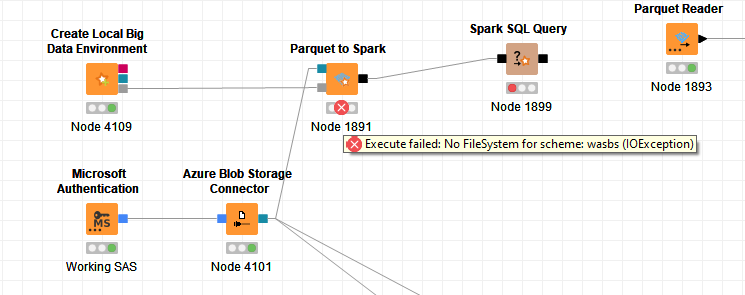
I understand from the other discussion that I have to change some configuration in the “Create Local Big Data Environment” in order to be able to use the Azure File System connection.
Does anybody know what exactly I have to do to make this work?
Thank you very much!
Knime Version 4.3.1 (cannot upgrade currently)
Knime Azure Cloud Connectors 4.3.0
Knime Extension for Apache Spark 4.3.2
Knime Extension for Local Big Data Environments 4.3.1
the Local Big Data Environment contains a reduced Hadoop version that does not support the Azure file systems. You can try to read the file using the normal Parquet reader node and use Table to Spark to get your data into the local Spark instance.
Note that Azure Blob Storage and Azure Data Lake Storage Gen 2 (ADLS2) are behave slightly different and KNIME has two different connectors to solve this.
So just to be sure I understand correctly, it is currently not possible to connect Azure file systems to the local Big Data environment directly, also not with some configuration changes as suggested in Azure and local Spark?
in production, you usually use a real spark cluster and depending on your setup this should work with Azure Blob Storage as your cluster contains the required libs. KNIME exports the selected path as an wasbs://... URL and reads the parquet path in Spark using this URL.
The linked post mentioned that it might be possible to get the Local Big Data Spark working together with the Azure stuff, but this might become tricky and I have tried this. Any reason why you can’t use the normal Parquet reader? As far as I remember, KNIME bundles Hadoop 2.7.6 and you have to add the hadoop-azure jars and all dependencies to the custom spark settings together with your credentials.
We were looking into this topic during some timing tests, comparing local big data environment, Knime Loop with Parquet reader, and Databricks cluster to aggregate multiple parquet files in one go.
If I use the parquet reader, I am converting to Knime and then load back to Spark. Using the “parquet to spark” node, I can directly load into Spark, without the Knime step inbetween.
But I will keep it in mind as a workaround.
Thank you for your input, now we know that the connection from Local Big Data Environment to Azure is currently not possible.