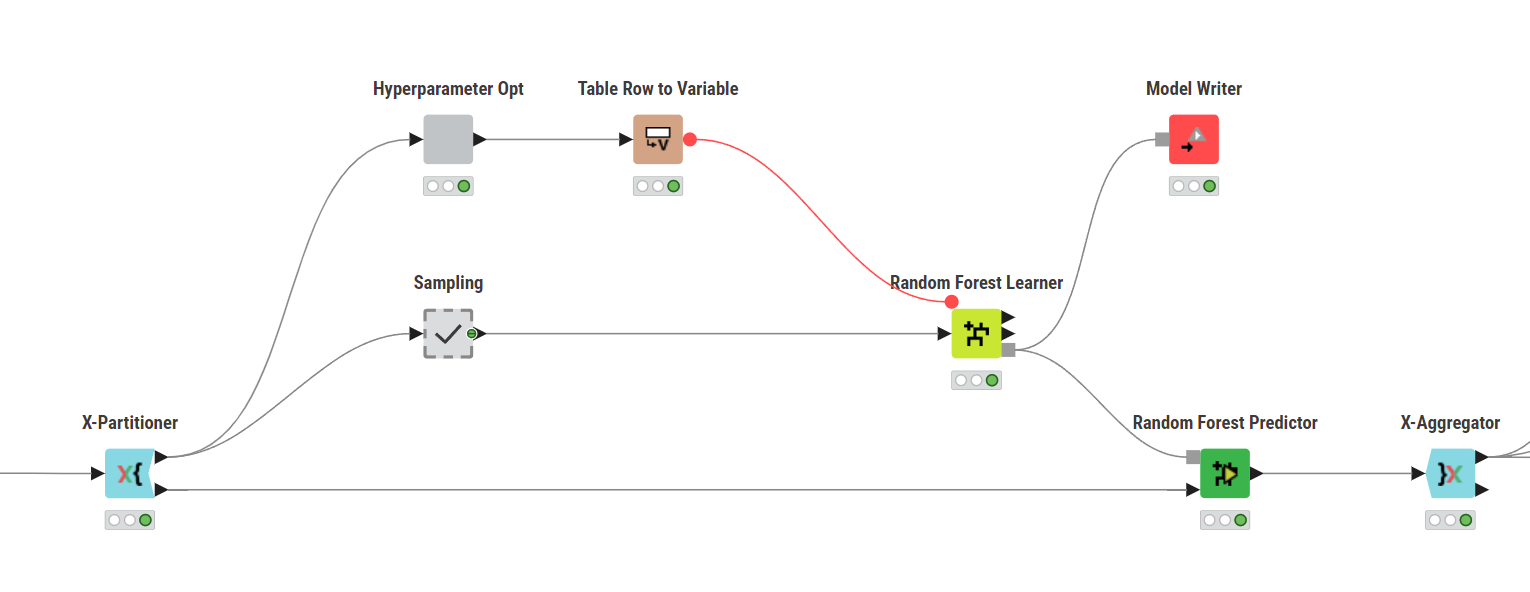
Question for the pros: How great is the risk of data leakage in the setting shown? Or is it sufficient to use different fixed seeds for both X partitioners?
Thanks in advance
Christian
Question for the pros: How great is the risk of data leakage in the setting shown? Or is it sufficient to use different fixed seeds for both X partitioners?
Thanks in advance
Christian
Hi @Christian_Essen,
I think that using two cross-validation loops on the entire dataset risks data leakage. The second round of cross-validation is not a true test, since every row was already used in the first round to tune parameters.
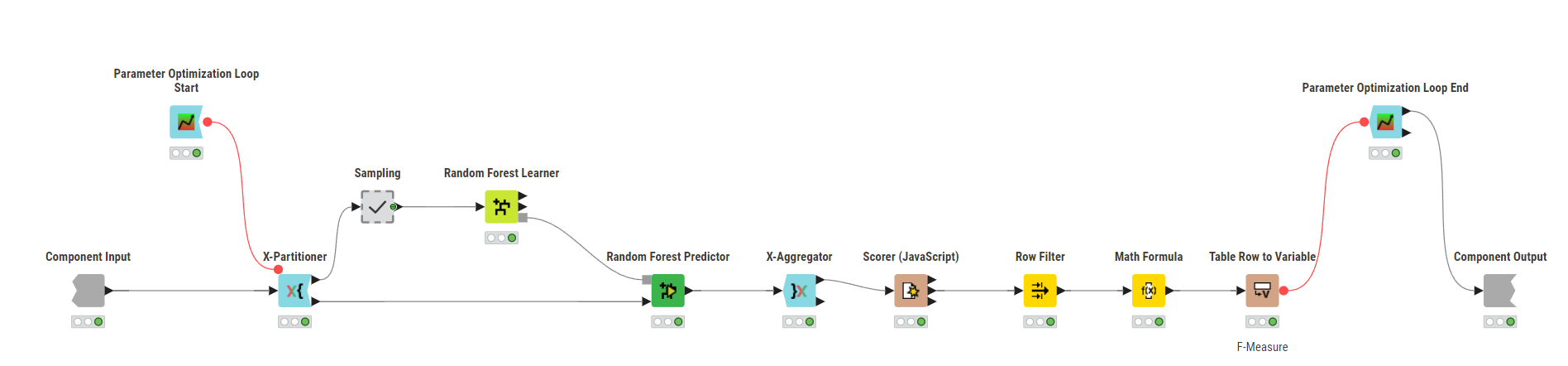
I would suggest the following:
Alternatively, you can use nested CV.
Hope this helps.
Best,
Keerthan
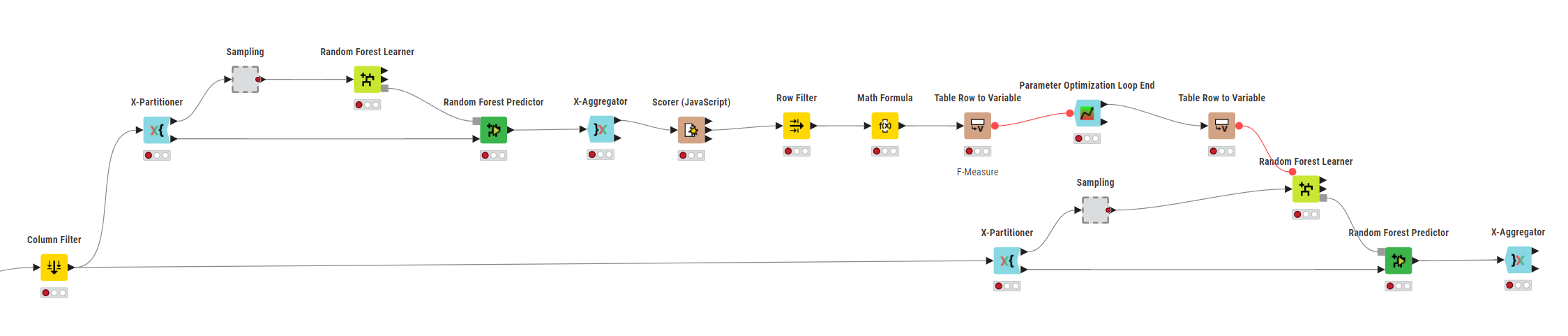
@k10shetty1 : Thank you very much for your support. I’m now doing it with nested cross-validation.
Inside the Component:
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.