I’m not sure if the stratified sampling in the partitioning node is working. The distribution in the train set is still very imbalanced.
Hello @Ana_Cata23 and welcome to the KNIME Forum,
Could you please give us more context on your thoughts. Do you have any workflows or examples that confirm what you suspect? Thanks for letting us know.
All the best,
Jose.
Hello @Ana_Cata23,
Can you specify your configuration process? You have to select the “string” column that you want to stratify. I just tested it and it works on my mac.
Here is my simple workflow as an example
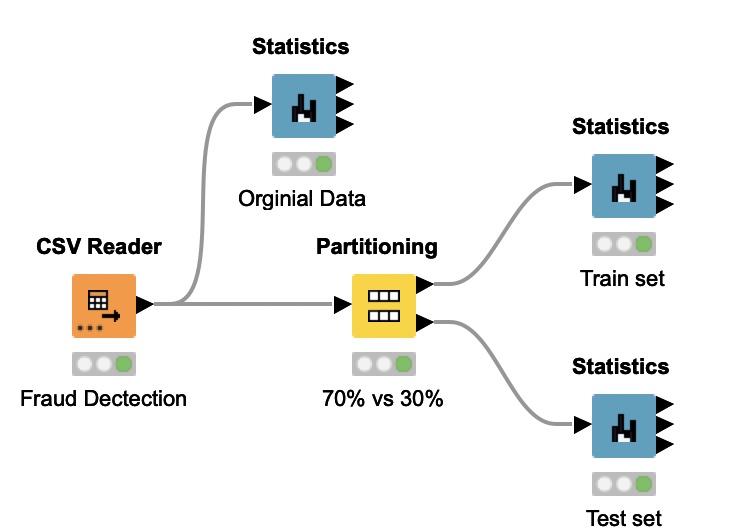
In the original dataset, the target variable is highly imbalanced as shown below.

I wish to use stratified sampling instead of random sampling because “1” in the target variable is a small portion, which might cause all the “1” fall into the train set and only few in the test set. By using the partitioning node, the train set and test set are properly stratified.
Test set

Train set

Please let me know if you still have more issues.
Best Regards
Jinwei
1 Like
Hi @Ana_Cata23
I have never thought about using the Partitioning node to balance classes in a train set. My approach would be to apply Row Sampling to downsample the majority class(es) in a train set, while I’d apply Partitioning to separate the train from the hold-out sets.
However, given the possibility to draw an absolute sample per stratum (as opposed to a relative %), your idea could indeed work, with the string column as stratum as advertised by @jinweisun.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.