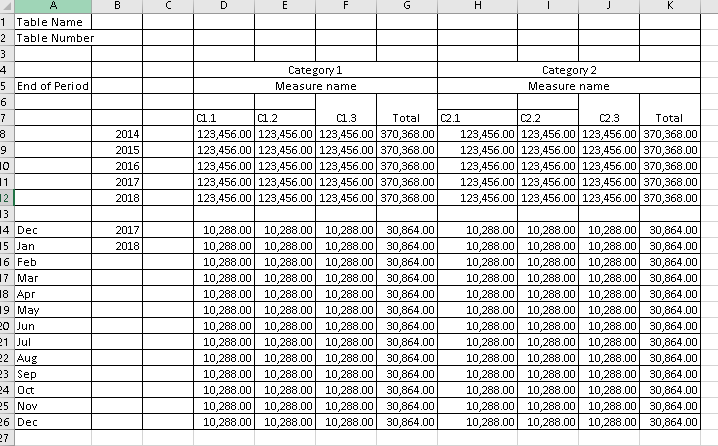
How would you go about a procedure for parsing complicated spreadsheets with nested hierarchies? So I want to build a workflow that would as automatically and universally as possible detect the dimensions and measures of a table like the one below, and turn that into a long table with columns as:
Table Name | Year | Month | Top Category | Sub category | Measure name | Value
As far as I know Excel reader loses information of merged cells, which makes is harder to guess which labels refer to which value columns.
That seems a hard one but who knows, maybe someone does have an idea! If you are able to provide Input Excel file, desired output with values and if necessary logic behind manipulation/transformation of data probability of getting help will increase a lot
As you can see, the workbook contains as many as 38 different publication tables. Quite a few of them follow rather similar layout, but some are significantly different.
I would like to create a workflow with minimal table/submission specific hard-coding and also try avoid building dictionaries of mapping rules as they will be hard to maintain if the layout changes to the next submission. The ideal would naturally be a workflow that automatically connects the right labels to the data and which works with all types of data.
As it is quite easy for a human being to see what goes where it should be possible to start training an algorithm to perform ‘smart data extraction’ from such tables, but that would take even more development effort and a lot of training data!