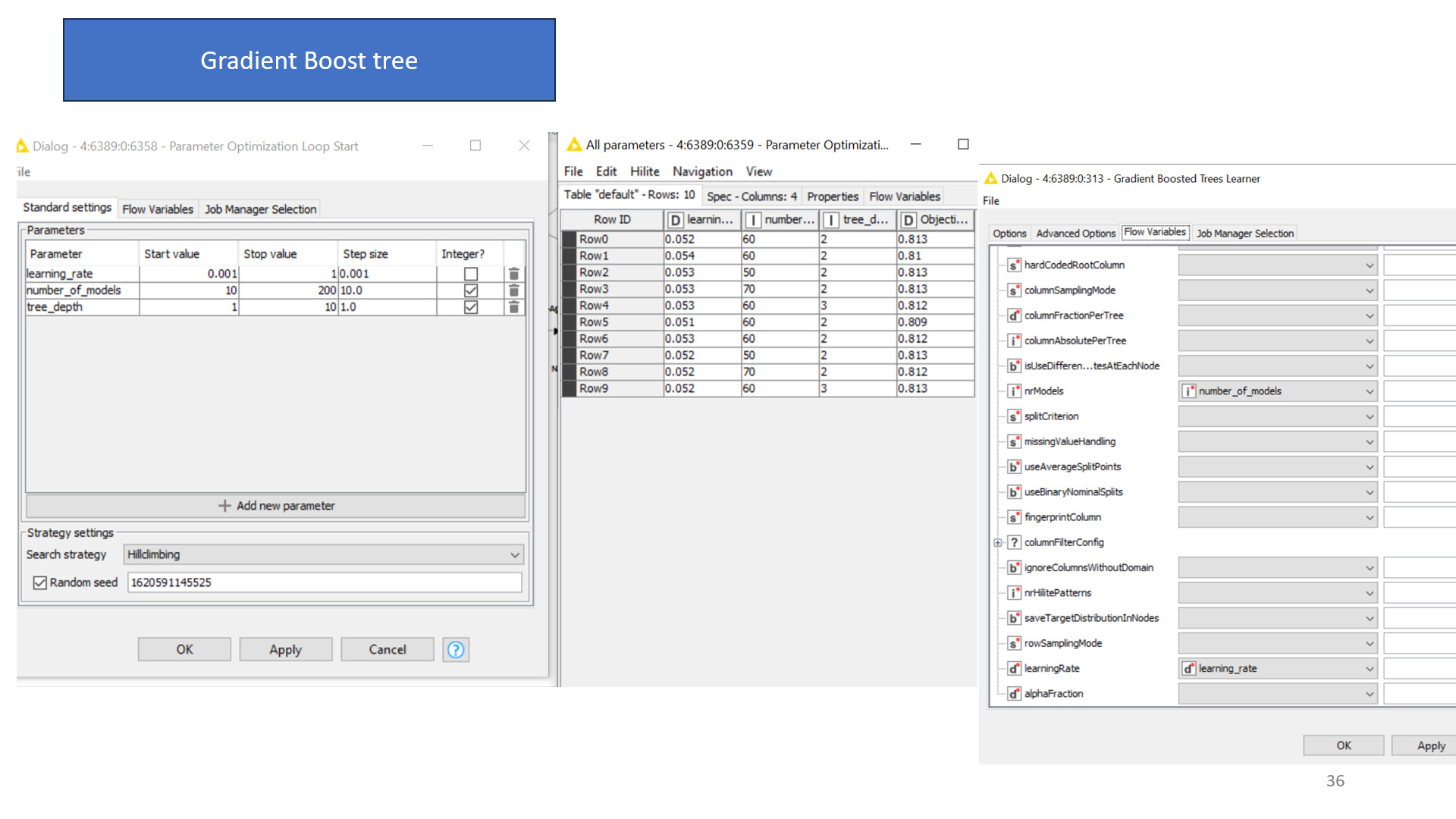
I optimized my selected model, but I cannot deploy the model with the optimized model
.
It’s pretty much impossible to help you, because you haven’t provided any information.
Please read this and try again:
Okay thanks for the correction I’ll prepare a query with proper information.
Hi,
This is a problem with scopes, as both the loop and the integrated deployment nodes form blocks that cannot “overlap” like that. But that’s easy to fix. In the end, you only want to deploy the model with the best parameters anyways, right? You should use 3 data sets: training, validation, testing. Because right now with the partitioning, you are using your test data for training, as choosing hyperparameters is also a form of training. So before all these loops, split up another data set (10-20% maybe) and use that after the hyperparameter optimization to test your model. Here you will need another predictor node and this you can capture easily with the integrated deployment nodes, as it is not within any loop. Making this change makes your approach more sound in terms of data science and enables you to use integrated deployment as it is intended.
Hope this helps!
Alexander
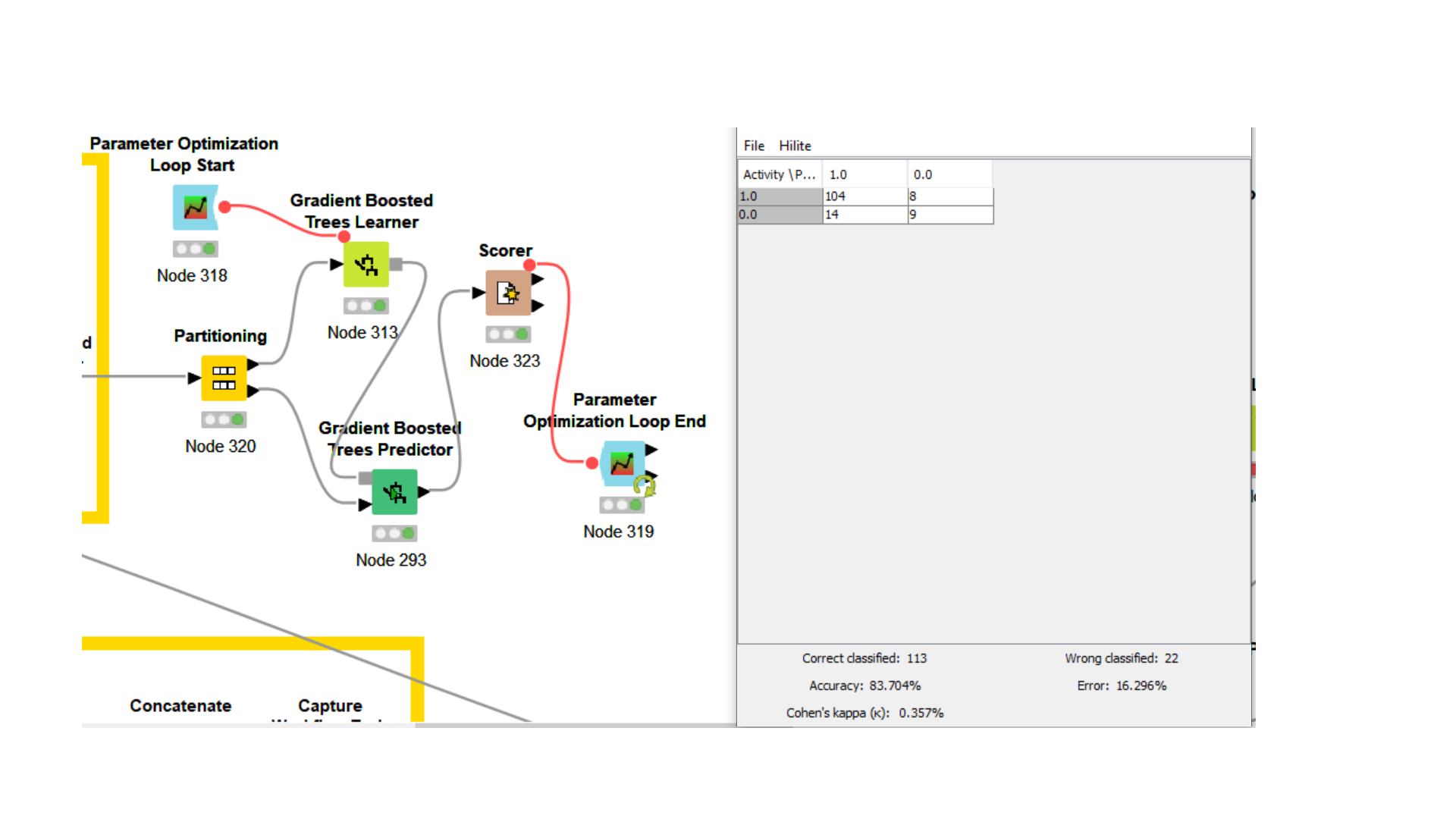
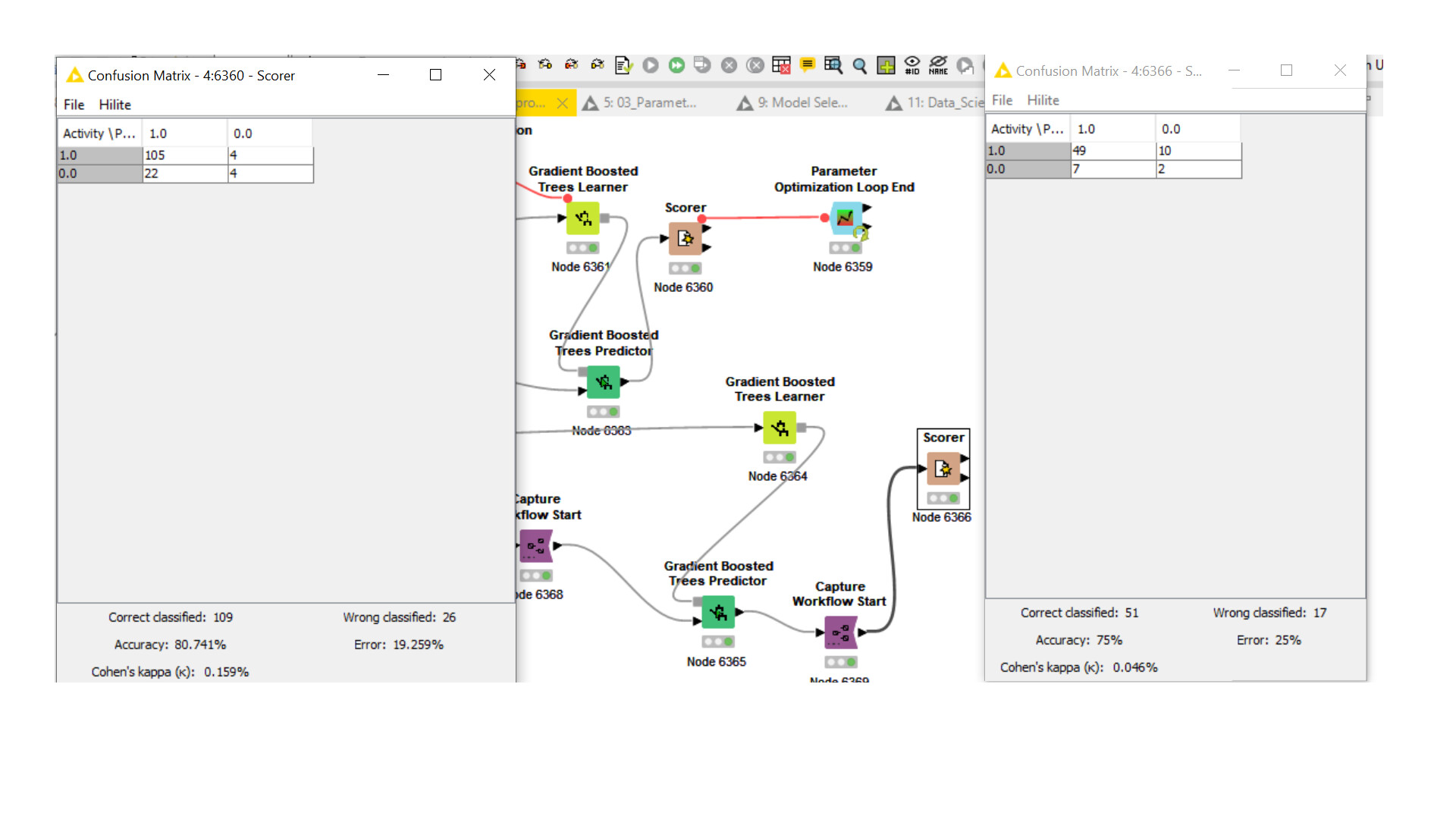
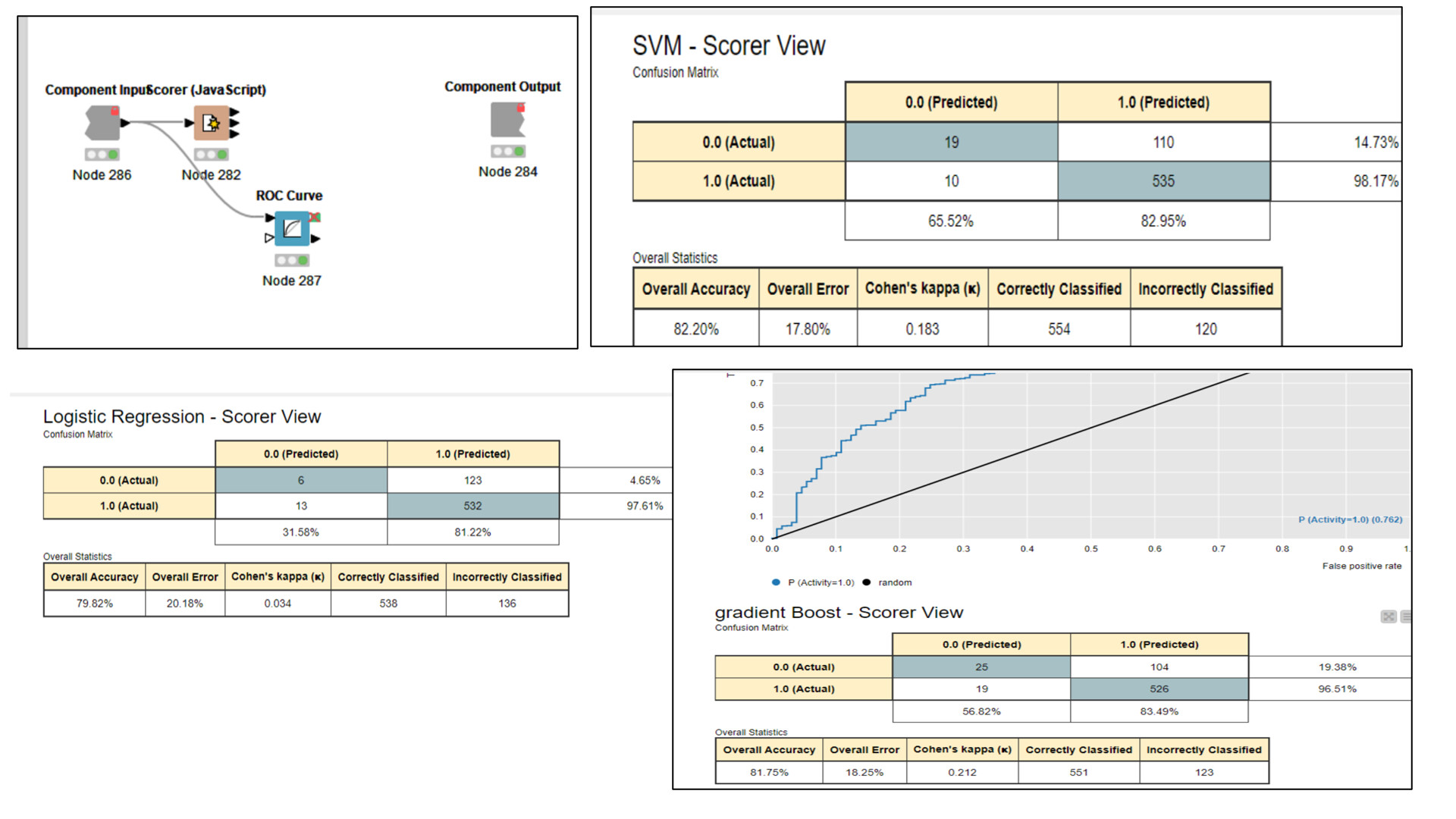
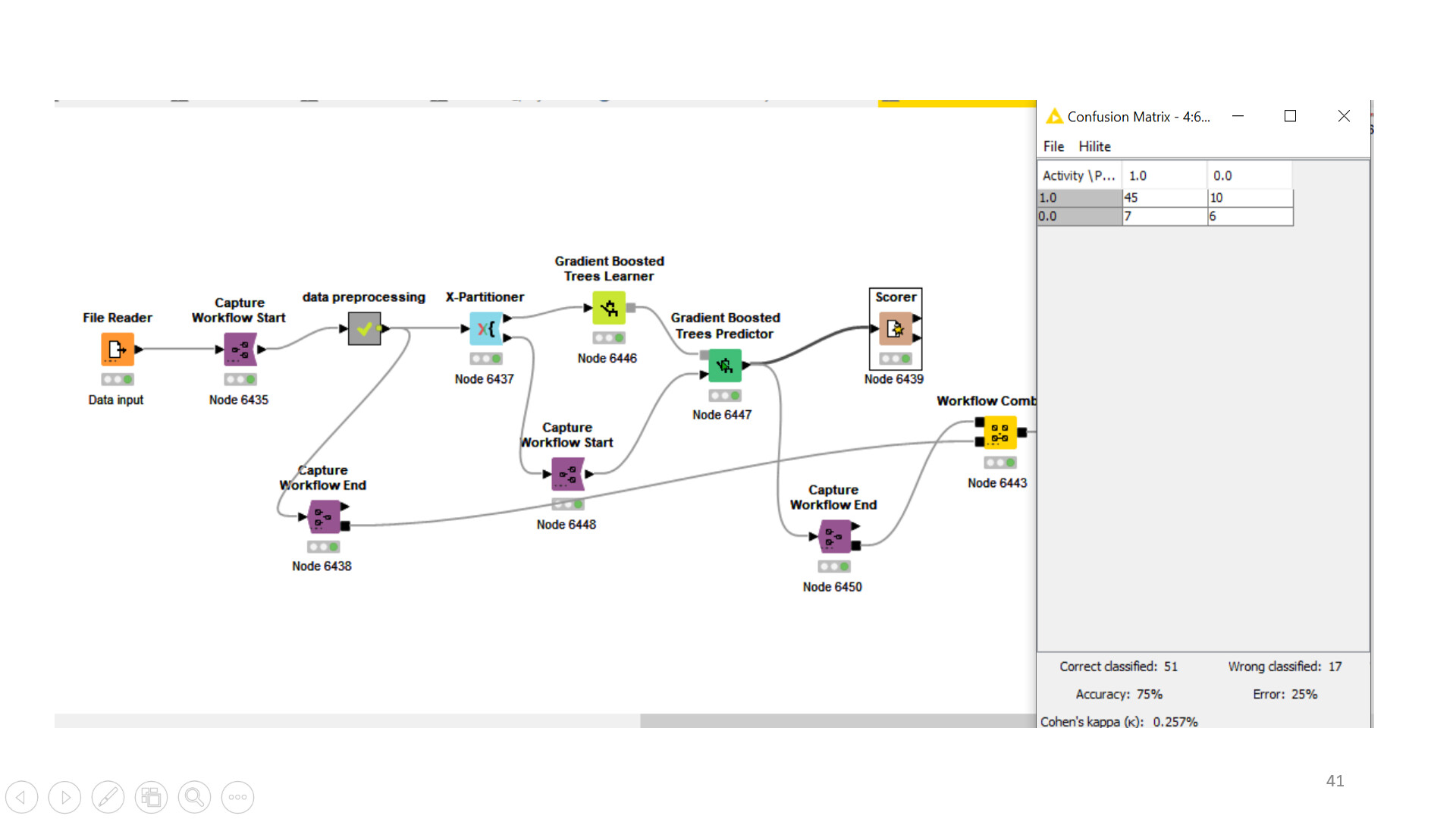
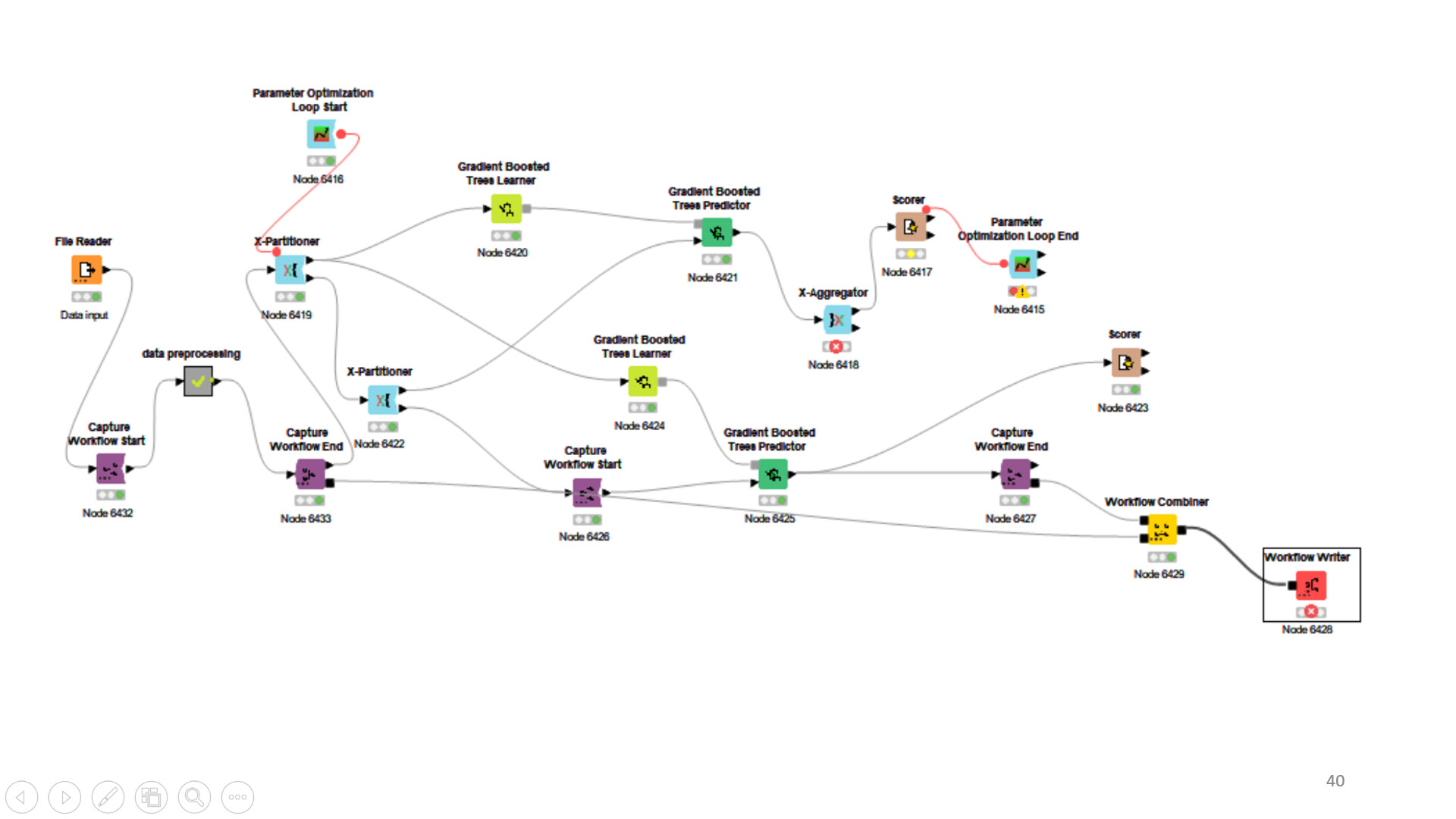
Hi Alex, Thank you for your response, I took your advice and divided the dataset into three section and could deploy the optimized model. However, after dividing the dataset into three sets the accuracy decreased from 83% to 80% and after using the best parameters from the (80% accuracy) the model gave an accuracy of 75%.I will show the initial optimised model and the one i got after splitting the data into three parts. Kindly help
Hi,
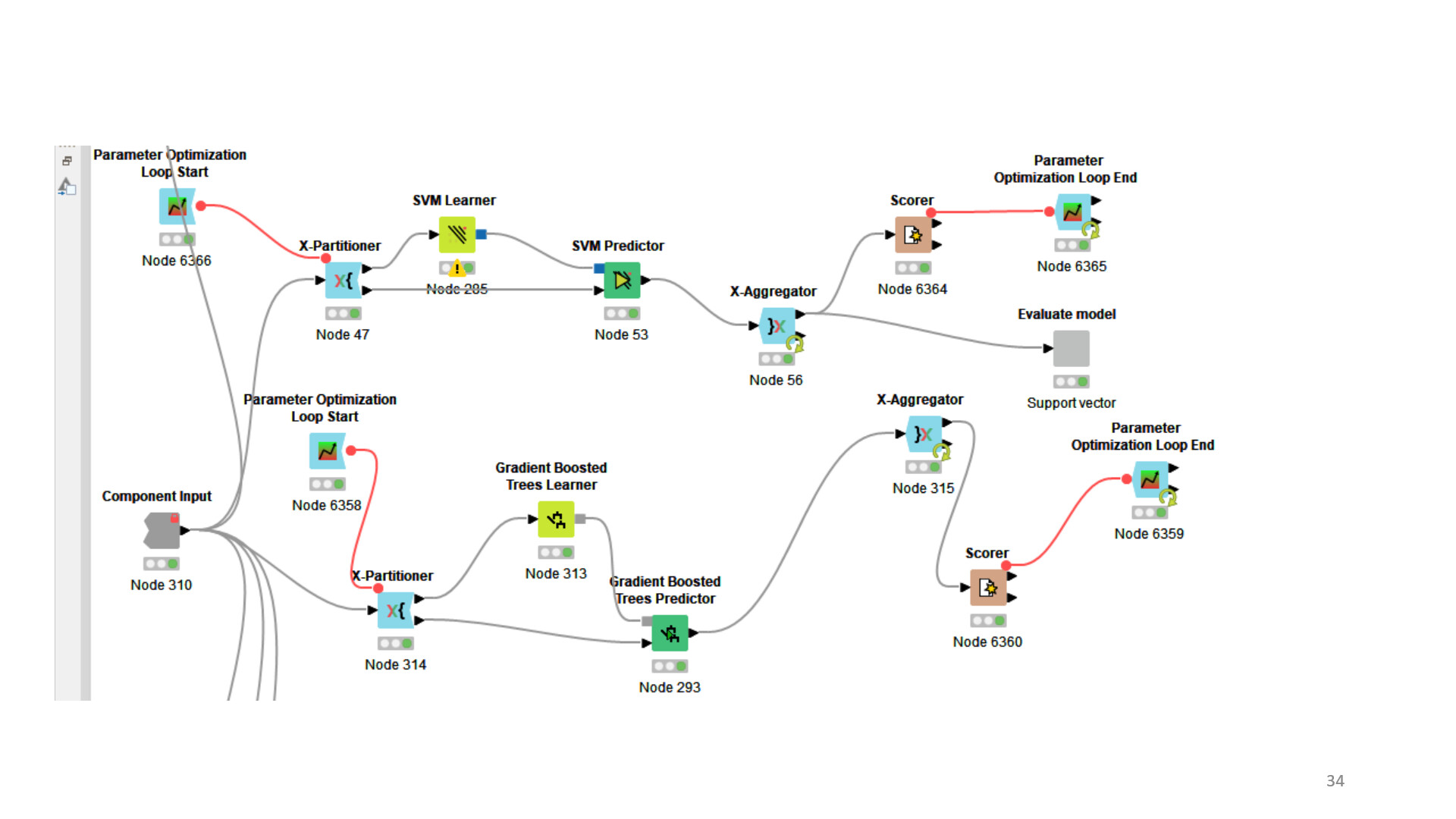
You are splitting your data into 4 parts now. This is not necessary. The bottom Learner node can be trained on all the data going into the parameter optimization. You just need a hold-out that has never been touched for the model quality estimation. Additionally, of course your partitioning may yield different results in different runs because it is a random process and the training data may vary. One way to make this more stable is to use cross validation (X-Partitioner and X-Aggregator nodes).
Kind regards
Alexander
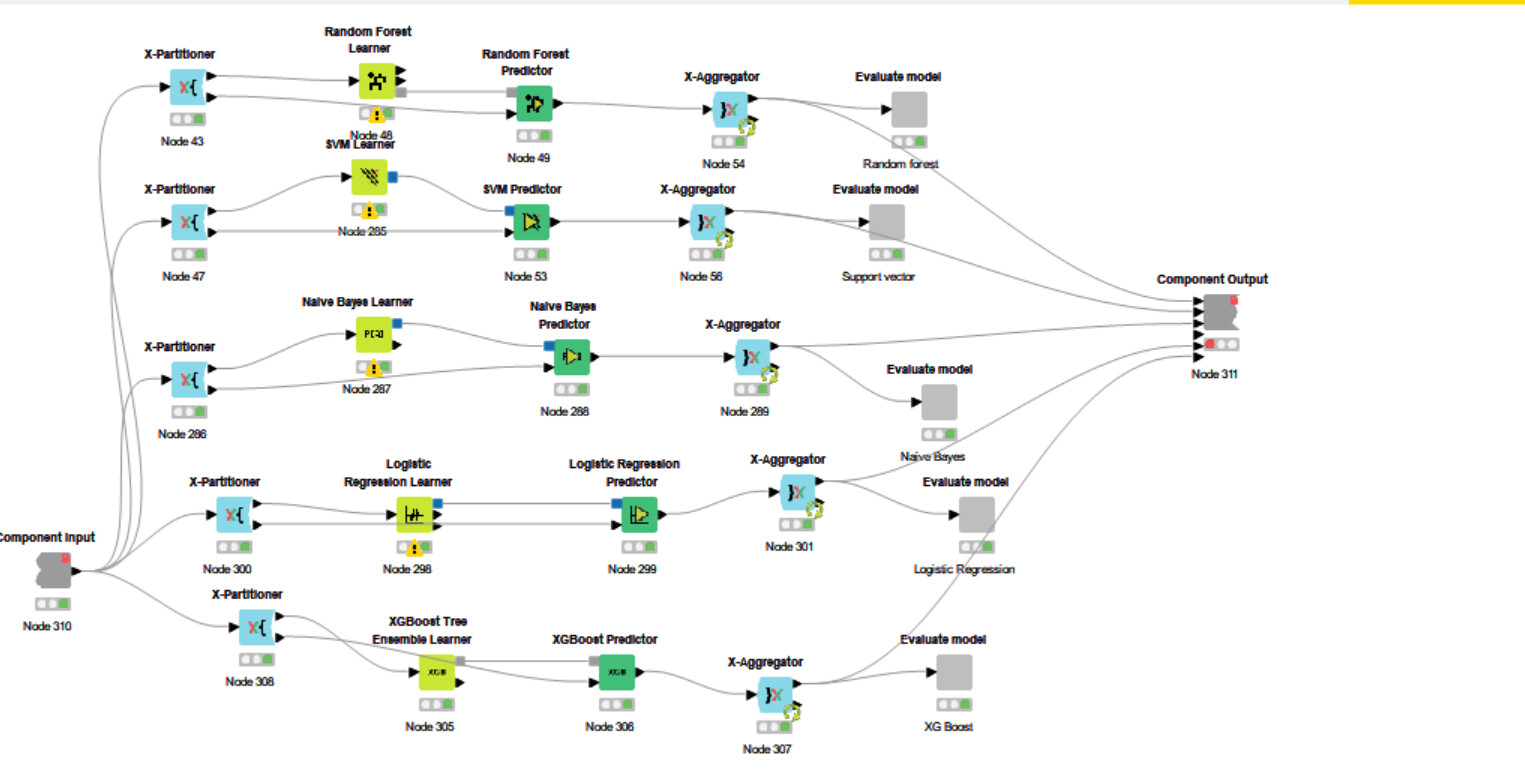
Thank you again Alex, I added few data points to the final dataset and checked the performance of six models and now SVM model is giving me the best ROC and accuracy.Wanted to ask is this the correct way of using all the nodes so that I can go ahead with assurance to optimized the parameter of the best mode ie SVM
Hi,
The cross validation looks good now. But do you know if with optimized parameters SVM is still the best model? You could also do the cross validation inside the parameter optimization, but that becomes computationally expensive real quick. What happens in the “Evaluate model” components?
Kind regards,
Alexander
Hi Alex thank you again for the prompt response and here in evaluate model i used scorer and roc nodes to check for the accuracy and roc parameters of each model. Here SVM shows the best accuracy followed by gradeint boost.I wanted to parameter optimization only to the best model as it was hard for me to performed optimization on all. kindly sugesst what I can do best and if theres any workflow I can follow for optimization and deployemt of the same.Thanks
Hi,
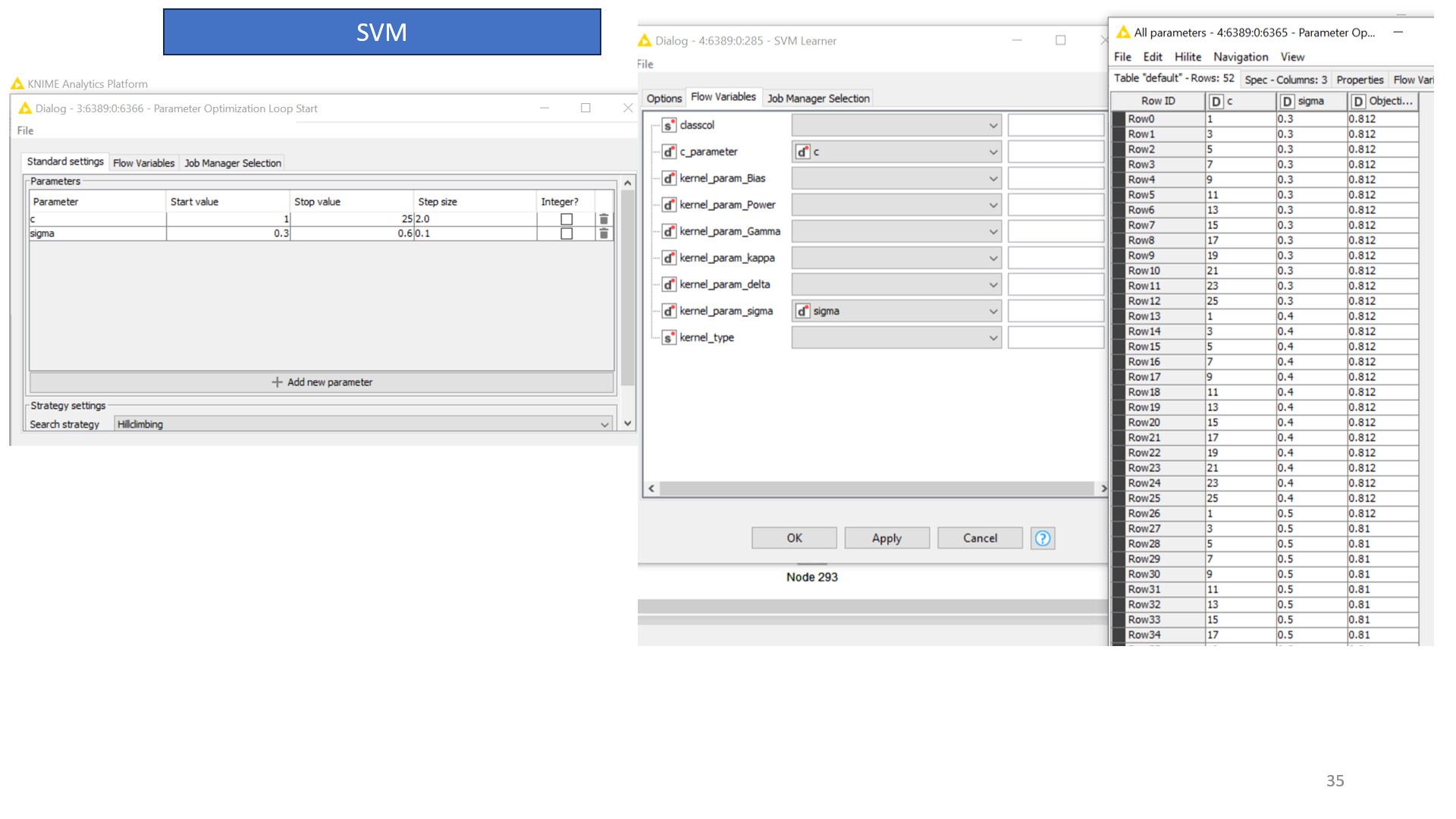
The way you do it now is also ok. You are using the out-of-bag predictions to evaluate the model, but in the end you should also test it on some hold-out dataset. Before you do that, you can do the parameter optimization. Inside that, you should also do cross validation, because a single random split can yield unstable results. Simply do your parameter optimization loop and inside use the cross validation loop with let’s say 5 folds to make sure the calculated accuracy is not just some fluke. Be aware that with your unbalanced target column accuracy is not super expressive. For comparison it is probably good enough, but Cohen’s Kappa may be the better metric for you.
Also, because you have an unbalanced class, you should use stratified sampling if you haven’t done so yet.
Kind regards,
Alexander
Hi,
This looks correct. My advice was not really geared towards making your model perform better, but to have a better understanding of its performance. With your setup like that, you should get a similar performance on the hold-out dataset and hopefully also on completely new data.
Kind regards,
Alexander
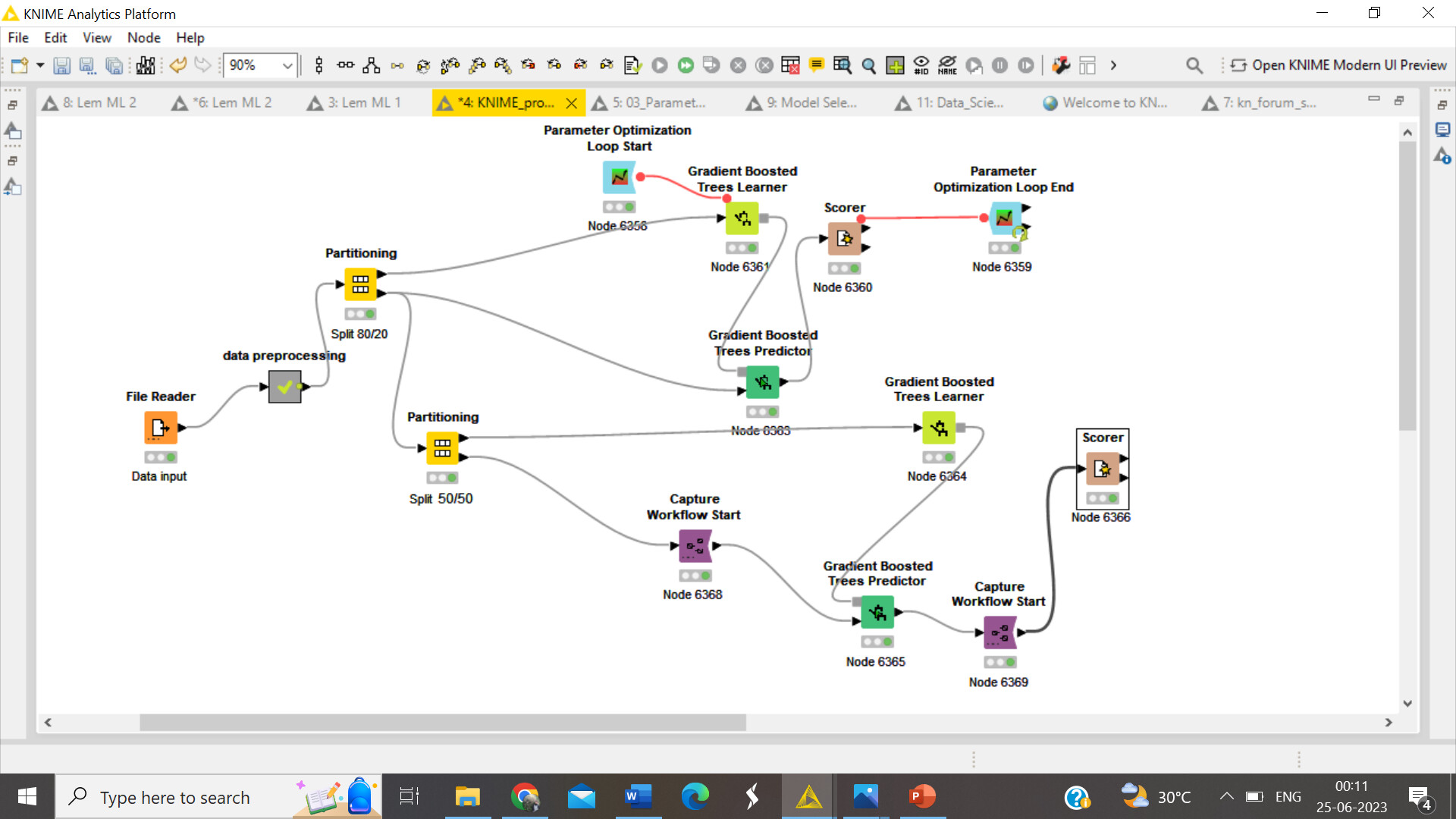
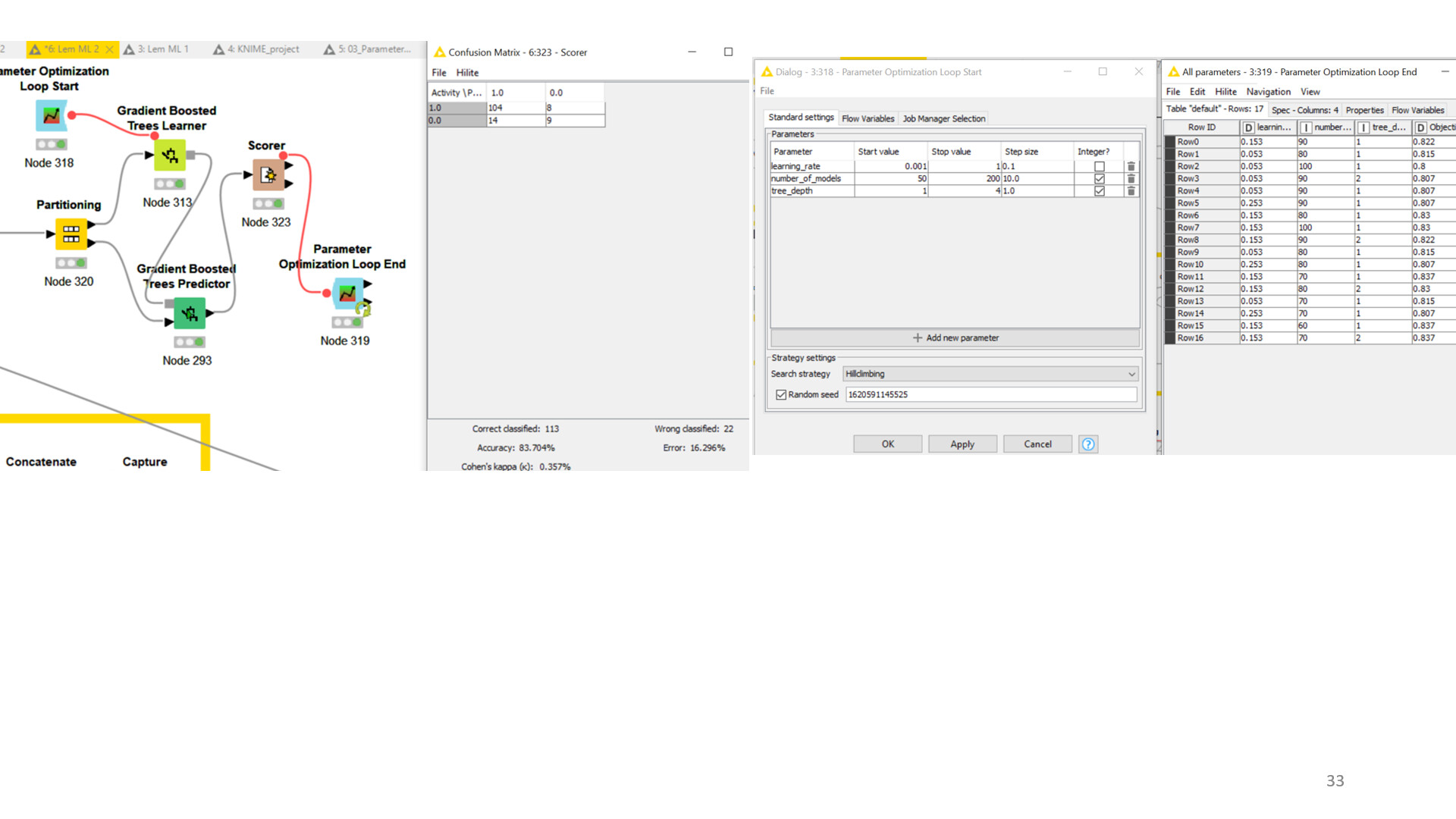
Hi Thank you again for the response and I went ahead with the best parameter for the Gradient boost tree model, However I am still struggling to deploy the desired model with the desired best parameters.When I divide the data into two portions using the same Xpartition and theb X aggregrator is not being executed,
And I tried using the best parameters to the model directly from the same dataset however the accuracy decreased, if there a work flow I can follow to solve this problem
Hi,
Why do you have two X-Partitioners? This should not be necessary. After the preprocessing you need a Partitioning node to split off a hold-out dataset. Then you train your model on the rest, including parameter optimization and cross validation. Once the best parameters are selected, you train your model again with the best parameters, but without cross validation, on the whole dataset excluding the hold-out. Then you apply your model to the hold-out and check its performance. This is where you can capture the predictor node.
Kind regards,
Alexander
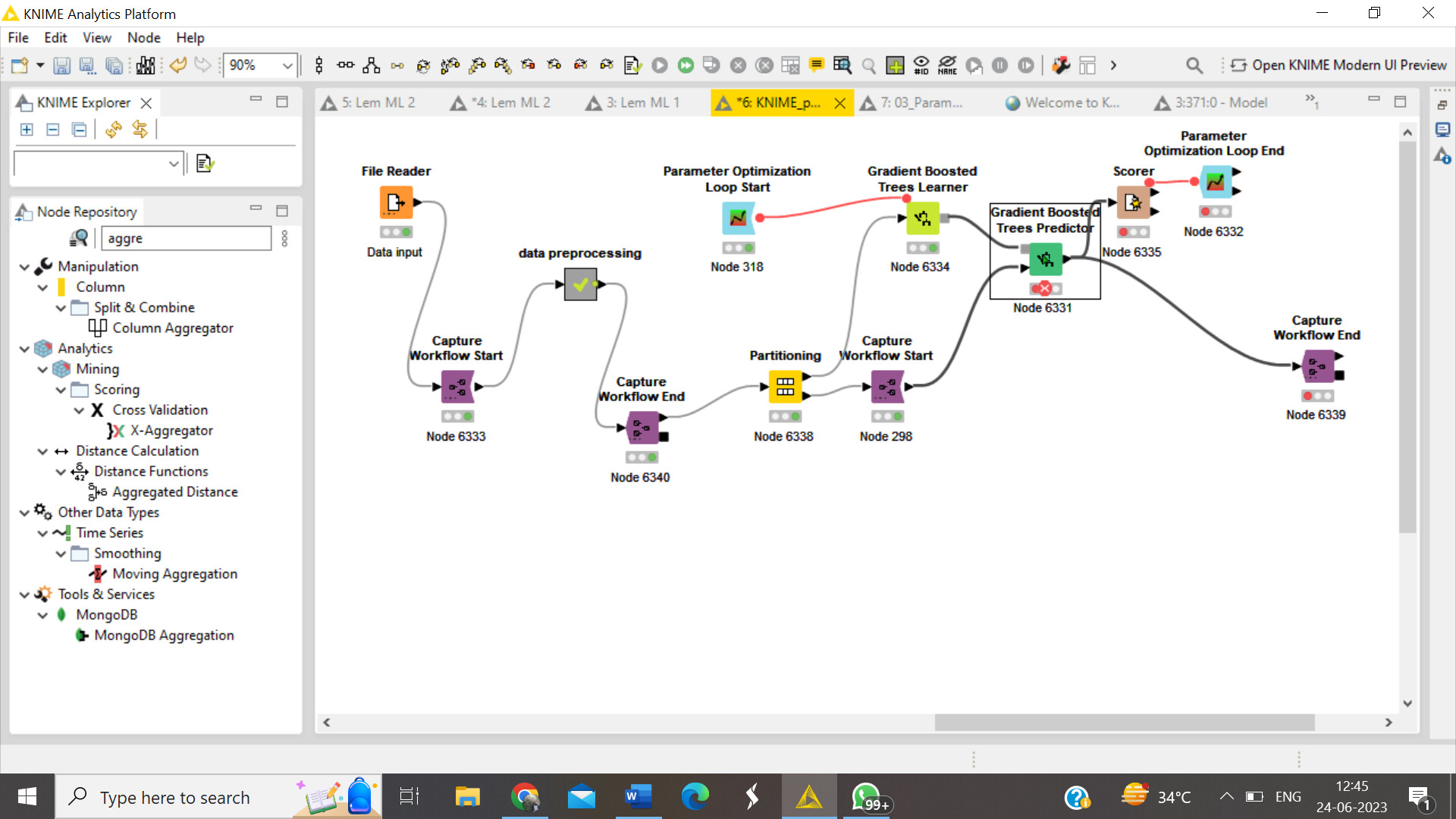
HI Alex,
Thank you for your suggestion, I could perform it sucessfully
@Lemnaro
How does the workflow look now?
br
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.