We’re trying to read in parquet files with sensor data. It’s a mix of analog readings and true/false values. Each parquet file contains 30,000 rows. It is taking the reader over 3 minutes to read each file. This is a problem because we are receiving new files every minute. Is there a way to speed up the parquet file reading process?
Could you give us more context about the size of the files, the configuration of the machine (RAM, SSD). Are they loaded via a remote connection or a cloud drive.
Our smallest files are 3MB. That takes about 1 minute 20 seconds to read.
28 cores Intel® Xeon® Gold 5120 CPU @ 2.20GHz
512GB of RAM.
Knime version 4.02
Files are coming in over the network, 2 10gbe connections from a NAS that is a few rows away in the DC.
How can I configure the parquet reader to read off my Knime server? I’m using the Analytics platform on my desktop and don’t see an option to point the reader to the Knime server. Whenever I configure the reader it only let’s me pick files on my local desktop.
The Knime server is installed on a Linux OS on bare metal so it has access to all the resources I mentioned above.
28 cores Intel® Xeon® Gold 5120 CPU @ 2.20GHz
512GB of RAM.
My impression was that there were certain challenges with Parquet and KNIME in the past. It would be great if there could be a more stable environment. Since Parquet is also useful as and internal storage format for KNIME.
I would not call it a known issue but there were some reports of problems with parquet and KNIME before and I had some strange issues that I was not able to systematically reproduce.
Also I had the impression that when I used parquet as the internal storage I had problems on my Mac (the Column store approach with Parquet is still marked “experimental”).
Today I had the short impression that one Parquet file I used had misplaced some columns, I had not investigated further since a colleague was able to use it without issue.
Hey @stu_marroquin,
we eager to reproduce an work on this issue.
Could you give me a bit more details about the files, what is the schema of the Parquet file? How man columns do you have, and what type? Or may it even be possible to share the file and reader settings with us? Did you use the default type mapping?
Column headers: timestamp, sensor_name
Columns contain timestamp and sensor reading, either boolean or float.
Each file contains 30,000 and each file can contain from 600 to 2500 columns (possibly more).
File size varies from 3MB to 12MB. Files come in at a rate of 1 file per minute, which is why it’s critical to get the files read in under 30 seconds.
Any help you can provide would be greatly appreciated.
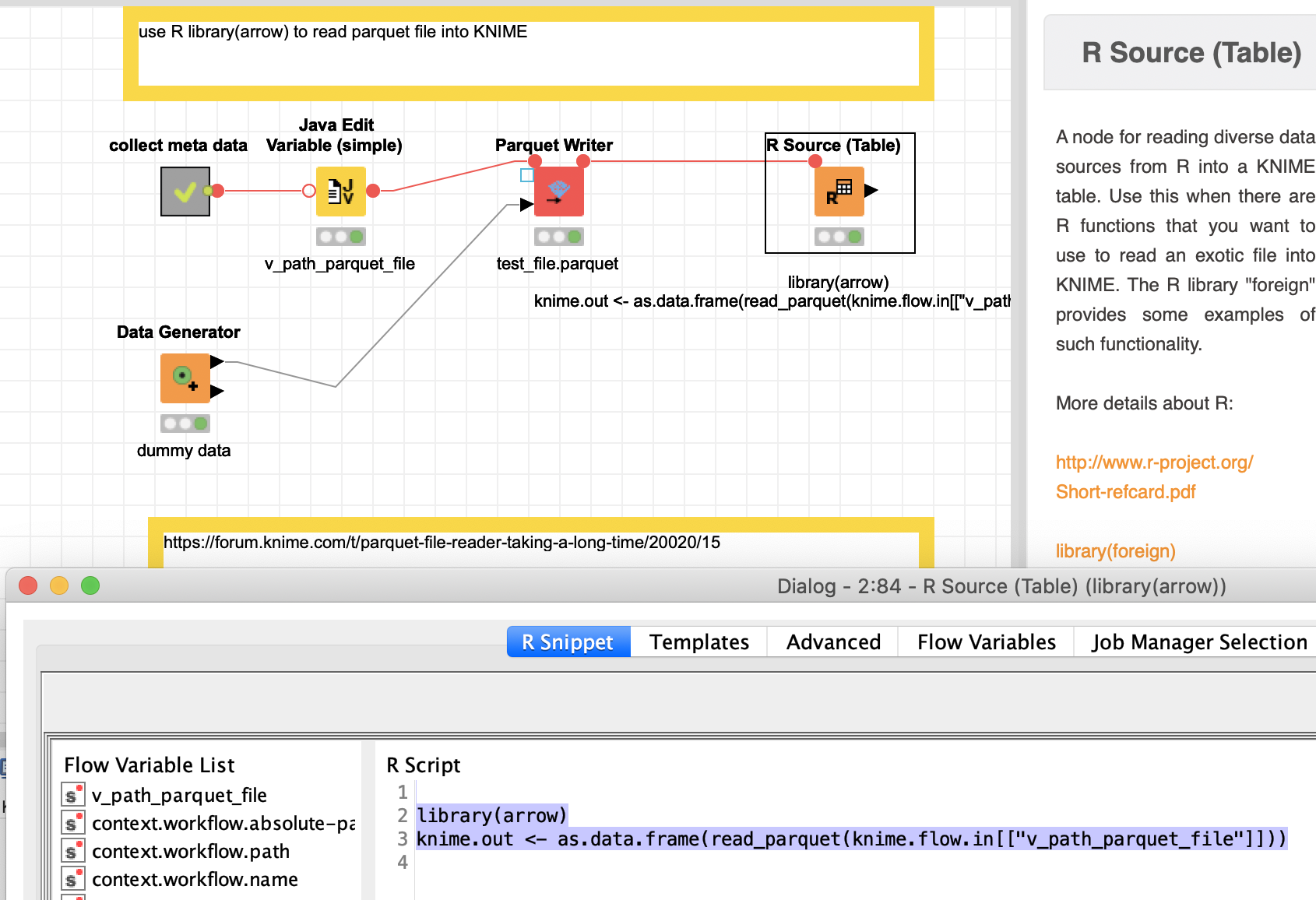
One workaround you could test is to use the R package arrow to import the data first into R and from there to KNIME. I have constructed a small workflow to demonstrate how that could be done.
Hey,
one first step would be to switch to KNIME 4.1 we had some changes regarding the type mapping, that resulted in noticeable performance gains. I tried to build a table similar to your use case:
A 30MB file, 2500 columns 20000 rows.
in 4.0 reading it from local disc took 111121 milliseconds in contrast to 26585 in 4.1 So the first step would be to try 4.1. However this might still not be optimal and I will have a deeper look into the performance issues.
But for now I recommend to try the current KNIME version.
best regards Mareike
Thank you Mareike. I have upgraded to KNIME 4.1. It has improved significantly. I am able to open files in less than a minute now. Obviously the time varies depending on the amount of columns. But the same data in CSV format opens almost instantly.
Thanks,
Stu
I upgraded to the latest version of KNIME analytics platform and performance improved slightly. We’d like to run the entire workflow from the KNIME server, however, we can’t get parquet files to read directly from our KNIME server. Even if we have the workflow on the KNIME server it will still only let us point to our PC’s local drives in the parquet reader configuration. It works fine if we use the regular file reader node, but not the parquet reader. As a result, we’re unable to fully test the performance of our workflow utilizing the KNIME server.
Anyone have any thoughts on this?