I want to manipulate a large number of PDB model files (PDB format) but cannot parse any info from the files other than the coordinates. I have tried several PDB readers, (e.g. Vernalis Load Local PDB Files --> PDB Property Extractor) but nothing is parsed. Presumably there is something funky with the file format not being completely PDB adherent.
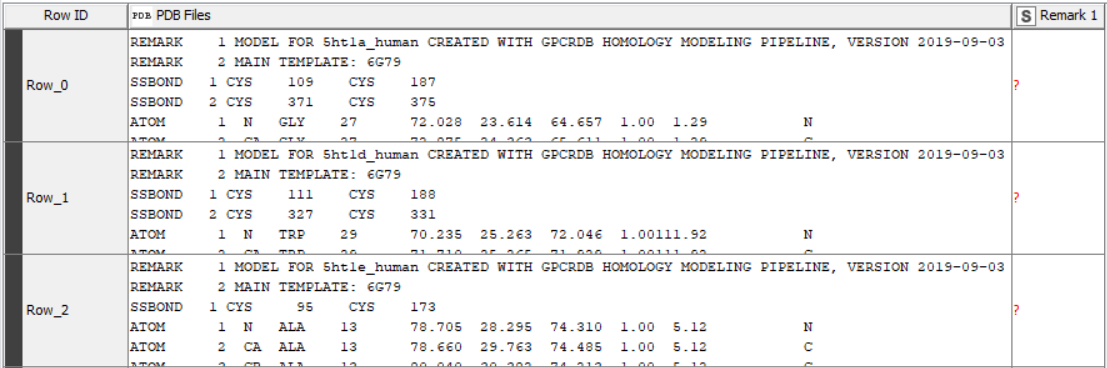
Attached an image of what the cell content looks like. I would like to parse the Remark 1 lines.
The space between ‘REMARK’ and ‘1’ looks bigger than I might expect off the top of my head. Could you copy one of the cells and paste into a text editor and let me know how many spaces there are?
I’ve got a very poor internet connection at the moment and so cant check the format specification or source code, but if you can reply with the answer too the above then I will check once I have my connection back.
I guess the simplest fix is to ‘tweak’ the PDB column you have in a Java Snippet so that it complies with the format specification as shown in the attached example PDB REMARK 1.knwf (18.4 KB) .
One caveat about these nodes is that they take REMARKs 1-3 and extract them as a single line of text, although some of the other outputs are created by a slightly ‘smarter’ handling of those REMARK fields. This is because historically these fields were sometimes used internally for descriptive notes rather than as defined in the file format. If you think an option in each case to retain line-breaks would be useful, then do let me know.